Im vorherigen Abschnitt haben wir eine kurze Einführung in Apache Kafka, das Nachrichtensystem und den Streaming-Prozess gegeben. Hier werden wir die Grundkonzepte und die Rolle von Kafka diskutieren.
Themen
Im Allgemeinen bezieht sich ein Thema auf eine bestimmte Überschrift oder einen Namen für bestimmte, miteinander verbundene Ideen. In Kafka bezieht sich das Wort „Thema“ auf eine Kategorie oder einen gebräuchlichen Namen, der zum Speichern und Veröffentlichen eines bestimmten Datenstroms verwendet wird. Grundsätzlich ähneln Themen in Kafka den Tabellen in der Datenbank, enthalten jedoch nicht alle Einschränkungen. In Kafka können wir beliebig viele Themen erstellen. Die Identifizierung erfolgt über seinen Namen, der von der Wahl des Benutzers abhängt. Ein Produzent veröffentlicht Daten zu den Themen, und ein Verbraucher liest diese Daten aus dem Thema, indem er sie abonniert.
Partitionen
Ein Thema ist in mehrere Teile unterteilt, die als Partitionen des Themas bezeichnet werden. Diese Partitionen sind in einer Reihenfolge getrennt. Der Dateninhalt wird in den Partitionen innerhalb des Themas gespeichert. Daher müssen wir beim Erstellen eines Themas die Anzahl der Partitionen angeben (die Anzahl ist willkürlich und kann später geändert werden). Jede Nachricht wird in Partitionen mit einer inkrementellen ID gespeichert, die als Offset-Wert bezeichnet wird. Die Reihenfolge der Offsetwert ist nur innerhalb der Partition und nicht über die gesamte Partition hinweg gewährleistet. Die Offsets für eine Partition sind unendlich.
Notiz:Die einmal auf eine Partition geschriebenen Daten können niemals geändert werden. Es ist unveränderlich. Der Offset-Wert bleibt immer in einem inkrementellen Zustand und geht nie auf eine leere Stelle zurück. Außerdem werden die Daten nur für eine begrenzte Zeit in einer Partition gespeichert.
Sehen wir uns ein Beispiel an, um ein Thema mit seinen Partitionen zu verstehen.
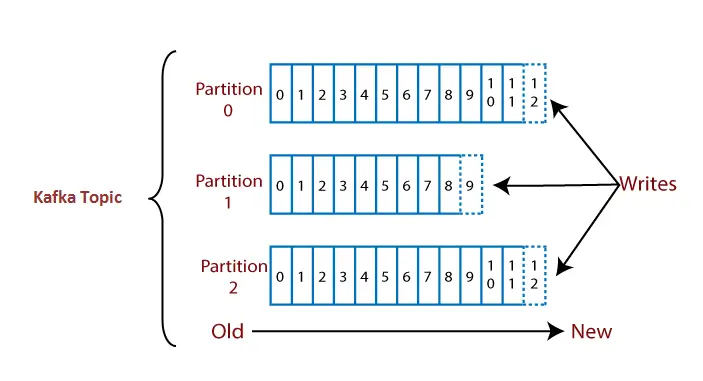
Angenommen, ein Thema enthält drei Partitionen 0,1 und 2. Jede Partition hat unterschiedliche Offset-Nummern. Die Daten werden auf jeden Offset in jeder Partition verteilt, wobei die Daten in Offset 1 von Partition 0 keine Beziehung zu den Daten in Offset 1 von Partition1 haben. Die Daten im Offset 1 von Partition 0 stehen jedoch in Wechselbeziehung zu den Daten im Offset 2 von Partition 0.
Makler
Hier kommt die Rolle von Apache Kafka ins Spiel.
Ein Kafka-Cluster besteht aus einem oder mehreren Servern, die als Broker oder Kafka-Broker bezeichnet werden. Ein Broker ist ein Container, der mehrere Themen mit ihren mehreren Partitionen enthält. Die Broker im Cluster werden nur durch eine ganzzahlige ID identifiziert. Kafka-Broker werden auch als Kafka-Broker bezeichnet Bootstrap-Broker denn die Verbindung mit einem beliebigen Broker bedeutet eine Verbindung mit dem gesamten Cluster. Obwohl ein Broker keine vollständigen Daten enthält, kennt jeder Broker im Cluster alle anderen Broker, Partitionen und Themen.

So sieht ein Broker in der Abbildung aus, der ein Thema mit n Partitionen enthält.
Beispiel: Broker und Themen
Angenommen, ein Kafka-Cluster besteht aus drei Brokern, nämlich Broker 1, Broker 2 und Broker 3.

Jeder Broker hält ein Thema, nämlich Topic-x mit drei Partitionen 0,1 und 2. Denken Sie daran, dass alle Partitionen nicht nur einem Broker gehören, sondern immer auf jeden Broker verteilt sind (abhängig von der Menge). Broker 1 und Broker 2 enthalten ein weiteres Topic-y mit den beiden Partitionen 0 und 1. Daher enthält Broker 3 keine Daten von Topic-y. Es wird außerdem der Schluss gezogen, dass zwischen der Brokernummer und der Partitionsnummer niemals eine Beziehung besteht.