In der realen Welt haben nicht alle Daten, mit denen wir arbeiten, eine Zielvariable. Diese Art von Daten können nicht mit überwachten Lernalgorithmen analysiert werden. Wir brauchen die Hilfe unbeaufsichtigter Algorithmen. Eine der beliebtesten Analysearten beim unbeaufsichtigten Lernen ist Kundensegmentierung für gezielte Werbung oder in der medizinischen Bildgebung, um unbekannte oder neue infizierte Bereiche zu finden und viele weitere Anwendungsfälle, die wir in diesem Artikel weiter besprechen werden.
Inhaltsverzeichnis
- Was ist Clustering?
- Arten von Clustering
- Verwendungsmöglichkeiten von Clustering
- Arten von Clustering-Algorithmen
- Anwendungen des Clusterings in verschiedenen Bereichen:
- Häufig gestellte Fragen (FAQs) zum Clustering
Was ist Clustering?
Die Aufgabe, Datenpunkte basierend auf ihrer Ähnlichkeit untereinander zu gruppieren, wird als Clustering oder Clusteranalyse bezeichnet. Diese Methode ist im Zweig von definiert Unbeaufsichtigtes Lernen , das darauf abzielt, Erkenntnisse aus unbeschrifteten Datenpunkten zu gewinnen, also anders überwachtes Lernen Wir haben keine Zielvariable.
Beim Clustering geht es darum, Gruppen homogener Datenpunkte aus einem heterogenen Datensatz zu bilden. Es bewertet die Ähnlichkeit anhand einer Metrik wie der euklidischen Distanz, der Kosinus-Ähnlichkeit, der Manhattan-Distanz usw. und gruppiert dann die Punkte mit der höchsten Ähnlichkeitsbewertung.
In der folgenden Grafik können wir beispielsweise deutlich erkennen, dass sich auf der Grundlage der Entfernung drei kreisförmige Cluster bilden.
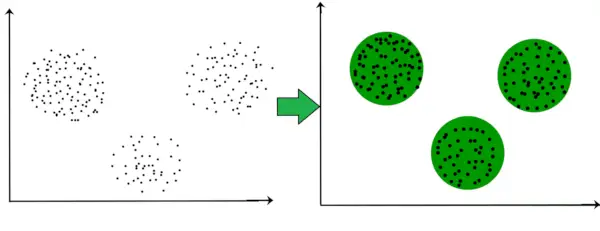
Nun ist es nicht notwendig, dass die gebildeten Cluster eine kreisförmige Form haben. Die Form der Cluster kann beliebig sein. Es gibt viele Algorithmen, die bei der Erkennung beliebig geformter Cluster gut funktionieren.
Wie viele Millionen sind in einer Milliarde?
In der unten angegebenen Grafik können wir beispielsweise sehen, dass die gebildeten Cluster keine kreisförmige Form haben.

Arten von Clustering
Im Großen und Ganzen gibt es zwei Arten von Clustering, die durchgeführt werden können, um ähnliche Datenpunkte zu gruppieren:
- Hartes Clustering: Bei dieser Art des Clusterings gehört jeder Datenpunkt vollständig oder nicht zu einem Cluster. Nehmen wir zum Beispiel an, es gibt 4 Datenpunkte und wir müssen sie in 2 Cluster gruppieren. Jeder Datenpunkt gehört also entweder zu Cluster 1 oder Cluster 2.
| Datenpunkte | Cluster |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Weiches Clustering: Bei dieser Art der Clusterbildung wird nicht jeder Datenpunkt einem separaten Cluster zugeordnet, sondern die Wahrscheinlichkeit oder Wahrscheinlichkeit, dass es sich bei diesem Punkt um diesen Cluster handelt, wird ausgewertet. Nehmen wir zum Beispiel an, es gibt 4 Datenpunkte und wir müssen sie in 2 Cluster gruppieren. Wir werden also die Wahrscheinlichkeit bewerten, dass ein Datenpunkt zu beiden Clustern gehört. Diese Wahrscheinlichkeit wird für alle Datenpunkte berechnet.
| Datenpunkte | Wahrscheinlichkeit von C1 | Wahrscheinlichkeit von C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Verwendungsmöglichkeiten von Clustering
Bevor wir nun mit den Arten von Clustering-Algorithmen beginnen, gehen wir die Anwendungsfälle von Clustering-Algorithmen durch. Clustering-Algorithmen werden hauptsächlich verwendet für:
- Marktsegmentierung – Unternehmen nutzen Clustering, um ihre Kunden zu gruppieren, und nutzen gezielte Werbung, um mehr Publikum anzulocken.
- Analyse sozialer Netzwerke – Social-Media-Seiten nutzen Ihre Daten, um Ihr Surfverhalten zu verstehen und Ihnen gezielte Freundesempfehlungen oder Inhaltsempfehlungen zu geben.
- Medizinische Bildgebung – Ärzte nutzen Clustering, um erkrankte Bereiche in diagnostischen Bildern wie Röntgenaufnahmen zu erkennen.
- Anomalieerkennung – Um Ausreißer in einem Echtzeitdatenstrom zu finden oder betrügerische Transaktionen vorherzusagen, können wir sie mithilfe von Clustering identifizieren.
- Vereinfachen Sie die Arbeit mit großen Datensätzen – Jeder Cluster erhält nach Abschluss des Clusterings eine Cluster-ID. Jetzt können Sie den gesamten Funktionsumfang eines Feature-Sets auf seine Cluster-ID reduzieren. Clustering ist effektiv, wenn es einen komplizierten Fall mit einer einfachen Cluster-ID darstellen kann. Nach dem gleichen Prinzip können durch Clustering von Daten komplexe Datensätze einfacher werden.
Es gibt viele weitere Anwendungsfälle für Clustering, aber es gibt einige der wichtigsten und häufigsten Anwendungsfälle von Clustering. In Zukunft werden wir Clustering-Algorithmen besprechen, die Ihnen bei der Durchführung der oben genannten Aufgaben helfen werden.
Arten von Clustering-Algorithmen
Auf oberflächlicher Ebene hilft Clustering bei der Analyse unstrukturierter Daten. Die grafische Darstellung, der kürzeste Abstand und die Dichte der Datenpunkte sind einige der Elemente, die die Clusterbildung beeinflussen. Beim Clustering wird anhand einer Metrik namens Ähnlichkeitsmaß bestimmt, wie verwandt die Objekte sind. Ähnlichkeitsmetriken sind in kleineren Feature-Sets leichter zu finden. Mit zunehmender Anzahl von Merkmalen wird es schwieriger, Ähnlichkeitsmaße zu erstellen. Abhängig von der Art des Clustering-Algorithmus, der beim Data Mining verwendet wird, werden verschiedene Techniken verwendet, um die Daten aus den Datensätzen zu gruppieren. In diesem Teil werden die Clustering-Techniken beschrieben. Verschiedene Arten von Clustering-Algorithmen sind:
- Centroid-basiertes Clustering (Partitionierungsmethoden)
- Dichtebasiertes Clustering (Modellbasierte Methoden)
- Konnektivitätsbasiertes Clustering (hierarchisches Clustering)
- Verteilungsbasiertes Clustering
Wir werden jeden dieser Typen kurz durchgehen.
1. Partitionierungsmethoden sind die einfachsten Clustering-Algorithmen. Sie gruppieren Datenpunkte auf der Grundlage ihrer Nähe. Als Ähnlichkeitsmaße für diese Algorithmen werden im Allgemeinen die Euklidische Distanz, die Manhattan-Distanz oder die Minkowski-Distanz gewählt. Die Datensätze werden in eine vorgegebene Anzahl von Clustern unterteilt, und auf jeden Cluster wird durch einen Wertevektor verwiesen. Beim Vergleich mit dem Vektorwert zeigt die Eingabedatenvariable keinen Unterschied und schließt sich dem Cluster an.
Der Hauptnachteil dieser Algorithmen besteht darin, dass wir die Anzahl der Cluster k entweder intuitiv oder wissenschaftlich (unter Verwendung der Elbow-Methode) ermitteln müssen, bevor ein Clustering-Machine-Learning-System mit der Zuweisung der Datenpunkte beginnt. Trotzdem ist es immer noch die beliebteste Art des Clusterings. K-bedeutet Und K-Medoide Clustering sind einige Beispiele für diese Art von Clustering.
2. Dichtebasiertes Clustering (Modellbasierte Methoden)
Dichtebasiertes Clustering, eine modellbasierte Methode, findet Gruppen basierend auf der Dichte von Datenpunkten. Im Gegensatz zum Schwerpunkt-basierten Clustering, bei dem die Anzahl der Cluster vordefiniert werden muss und empfindlich auf die Initialisierung reagiert, bestimmt das dichtebasierte Clustering die Anzahl der Cluster automatisch und ist weniger anfällig für Anfangspositionen. Sie eignen sich hervorragend für den Umgang mit Clustern unterschiedlicher Größe und Form und eignen sich daher ideal für Datensätze mit unregelmäßig geformten oder überlappenden Clustern. Diese Methoden verwalten sowohl dichte als auch spärliche Datenbereiche, indem sie sich auf die lokale Dichte konzentrieren, und können Cluster mit einer Vielzahl von Morphologien unterscheiden.
Im Gegensatz dazu ist es bei der zentroidbasierten Gruppierung wie bei k-means schwierig, beliebig geformte Cluster zu finden. Aufgrund der voreingestellten Anzahl von Clusteranforderungen und der extremen Empfindlichkeit gegenüber der anfänglichen Positionierung der Schwerpunkte können die Ergebnisse variieren. Darüber hinaus schränkt die Tendenz zentroidbasierter Ansätze, sphärische oder konvexe Cluster zu erzeugen, ihre Fähigkeit ein, komplizierte oder unregelmäßig geformte Cluster zu verarbeiten. Zusammenfassend lässt sich sagen, dass dichtebasiertes Clustering die Nachteile zentroidbasierter Techniken überwindet, indem es Clustergrößen autonom wählt, widerstandsfähig gegenüber Initialisierung ist und Cluster unterschiedlicher Größe und Form erfolgreich erfasst. Der beliebteste dichtebasierte Clustering-Algorithmus ist DBSCAN .
3. Konnektivitätsbasiertes Clustering (hierarchisches Clustering)
Eine Methode zum Zusammenstellen zusammengehöriger Datenpunkte zu hierarchischen Clustern wird als hierarchisches Clustering bezeichnet. Jeder Datenpunkt wird zunächst als separater Cluster betrachtet, der anschließend mit den ähnlichsten Clustern zu einem großen Cluster zusammengefasst wird, der alle Datenpunkte enthält.
Überlegen Sie, wie Sie eine Sammlung von Gegenständen basierend auf deren Ähnlichkeit anordnen können. Jedes Objekt beginnt als eigener Cluster an der Basis des Baums, wenn hierarchisches Clustering verwendet wird, das ein Dendrogramm, eine baumartige Struktur, erstellt. Die engsten Clusterpaare werden dann zu größeren Clustern zusammengefasst, nachdem der Algorithmus untersucht hat, wie ähnlich die Objekte einander sind. Wenn sich jedes Objekt in einem Cluster oben im Baum befindet, ist der Zusammenführungsprozess abgeschlossen. Das Erkunden verschiedener Granularitätsebenen ist einer der unterhaltsamen Aspekte des hierarchischen Clusterings. Um eine bestimmte Anzahl von Clustern zu erhalten, können Sie diese ausschneiden Dendrogramm in einer bestimmten Höhe. Je ähnlicher zwei Objekte innerhalb eines Clusters sind, desto näher liegen sie beieinander. Dies ist vergleichbar mit der Klassifizierung von Gegenständen nach ihren Stammbäumen, wobei die nächsten Verwandten gruppiert sind und die breiteren Zweige allgemeinere Verbindungen bedeuten. Es gibt zwei Ansätze für hierarchisches Clustering:
- Spaltendes Clustering : Es folgt ein Top-Down-Ansatz. Hier betrachten wir alle Datenpunkte als Teil eines großen Clusters und teilen diesen Cluster dann in kleinere Gruppen auf.
- Agglomeratives Clustering : Es folgt einem Bottom-up-Ansatz. Hier betrachten wir alle Datenpunkte als Teil einzelner Cluster und diese Cluster werden dann zu einem großen Cluster mit allen Datenpunkten zusammengefasst.
4. Verteilungsbasiertes Clustering
Durch verteilungsbasiertes Clustering werden Datenpunkte generiert und entsprechend ihrer Neigung, innerhalb der Daten in dieselbe Wahrscheinlichkeitsverteilung (z. B. eine Gaußsche Verteilung, eine Binomialverteilung oder eine andere) zu fallen, organisiert. Die Datenelemente werden mithilfe einer wahrscheinlichkeitsbasierten Verteilung gruppiert, die auf statistischen Verteilungen basiert. Eingeschlossen sind Datenobjekte, bei denen die Wahrscheinlichkeit höher ist, dass sie im Cluster enthalten sind. Die Wahrscheinlichkeit, dass ein Datenpunkt in einen Cluster aufgenommen wird, ist umso geringer, je weiter er vom zentralen Punkt des Clusters entfernt ist, der in jedem Cluster vorhanden ist.
Ein bemerkenswerter Nachteil von dichte- und grenzenbasierten Ansätzen ist die Notwendigkeit, die Cluster für einige Algorithmen a priori zu spezifizieren, und in erster Linie die Definition der Clusterform für den Großteil der Algorithmen. Es muss mindestens eine Abstimmung oder ein Hyperparameter ausgewählt sein, und obwohl dies einfach sein sollte, könnte ein Fehler unvorhergesehene Auswirkungen haben. Verteilungsbasiertes Clustering hat im Hinblick auf Flexibilität, Genauigkeit und Clusterstruktur einen klaren Vorteil gegenüber Proximity- und Schwerpunkt-basierten Clustering-Ansätzen. Das Kernproblem besteht darin, dies zu vermeiden Überanpassung Viele Clustering-Methoden funktionieren jedoch nur mit simulierten oder hergestellten Daten oder wenn der Großteil der Datenpunkte mit Sicherheit zu einer voreingestellten Verteilung gehört. Der beliebteste verteilungsbasierte Clustering-Algorithmus ist Gaußsches Mischungsmodell .
Anwendungen des Clusterings in verschiedenen Bereichen:
- Marketing: Es kann zur Charakterisierung und Entdeckung von Kundensegmenten für Marketingzwecke verwendet werden.
- Biologie: Es kann zur Klassifizierung verschiedener Pflanzen- und Tierarten verwendet werden.
- Bibliotheken: Es wird verwendet, um verschiedene Bücher nach Themen und Informationen zu gruppieren.
- Versicherung: Es wird verwendet, um die Kunden und ihre Richtlinien zu erkennen und Betrug zu identifizieren.
- Stadtplanung: Es wird verwendet, um Gruppen von Häusern zu bilden und deren Wert anhand ihrer geografischen Lage und anderer vorhandener Faktoren zu untersuchen.
- Erdbebenstudien: Indem wir die vom Erdbeben betroffenen Gebiete kennen, können wir die Gefahrenzonen bestimmen.
- Bildverarbeitung : Clustering kann verwendet werden, um ähnliche Bilder zu gruppieren, Bilder anhand des Inhalts zu klassifizieren und Muster in Bilddaten zu identifizieren.
- Genetik: Durch Clustering werden Gene mit ähnlichen Expressionsmustern gruppiert und Gennetzwerke identifiziert, die in biologischen Prozessen zusammenarbeiten.
- Finanzen: Mithilfe von Clustering werden Marktsegmente anhand des Kundenverhaltens identifiziert, Muster in Börsendaten identifiziert und Risiken in Anlageportfolios analysiert.
- Kundendienst: Durch Clustering werden Kundenanfragen und Beschwerden in Kategorien gruppiert, häufige Probleme identifiziert und gezielte Lösungen entwickelt.
- Herstellung : Clustering wird verwendet, um ähnliche Produkte zu gruppieren, Produktionsprozesse zu optimieren und Fehler in Herstellungsprozessen zu identifizieren.
- Medizinische Diagnose: Clustering wird verwendet, um Patienten mit ähnlichen Symptomen oder Krankheiten zu gruppieren, was dabei hilft, genaue Diagnosen zu stellen und wirksame Behandlungen zu identifizieren.
- Entdeckung eines Betruges: Mithilfe von Clustering werden verdächtige Muster oder Anomalien bei Finanztransaktionen identifiziert, was bei der Aufdeckung von Betrug oder anderen Finanzkriminalität hilfreich sein kann.
- Verkehrsanalyse: Mithilfe von Clustering werden ähnliche Muster von Verkehrsdaten wie Spitzenzeiten, Routen und Geschwindigkeiten gruppiert, was zur Verbesserung der Verkehrsplanung und -infrastruktur beitragen kann.
- Analyse sozialer Netzwerke: Clustering wird verwendet, um Gemeinschaften oder Gruppen innerhalb sozialer Netzwerke zu identifizieren, was dabei helfen kann, soziales Verhalten, Einfluss und Trends zu verstehen.
- Internet-Sicherheit: Clustering wird verwendet, um ähnliche Muster des Netzwerkverkehrs oder Systemverhaltens zu gruppieren, was bei der Erkennung und Verhinderung von Cyberangriffen hilfreich sein kann.
- Klimaanalyse: Mithilfe von Clustering werden ähnliche Muster von Klimadaten wie Temperatur, Niederschlag und Wind gruppiert, was zum Verständnis des Klimawandels und seiner Auswirkungen auf die Umwelt beitragen kann.
- Sportanalyse: Clustering wird verwendet, um ähnliche Muster von Leistungsdaten von Spielern oder Teams zu gruppieren, was bei der Analyse der Stärken und Schwächen von Spielern oder Teams und beim Treffen strategischer Entscheidungen hilfreich sein kann.
- Kriminalitätsanalyse: Clustering wird verwendet, um ähnliche Muster von Kriminalitätsdaten wie Ort, Zeit und Art zu gruppieren. Dies kann dabei helfen, Kriminalitätsschwerpunkte zu identifizieren, zukünftige Kriminalitätstrends vorherzusagen und Strategien zur Kriminalprävention zu verbessern.
Abschluss
In diesem Artikel haben wir Clustering, seine Typen und seine Anwendungen in der realen Welt besprochen. Beim unüberwachten Lernen gibt es noch viel mehr zu beleuchten, und die Clusteranalyse ist nur der erste Schritt. Dieser Artikel kann Ihnen den Einstieg in Clustering-Algorithmen erleichtern und Ihnen dabei helfen, ein neues Projekt zu finden, das Ihrem Portfolio hinzugefügt werden kann.
Häufig gestellte Fragen (FAQs) zum Clustering
F. Was ist die beste Clustering-Methode?
Die Top 10 Clustering-Algorithmen sind:
- K-bedeutet Clustering
- Hierarchisches Clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaußsche Mischungsmodelle (GMM)
- Agglomeratives Clustering
- Spektrale Clusterbildung
- Mean-Shift-Clustering
- Affinitätsausbreitung
- OPTIK (Ordnungspunkte zur Identifizierung der Clusterstruktur)
- Birch (Ausgewogenes iteratives Reduzieren und Clustering mithilfe von Hierarchien)
F. Was ist der Unterschied zwischen Clustering und Klassifizierung?
Der Hauptunterschied zwischen Clustering und Klassifizierung besteht darin, dass es sich bei der Klassifizierung um einen überwachten Lernalgorithmus und bei Clustering um einen unbeaufsichtigten Lernalgorithmus handelt. Das heißt, wir wenden Clustering auf die Datensätze an, die keine Zielvariable haben.
F. Welche Vorteile bietet die Clustering-Analyse?
Mit dem leistungsstarken Analysetool der Clusteranalyse können Daten in aussagekräftige Gruppen organisiert werden. Sie können damit Segmente lokalisieren, versteckte Muster finden und Entscheidungen verbessern.
Finden Sie in String c++
F. Welches ist die schnellste Clustering-Methode?
K-Means-Clustering wird aufgrund seiner Einfachheit und Recheneffizienz oft als die schnellste Clustering-Methode angesehen. Es ordnet Datenpunkte iterativ dem nächstgelegenen Clusterschwerpunkt zu und eignet sich daher für große Datensätze mit geringer Dimensionalität und einer moderaten Anzahl von Clustern.
F. Welche Einschränkungen gibt es beim Clustering?
Zu den Einschränkungen der Clusterbildung gehören die Empfindlichkeit gegenüber Anfangsbedingungen, die Abhängigkeit von der Wahl der Parameter, Schwierigkeiten bei der Bestimmung der optimalen Anzahl von Clustern und Herausforderungen beim Umgang mit hochdimensionalen oder verrauschten Daten.
F. Wovon hängt die Qualität des Clustering-Ergebnisses ab?
Die Qualität der Clustering-Ergebnisse hängt von Faktoren wie der Wahl des Algorithmus, der Distanzmetrik, der Anzahl der Cluster, der Initialisierungsmethode, Datenvorverarbeitungstechniken, Clusterbewertungsmetriken und Domänenkenntnissen ab. Diese Elemente beeinflussen gemeinsam die Wirksamkeit und Genauigkeit des Clustering-Ergebnisses.