In diesem Artikel werden wir den DFS-Algorithmus in der Datenstruktur diskutieren. Es handelt sich um einen rekursiven Algorithmus zum Durchsuchen aller Eckpunkte einer Baumdatenstruktur oder eines Diagramms. Der DFS-Algorithmus (Depth First Search) beginnt mit dem Anfangsknoten von Graph G und geht tiefer, bis wir den Zielknoten oder den Knoten ohne Kinder finden.
Aufgrund der rekursiven Natur kann die Stapeldatenstruktur zur Implementierung des DFS-Algorithmus verwendet werden. Der Prozess der Implementierung des DFS ähnelt dem des BFS-Algorithmus.
Der schrittweise Prozess zur Implementierung der DFS-Durchquerung ist wie folgt dargestellt:
- Erstellen Sie zunächst einen Stapel mit der Gesamtzahl der Eckpunkte im Diagramm.
- Wählen Sie nun einen beliebigen Scheitelpunkt als Startpunkt für die Durchquerung und verschieben Sie diesen Scheitelpunkt in den Stapel.
- Schieben Sie anschließend einen nicht besuchten Scheitelpunkt (neben dem Scheitelpunkt oben im Stapel) an die Spitze des Stapels.
- Wiederholen Sie nun die Schritte 3 und 4, bis vom Scheitelpunkt oben auf dem Stapel aus keine Scheitelpunkte mehr zu erreichen sind.
- Wenn kein Scheitelpunkt übrig ist, gehen Sie zurück und entfernen Sie einen Scheitelpunkt vom Stapel.
- Wiederholen Sie die Schritte 2, 3 und 4, bis der Stapel leer ist.
Anwendungen des DFS-Algorithmus
Die Anwendungen des DFS-Algorithmus sind wie folgt angegeben:
- Der DFS-Algorithmus kann zur Implementierung der topologischen Sortierung verwendet werden.
- Es kann verwendet werden, um die Pfade zwischen zwei Eckpunkten zu finden.
- Es kann auch verwendet werden, um Zyklen im Diagramm zu erkennen.
- Der DFS-Algorithmus wird auch für Ein-Lösungs-Rätsel verwendet.
- DFS wird verwendet, um zu bestimmen, ob ein Graph zweiteilig ist oder nicht.
Algorithmus
Schritt 1: SET STATUS = 1 (Bereitschaftszustand) für jeden Knoten in G
Zusatztasten
Schritt 2: Schieben Sie den Startknoten A auf den Stapel und setzen Sie seinen STATUS = 2 (Wartezustand).
Schritt 3: Wiederholen Sie die Schritte 4 und 5, bis STACK leer ist
Schritt 4: Öffnen Sie den obersten Knoten N. Verarbeiten Sie ihn und setzen Sie seinen STATUS = 3 (verarbeiteter Status).
Schritt 5: Schieben Sie alle Nachbarn von N, die sich im Bereitschaftszustand befinden (deren STATUS = 1 ist), auf den Stapel und setzen Sie ihren STATUS = 2 (Wartezustand).
[ENDE DER SCHLEIFE]
Unterschied zwischen zwei Strings Python
Schritt 6: AUSFAHRT
Polymorphismus Java
Pseudocode
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Beispiel eines DFS-Algorithmus
Lassen Sie uns nun die Funktionsweise des DFS-Algorithmus anhand eines Beispiels verstehen. Im folgenden Beispiel gibt es einen gerichteten Graphen mit 7 Eckpunkten.
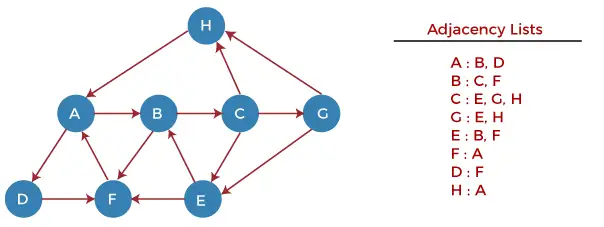
Beginnen wir nun mit der Untersuchung des Diagramms beginnend mit Knoten H.
Schritt 1 - Schieben Sie zunächst H auf den Stapel.
STACK: H
Schritt 2 - POP das oberste Element vom Stapel, d. h. H, und drucke es aus. Schieben Sie nun alle Nachbarn von H auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: H]STACK: A
Schritt 3 - POP das oberste Element vom Stapel, d. h. A, und drucke es aus. Schieben Sie nun alle Nachbarn von A auf den Stapel, die sich im Bereitschaftszustand befinden.
Websites wie coomeet
Print: A STACK: B, D
Schritt 4 - POP das oberste Element vom Stapel, d. h. D, und drucke es aus. Schieben Sie nun alle Nachbarn von D auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: D STACK: B, F
Schritt 5 - POP das oberste Element vom Stapel, d. h. F, und drucke es aus. Schieben Sie nun alle Nachbarn von F auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: F STACK: B
Schritt 6 - POP das oberste Element vom Stapel, d. h. B, und drucke es aus. Schieben Sie nun alle Nachbarn von B auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: B STACK: C
Schritt 7 - POP das oberste Element vom Stapel, d. h. C, und drucke es aus. Jetzt PUSH alle Nachbarn von C auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: C STACK: E, G
Schritt 8 - POP das oberste Element vom Stapel, d. h. G, und PUSH alle Nachbarn von G auf den Stapel, die sich im Bereitschaftszustand befinden.
Schriftgrößen in Latex
Print: G STACK: E
Schritt 9 - POP das oberste Element vom Stapel, d. h. E, und PUSH alle Nachbarn von E auf den Stapel, die sich im Bereitschaftszustand befinden.
Print: E STACK:
Jetzt wurden alle Diagrammknoten durchlaufen und der Stapel ist leer.
Komplexität des Tiefensuchalgorithmus
Die zeitliche Komplexität des DFS-Algorithmus beträgt O(V+E) , wobei V die Anzahl der Eckpunkte und E die Anzahl der Kanten im Diagramm ist.
Die räumliche Komplexität des DFS-Algorithmus beträgt O(V).
Implementierung des DFS-Algorithmus
Sehen wir uns nun die Implementierung des DFS-Algorithmus in Java an.
In diesem Beispiel sieht das Diagramm, das wir zur Veranschaulichung des Codes verwenden, wie folgt aus:

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>