Einführung:
URL-Shortener sind ein Beispiel für Hashing, da sie große URLs kleinen URLs zuordnen
Einige Beispiele für Hash-Funktionen:
- Schlüssel % Anzahl der Buckets
- ASCII-Wert des Zeichens * PrimeNumberX. Wobei x = 1, 2, 3….n
- Sie können Ihre eigene Hash-Funktion erstellen, aber es sollte eine gute Hash-Funktion sein, die weniger Kollisionen verursacht.
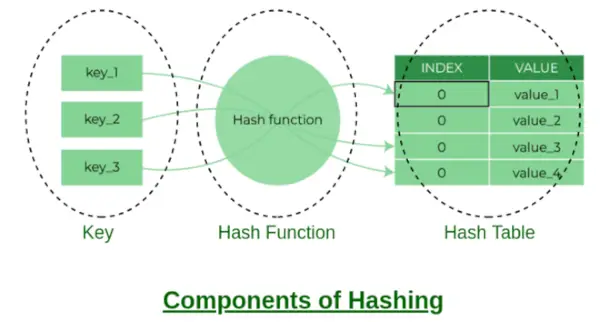
Komponenten des Hashings
Bucket-Index:
Der von der Hash-Funktion zurückgegebene Wert ist der Bucket-Index für einen Schlüssel in einer separaten Verkettungsmethode. Jeder Index im Array wird als Bucket bezeichnet, da es sich um einen Bucket einer verknüpften Liste handelt.
Aufwärmen:
Rehashing ist ein Konzept, das Kollisionen reduziert, wenn die Elemente in der aktuellen Hash-Tabelle erhöht werden. Es wird ein neues Array mit doppelter Größe erstellt und die vorherigen Array-Elemente dorthin kopiert. Dies ähnelt der internen Funktionsweise von Vektoren in C++. Offensichtlich sollte die Hash-Funktion dynamisch sein, da sie einige Änderungen widerspiegeln sollte, wenn die Kapazität erhöht wird. Die Hash-Funktion berücksichtigt die Kapazität der Hash-Tabelle. Daher liefert die Hash-Funktion beim Kopieren von Schlüsselwerten aus dem vorherigen Array unterschiedliche Bucket-Indizes, da dies von der Kapazität (Buckets) der Hash-Tabelle abhängt. Im Allgemeinen werden Wiederaufwärmvorgänge durchgeführt, wenn der Wert des Lastfaktors größer als 0,5 ist.
- Verdoppeln Sie die Größe des Arrays.
- Kopieren Sie die Elemente des vorherigen Arrays in das neue Array. Wir verwenden die Hash-Funktion, während wir jeden Knoten erneut in ein neues Array kopieren. Dadurch werden Kollisionen reduziert.
- Löschen Sie das vorherige Array aus dem Speicher und richten Sie den internen Array-Zeiger Ihrer Hash-Map auf dieses neue Array.
- Im Allgemeinen ist der Ladefaktor = Anzahl der Elemente in der Hash-Map / Gesamtzahl der Buckets (Kapazität).
Kollision:
Eine Kollision ist die Situation, in der der Bucket-Index nicht leer ist. Dies bedeutet, dass an diesem Bucket-Index ein Kopf einer verknüpften Liste vorhanden ist. Wir haben zwei oder mehr Werte, die demselben Bucket-Index zugeordnet sind.
Hauptfunktionen in unserem Programm
- Einfügen
- Suchen
- Hash-Funktion
- Löschen
- Aufwärmen
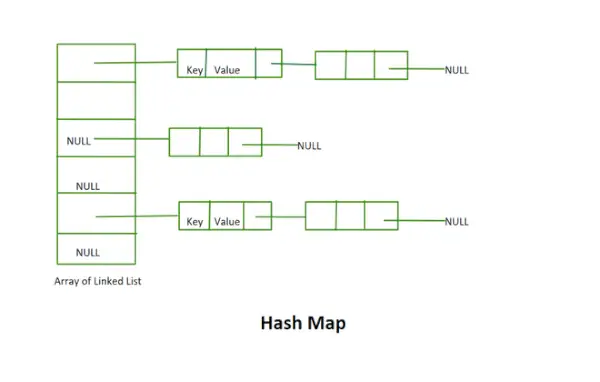
Hash-Karte
Implementierung ohne Rehashing:
C
Java enthält Teilzeichenfolge
#include> #include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value)> {> >node->key = key;> >node->Wert = Wert;> >node->next = NULL;> >return>;> };> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp)> {> >// Default capacity in this case> >mp->Kapazität = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*)> >* mp->Kapazität);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key)> {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->Kapazität)> >+ (((>int>)key[i]) * factor) % mp->Kapazität)> >% mp->Kapazität;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__)> >* (31 % __INT16_MAX__))> >% __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value)> {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> delete> (>struct> hashMap* mp,>char>* key)> {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->Schlüssel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->next;> >}> >free>(currNode);> >break>;> >}> >prevNode = currNode;> >currNode = currNode->weiter;> >}> >return>;> }> char>* search(>struct> hashMap* mp,>char>* key)> {> >// Getting the bucket index> >// for the given key> >int> bucketIndex = hashFunction(mp, key);> >// Head of the linked list> >// present at bucket index> >struct> node* bucketHead = mp->arr[bucketIndex];> >while> (bucketHead != NULL) {> >// Key is found in the hashMap> >if> (bucketHead->key == key) {> >return> bucketHead->Wert;> >}> >bucketHead = bucketHead->weiter;> >}> >// If no key found in the hashMap> >// equal to the given key> >char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> >errorMssg =>'Oops! No data found.
'>;> >return> errorMssg;> }> // Drivers code> int> main()> {> >// Initialize the value of mp> >struct> hashMap* mp> >= (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> >initializeHashMap(mp);> >insert(mp,>'Yogaholic'>,>'Anjali'>);> >insert(mp,>'pluto14'>,>'Vartika'>);> >insert(mp,>'elite_Programmer'>,>'Manish'>);> >insert(mp,>'GFG'>,>'techcodeview.com'>);> >insert(mp,>'decentBoy'>,>'Mayank'>);> >printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> >printf>(>'%s
'>, search(mp,>'Yogaholic'>));> >printf>(>'%s
'>, search(mp,>'pluto14'>));> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >printf>(>'%s
'>, search(mp,>'GFG'>));> >// Key is not inserted> >printf>(>'%s
'>, search(mp,>'randomKey'>));> >printf>(>'
After deletion :
'>);> >// Deletion of key> >delete> (mp,>'decentBoy'>);> >printf>(>'%s
'>, search(mp,>'decentBoy'>));> >return> 0;> }> |
>
>
C++
#include> #include> // Linked List node> struct> node {> >// key is string> >char>* key;> >// value is also string> >char>* value;> >struct> node* next;> };> // like constructor> void> setNode(>struct> node* node,>char>* key,>char>* value) {> >node->key = key;> >node->Wert = Wert;> >node->next = NULL;> >return>;> }> struct> hashMap {> >// Current number of elements in hashMap> >// and capacity of hashMap> >int> numOfElements, capacity;> >// hold base address array of linked list> >struct> node** arr;> };> // like constructor> void> initializeHashMap(>struct> hashMap* mp) {> >// Default capacity in this case> >mp->Kapazität = 100;> >mp->numOfElements = 0;> >// array of size = 1> >mp->arr = (>struct> node**)>malloc>(>sizeof>(>struct> node*) * mp->Kapazität);> >return>;> }> int> hashFunction(>struct> hashMap* mp,>char>* key) {> >int> bucketIndex;> >int> sum = 0, factor = 31;> >for> (>int> i = 0; i <>strlen>(key); i++) {> >// sum = sum + (ascii value of> >// char * (primeNumber ^ x))...> >// where x = 1, 2, 3....n> >sum = ((sum % mp->Kapazität) + (((>int>)key[i]) * factor) % mp->Kapazität) % mp->capacity;> >// factor = factor * prime> >// number....(prime> >// number) ^ x> >factor = ((factor % __INT16_MAX__) * (31 % __INT16_MAX__)) % __INT16_MAX__;> >}> >bucketIndex = sum;> >return> bucketIndex;> }> void> insert(>struct> hashMap* mp,>char>* key,>char>* value) {> >// Getting bucket index for the given> >// key - value pair> >int> bucketIndex = hashFunction(mp, key);> >struct> node* newNode = (>struct> node*)>malloc>(> >// Creating a new node> >sizeof>(>struct> node));> >// Setting value of node> >setNode(newNode, key, value);> >// Bucket index is empty....no collision> >if> (mp->arr[bucketIndex] == NULL) {> >mp->arr[bucketIndex] = newNode;> >}> >// Collision> >else> {> >// Adding newNode at the head of> >// linked list which is present> >// at bucket index....insertion at> >// head in linked list> >newNode->next = mp->arr[bucketIndex];> >mp->arr[bucketIndex] = newNode;> >}> >return>;> }> void> deleteKey(>struct> hashMap* mp,>char>* key) {> >// Getting bucket index for the> >// given key> >int> bucketIndex = hashFunction(mp, key);> >struct> node* prevNode = NULL;> >// Points to the head of> >// linked list present at> >// bucket index> >struct> node* currNode = mp->arr[bucketIndex];> >while> (currNode != NULL) {> >// Key is matched at delete this> >// node from linked list> >if> (>strcmp>(key, currNode->Schlüssel) == 0) {> >// Head node> >// deletion> >if> (currNode == mp->arr[bucketIndex]) {> >mp->arr[bucketIndex] = currNode->next;> >}> >// Last node or middle node> >else> {> >prevNode->next = currNode->next;> }> free>(currNode);> break>;> }> prevNode = currNode;> >currNode = currNode->weiter;> >}> return>;> }> char>* search(>struct> hashMap* mp,>char>* key) {> // Getting the bucket index for the given key> int> bucketIndex = hashFunction(mp, key);> // Head of the linked list present at bucket index> struct> node* bucketHead = mp->arr[bucketIndex];> while> (bucketHead != NULL) {> > >// Key is found in the hashMap> >if> (>strcmp>(bucketHead->Schlüssel, Schlüssel) == 0) {> >return> bucketHead->Wert;> >}> > >bucketHead = bucketHead->weiter;> }> // If no key found in the hashMap equal to the given key> char>* errorMssg = (>char>*)>malloc>(>sizeof>(>char>) * 25);> strcpy>(errorMssg,>'Oops! No data found.
'>);> return> errorMssg;> }> // Drivers code> int> main()> {> // Initialize the value of mp> struct> hashMap* mp = (>struct> hashMap*)>malloc>(>sizeof>(>struct> hashMap));> initializeHashMap(mp);> insert(mp,>'Yogaholic'>,>'Anjali'>);> insert(mp,>'pluto14'>,>'Vartika'>);> insert(mp,>'elite_Programmer'>,>'Manish'>);> insert(mp,>'GFG'>,>'techcodeview.com'>);> insert(mp,>'decentBoy'>,>'Mayank'>);> printf>(>'%s
'>, search(mp,>'elite_Programmer'>));> printf>(>'%s
'>, search(mp,>'Yogaholic'>));> printf>(>'%s
'>, search(mp,>'pluto14'>));> printf>(>'%s
'>, search(mp,>'decentBoy'>));> printf>(>'%s
'>, search(mp,>'GFG'>));> // Key is not inserted> printf>(>'%s
'>, search(mp,>'randomKey'>));> printf>(>'
After deletion :
'>);> // Deletion of key> deleteKey(mp,>'decentBoy'>);> // Searching the deleted key> printf>(>'%s
'>, search(mp,>'decentBoy'>));> return> 0;> }> |
>
>Ausgabe
Manish Anjali Vartika Mayank techcodeview.com Oops! No data found. After deletion : Oops! No data found.>
Erläuterung:
- Einfügung: Fügt das Schlüssel-Wert-Paar am Kopf einer verknüpften Liste ein, die am angegebenen Bucket-Index vorhanden ist. hashFunction: Gibt den Bucket-Index für den angegebenen Schlüssel an. Unser Hash-Funktion = ASCII-Wert des Zeichens * primeNumberX . Die Primzahl ist in unserem Fall 31 und der Wert von x steigt für aufeinanderfolgende Zeichen in einem Schlüssel von 1 auf n. Löschung: Löscht das Schlüssel-Wert-Paar aus der Hash-Tabelle für den angegebenen Schlüssel. Es löscht den Knoten aus der verknüpften Liste, der das Schlüssel-Wert-Paar enthält. Suchen: Suchen Sie nach dem Wert des angegebenen Schlüssels.
- Diese Implementierung verwendet nicht das Rehashing-Konzept. Es handelt sich um ein Array verknüpfter Listen fester Größe.
- Schlüssel und Wert sind im gegebenen Beispiel beide Zeichenfolgen.
Zeitkomplexität und Raumkomplexität:
Die zeitliche Komplexität von Hash-Tabellen-Einfüge- und Löschvorgängen beträgt im Durchschnitt O(1). Es gibt eine mathematische Berechnung, die das beweist.
- Zeitkomplexität der Einfügung: Im Durchschnitt ist sie konstant. Im schlimmsten Fall ist es linear. Zeitkomplexität der Suche: Im Durchschnitt ist sie konstant. Im schlimmsten Fall ist es linear. Zeitkomplexität der Löschung: Im Durchschnitt ist sie konstant. Im schlimmsten Fall ist es linear. Raumkomplexität: O(n), da es n Elemente hat.
In Verbindung stehende Artikel:
- Separate Technik zur Behandlung von Verkettungskollisionen beim Hashing.