Das Schlüsselwort IDENTITY ist eine Eigenschaft in SQL Server. Wenn eine Tabellenspalte mit einer Identitätseigenschaft definiert wird, ist ihr Wert ein automatisch generierter inkrementeller Wert . Dieser Wert wird vom Server automatisch erstellt. Daher können wir als Benutzer keinen Wert manuell in eine Identitätsspalte eingeben. Wenn wir also eine Spalte als Identität markieren, füllt SQL Server sie automatisch inkrementell auf.
Syntax
Im Folgenden finden Sie die Syntax zur Veranschaulichung der Verwendung der IDENTITY-Eigenschaft in SQL Server:
IDENTITY[(seed, increment)]
Die oben genannten Syntaxparameter werden im Folgenden erläutert:
Lassen Sie uns dieses Konzept anhand eines einfachen Beispiels verstehen.
Angenommen, wir haben ein „ Student ' Tisch, und wir wollen Studenten ID automatisch generiert werden. Wir haben ein Studienanfängerausweis von 10 und möchte diese mit jeder neuen ID um 1 erhöhen. In diesem Szenario müssen die folgenden Werte definiert werden.
Samen: 10
Zuwachs: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
HINWEIS: In SQL Server ist pro Tabelle nur eine Identifizierungsspalte zulässig.
Beispiel für SQL Server IDENTITY
Lassen Sie uns verstehen, wie wir die Identitätseigenschaft in der Tabelle verwenden können. Die Identitätseigenschaft in einer Spalte kann entweder beim Erstellen der neuen Tabelle oder nach deren Erstellung festgelegt werden. Hier werden wir beide Fälle anhand von Beispielen sehen.
IDENTITY-Eigenschaft mit neuer Tabelle
Die folgende Anweisung erstellt eine neue Tabelle mit der Identitätseigenschaft in der angegebenen Datenbank:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Als nächstes fügen wir eine neue Zeile mit ein in diese Tabelle ein AUSGABE -Klausel, um die automatisch generierte Personen-ID anzuzeigen:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Wenn Sie diese Abfrage ausführen, wird die folgende Ausgabe angezeigt:
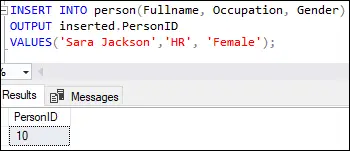
Diese Ausgabe zeigt, dass die erste Zeile mit dem Wert zehn in die eingefügt wurde Personen-ID Spalte wie in der Tabellendefinitions-Identitätsspalte angegeben.
Fügen wir eine weitere Zeile in die ein Personentisch wie nachstehend:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Diese Abfrage gibt die folgende Ausgabe zurück:

Diese Ausgabe zeigt, dass in der Spalte PersonID die zweite Zeile mit dem Wert 11 und die dritte Zeile mit dem Wert 12 eingefügt wurde.
IDENTITY-Eigenschaft mit vorhandener Tabelle
Wir erklären dieses Konzept, indem wir zunächst die obige Tabelle löschen und sie ohne Identitätseigenschaft erstellen. Führen Sie die folgende Anweisung aus, um die Tabelle zu löschen:
DROP TABLE person;
Als Nächstes erstellen wir eine Tabelle mit der folgenden Abfrage:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Wenn wir eine neue Spalte mit der Identitätseigenschaft in einer vorhandenen Tabelle hinzufügen möchten, müssen wir den Befehl ALTER verwenden. Die folgende Abfrage fügt die PersonID als Identitätsspalte in der Personentabelle hinzu:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Explizites Hinzufügen von Werten zur Identitätsspalte
Wenn wir der obigen Tabelle eine neue Zeile hinzufügen, indem wir explizit den Wert der Identitätsspalte angeben, gibt SQL Server einen Fehler aus. Siehe die folgende Abfrage:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Beim Ausführen dieser Abfrage wird der folgende Fehler angezeigt:

Um den Identitätsspaltenwert explizit einzufügen, müssen wir zunächst den IDENTITY_INSERT-Wert auf ON setzen. Führen Sie als Nächstes den Einfügevorgang aus, um der Tabelle eine neue Zeile hinzuzufügen, und legen Sie dann den IDENTITY_INSERT-Wert auf OFF fest. Sehen Sie sich das folgende Codeskript an:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT EIN ermöglicht Benutzern das Einfügen von Daten in Identitätsspalten IDENTITY_INSERT AUS verhindert, dass sie dieser Spalte einen Mehrwert verleihen.
Wenn Sie das Codeskript ausführen, wird die folgende Ausgabe angezeigt, in der wir sehen können, dass die PersonID mit dem Wert 14 erfolgreich eingefügt wurde.

IDENTITY-Funktion
SQL Server bietet einige Identitätsfunktionen für die Arbeit mit den IDENTITY-Spalten in einer Tabelle. Diese Identitätsfunktionen sind unten aufgeführt:
- @@IDENTITY-Funktion
- SCOPE_IDENTITY() Funktion
- IDENT_CURRENT-Funktion
- IDENTITY-Funktion
Schauen wir uns die IDENTITY-Funktionen anhand einiger Beispiele an.
@@IDENTITY-Funktion
Die @@IDENTITY ist eine systemdefinierte Funktion, die Zeigt den letzten Identitätswert an (maximal verwendeter Identitätswert), der in derselben Sitzung in einer Tabelle für die IDENTITY-Spalte erstellt wurde. Diese Funktionsspalte gibt den Identitätswert zurück, der von der Anweisung nach dem Einfügen eines neuen Eintrags in eine Tabelle generiert wird. Es gibt a zurück NULL Wert, wenn wir eine Abfrage ausführen, die keine IDENTITY-Werte erstellt. Es funktioniert immer im Rahmen der aktuellen Sitzung. Es kann nicht aus der Ferne verwendet werden.
Beispiel
Angenommen, der aktuelle maximale Identitätswert in der Personentabelle beträgt 13. Jetzt fügen wir in derselben Sitzung einen Datensatz hinzu, der den Identitätswert um eins erhöht. Dann verwenden wir die Funktion @@IDENTITY, um den letzten in derselben Sitzung erstellten Identitätswert abzurufen.
Hier ist das vollständige Codeskript:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Wenn Sie das Skript ausführen, wird die folgende Ausgabe zurückgegeben, in der wir sehen können, dass der maximal verwendete Identitätswert 14 beträgt.

SCOPE_IDENTITY() Funktion
SCOPE_IDENTITY() ist eine systemdefinierte Funktion für Zeigt den aktuellsten Identitätswert an in einer Tabelle unter dem aktuellen Geltungsbereich. Dieser Bereich kann ein Modul, ein Trigger, eine Funktion oder eine gespeicherte Prozedur sein. Sie ähnelt der Funktion @@IDENTITY(), außer dass diese Funktion nur einen begrenzten Umfang hat. Die SCOPE_IDENTITY-Funktion gibt NULL zurück, wenn wir sie vor der Einfügeoperation ausführen, die einen Wert im gleichen Bereich generiert.
Beispiel
Der folgende Code verwendet sowohl die Funktion @@IDENTITY als auch die Funktion SCOPE_IDENTITY() in derselben Sitzung. In diesem Beispiel wird zunächst der letzte Identitätswert angezeigt und dann eine Zeile in die Tabelle eingefügt. Als nächstes führt es beide Identitätsfunktionen aus.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Durch die Ausführung des Codes wird derselbe Wert in der aktuellen Sitzung und in einem ähnlichen Bereich angezeigt. Sehen Sie sich das folgende Ausgabebild an:

Nun wollen wir anhand eines Beispiels sehen, wie sich beide Funktionen unterscheiden. Zuerst erstellen wir zwei Tabellen mit dem Namen Mitarbeiterdaten Und Abteilung unter Verwendung der folgenden Anweisung:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Als Nächstes erstellen wir einen INSERT-Trigger für die Tabelle „employee_data“. Dieser Trigger wird aufgerufen, um eine Zeile in die Tabelle „department“ einzufügen, wann immer wir eine Zeile in die Tabelle „employee_data“ einfügen.
Die folgende Abfrage erstellt einen Auslöser zum Einfügen eines Standardwerts 'ES' in der Tabelle „department“ bei jeder Einfügeabfrage in der Tabelle „employee_data“:
Hallo Welt mit Java
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Nachdem wir einen Trigger erstellt haben, fügen wir einen Datensatz in die Tabelle „employee_data“ ein und sehen uns die Ausgabe der Funktionen @@IDENTITY und SCOPE_IDENTITY() an.
INSERT INTO employee_data VALUES ('John Mathew');
Durch das Ausführen der Abfrage wird eine Zeile zur Tabelle „employee_data“ hinzugefügt und in derselben Sitzung ein Identitätswert generiert. Sobald die Einfügeabfrage in der Tabelle „employee_data“ ausgeführt wird, ruft sie automatisch einen Trigger auf, um eine Zeile in der Tabelle „department“ hinzuzufügen. Der Identitäts-Seed-Wert ist 1 für die Employee_Data und 100 für die Department-Tabelle.
Abschließend führen wir die folgenden Anweisungen aus, die die Ausgabe 100 für die Funktion SELECT @@IDENTITY und 1 für die Funktion SCOPE_IDENTITY anzeigen, da sie nur einen Identitätswert im gleichen Bereich zurückgeben.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Hier ist das Ergebnis:

IDENT_CURRENT() Funktion
IDENT_CURRENT ist eine systemdefinierte Funktion für Zeigt den aktuellsten IDENTITY-Wert an wird für eine bestimmte Tabelle unter jeder Verbindung generiert. Diese Funktion berücksichtigt nicht den Umfang der SQL-Abfrage, die den Identitätswert erstellt. Diese Funktion benötigt den Tabellennamen, für den wir den Identitätswert erhalten möchten.
Beispiel
Wir können es verstehen, indem wir zuerst die beiden Verbindungsfenster öffnen. Wir werden im ersten Fenster einen Datensatz einfügen, der den Identitätswert 15 in der Personentabelle generiert. Als Nächstes können wir diesen Identitätswert in einem anderen Verbindungsfenster überprüfen, in dem wir dieselbe Ausgabe sehen können. Hier ist der vollständige Code:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Wenn Sie die oben genannten Codes in zwei verschiedenen Fenstern ausführen, wird derselbe Identitätswert angezeigt.

IDENTITY()-Funktion
Die Funktion IDENTITY() ist eine systemdefinierte Funktion Wird zum Einfügen einer Identitätsspalte in eine neue Tabelle verwendet . Diese Funktion unterscheidet sich von der IDENTITY-Eigenschaft, die wir mit den Anweisungen CREATE TABLE und ALTER TABLE verwenden. Wir können diese Funktion nur in einer SELECT INTO-Anweisung verwenden, die beim Übertragen von Daten von einer Tabelle in eine andere verwendet wird.
Die folgende Syntax veranschaulicht die Verwendung dieser Funktion in SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Wenn eine Quelltabelle über eine IDENTITY-Spalte verfügt, erbt die mit einem SELECT INTO-Befehl erstellte Tabelle diese standardmäßig. Zum Beispiel , wir haben zuvor eine Tabelle Person mit einer Identitätsspalte erstellt. Angenommen, wir erstellen eine neue Tabelle, die die Personentabelle erbt, indem wir die SELECT INTO-Anweisungen mit der Funktion IDENTITY() verwenden. In diesem Fall erhalten wir eine Fehlermeldung, da die Quelltabelle bereits über eine Identitätsspalte verfügt. Siehe die folgende Abfrage:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Wenn Sie die obige Anweisung ausführen, wird die folgende Fehlermeldung zurückgegeben:

Erstellen wir mit der folgenden Anweisung eine neue Tabelle ohne Identitätseigenschaft:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Kopieren Sie diese Tabelle dann mit der SELECT INTO-Anweisung einschließlich der IDENTITY-Funktion wie folgt:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Sobald die Anweisung ausgeführt wird, können wir sie mithilfe von überprüfen sp_help Befehl, der Tabelleneigenschaften anzeigt.

Sie können die IDENTITY-Spalte im sehen VERFÜHRBAR Eigenschaften gemäß den angegebenen Bedingungen.
Wenn wir diese Funktion mit der SELECT-Anweisung verwenden, gibt SQL Server die folgende Fehlermeldung aus:
Meldung 177, Ebene 15, Status 1, Zeile 2 Die IDENTITY-Funktion kann nur verwendet werden, wenn die SELECT-Anweisung eine INTO-Klausel enthält.
Wiederverwendung von IDENTITY-Werten
Wir können die Identitätswerte in der SQL Server-Tabelle nicht wiederverwenden. Wenn wir eine Zeile aus der Identitätsspaltentabelle löschen, entsteht eine Lücke in der Identitätsspalte. Außerdem erzeugt SQL Server eine Lücke, wenn wir eine neue Zeile in die Identitätsspalte einfügen und die Anweisung fehlschlägt oder zurückgesetzt wird. Die Lücke weist darauf hin, dass die Identitätswerte verloren gehen und nicht erneut in der IDENTITY-Spalte generiert werden können.
Betrachten Sie das folgende Beispiel, um es praktisch zu verstehen. Wir haben bereits eine Personentabelle mit den folgenden Daten:

Als nächstes erstellen wir zwei weitere Tabellen mit dem Namen 'Position' , Und ' person_position ' mit der folgenden Anweisung:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Als nächstes versuchen wir, einen neuen Datensatz in die Personentabelle einzufügen und ihnen eine Position zuzuweisen, indem wir eine neue Zeile in die Tabelle person_position einfügen. Wir werden dies tun, indem wir die Transaktionsanweisung wie folgt verwenden:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Das obige Transaktionscode-Skript führt die erste Einfügeanweisung erfolgreich aus. Die zweite Anweisung schlug jedoch fehl, da es in der Positionstabelle keine Position mit der ID zehn gab. Daher wurde die gesamte Transaktion rückgängig gemacht.
Da der maximale Identitätswert in der Spalte „PersonID“ 16 beträgt, verbrauchte die erste Einfügeanweisung den Identitätswert 17, und dann wurde die Transaktion zurückgesetzt. Wenn wir daher die nächste Zeile in die Personentabelle einfügen, ist der nächste Identitätswert 18. Führen Sie die folgende Anweisung aus:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Nachdem wir die Personentabelle erneut überprüft haben, sehen wir, dass der neu hinzugefügte Datensatz den Identitätswert 18 enthält.

Zwei IDENTITY-Spalten in einer einzelnen Tabelle
Technisch gesehen ist es nicht möglich, zwei Identitätsspalten in einer einzigen Tabelle zu erstellen. Wenn wir dies tun, gibt SQL Server einen Fehler aus. Siehe folgende Abfrage:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Wenn wir diesen Code ausführen, wird der folgende Fehler angezeigt:

Allerdings können wir mithilfe der berechneten Spalte zwei Identitätsspalten in einer einzelnen Tabelle erstellen. Die folgende Abfrage erstellt eine Tabelle mit einer berechneten Spalte, die die ursprüngliche Identitätsspalte verwendet und diese um 1 verringert.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Als Nächstes fügen wir mit dem folgenden Befehl einige Daten zu dieser Tabelle hinzu:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Abschließend prüfen wir die Tabellendaten mit der SELECT-Anweisung. Es gibt die folgende Ausgabe zurück:

Im Bild sehen wir, wie die SecondID-Spalte als zweite Identitätsspalte fungiert und sich vom Startwert 9990 um zehn verringert.
Missverständnisse über die IDENTITY-Spalte von SQL Server
Der DBA-Benutzer hat viele Missverständnisse in Bezug auf SQL Server-Identitätsspalten. Im Folgenden finden Sie eine Liste der häufigsten Missverständnisse in Bezug auf Identitätsspalten:
IDENTITY-Spalte ist EINZIGARTIG: Laut der offiziellen Dokumentation von SQL Server kann die Identitätseigenschaft nicht garantieren, dass der Spaltenwert eindeutig ist. Wir müssen einen PRIMARY KEY, eine UNIQUE-Einschränkung oder einen UNIQUE-Index verwenden, um die Eindeutigkeit der Spalte zu erzwingen.
IDENTITY-Spalte generiert fortlaufende Nummern: In der offiziellen Dokumentation heißt es eindeutig, dass die zugewiesenen Werte in der Identitätsspalte bei einem Datenbankausfall oder einem Serverneustart verloren gehen können. Es kann beim Einfügen zu Lücken im Identitätswert kommen. Die Lücke kann auch entstehen, wenn wir den Wert aus der Tabelle löschen oder die Einfügeanweisung zurückgesetzt wird. Die Werte, die Lücken erzeugen, können nicht weiter verwendet werden.
IDENTITY-Spalte kann vorhandene Werte nicht automatisch generieren: Es ist für die Identitätsspalte nicht möglich, vorhandene Werte automatisch zu generieren, bis die Identitätseigenschaft mithilfe des DBCC CHECKIDENT-Befehls neu gesetzt wird. Damit können wir den Startwert (Startwert der Zeile) der Identitätseigenschaft anpassen. Nach der Ausführung dieses Befehls überprüft SQL Server nicht, ob die neu erstellten Werte bereits in der Tabelle vorhanden sind oder nicht.
Die IDENTITY-Spalte als PRIMARY KEY reicht aus, um die Zeile zu identifizieren: Wenn ein Primärschlüssel die Identitätsspalte in der Tabelle ohne andere eindeutige Einschränkungen enthält, kann die Spalte doppelte Werte speichern und die Eindeutigkeit der Spalte verhindern. Wie wir wissen, kann der Primärschlüssel keine doppelten Werte speichern, aber die Identitätsspalte kann Duplikate speichern. Es wird empfohlen, den Primärschlüssel und die Identitätseigenschaft nicht für dieselbe Spalte zu verwenden.
Verwenden des falschen Tools, um Identitätswerte nach einer Einfügung wiederherzustellen: Es ist auch ein weit verbreitetes Missverständnis, dass die Unterschiede zwischen den Funktionen @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT und IDENTITY() nicht bekannt sind, um den Identitätswert direkt aus der gerade ausgeführten Anweisung einzufügen.
Unterschied zwischen SEQUENZ und IDENTITÄT
Wir verwenden sowohl SEQUENCE als auch IDENTITY zur Generierung automatischer Zahlen. Es gibt jedoch einige Unterschiede, und der Hauptunterschied besteht darin, dass die Identität tabellenabhängig ist, die Sequenz hingegen nicht. Fassen wir ihre Unterschiede in tabellarischer Form zusammen:
| IDENTITÄT | REIHENFOLGE |
|---|---|
| Die Identitätseigenschaft wird für eine bestimmte Tabelle verwendet und kann nicht mit anderen Tabellen geteilt werden. | Ein DBA definiert das Sequenzobjekt, das von mehreren Tabellen gemeinsam genutzt werden kann, da es unabhängig von einer Tabelle ist. |
| Diese Eigenschaft generiert jedes Mal automatisch Werte, wenn die Einfügeanweisung für die Tabelle ausgeführt wird. | Es verwendet die NEXT VALUE FOR-Klausel, um den nächsten Wert für ein Sequenzobjekt zu generieren. |
| SQL Server setzt den Spaltenwert der Identitätseigenschaft nicht auf seinen Anfangswert zurück. | SQL Server kann den Wert für das Sequenzobjekt zurücksetzen. |
| Wir können den Maximalwert für die Identitätseigenschaft nicht festlegen. | Wir können den Maximalwert für das Sequenzobjekt festlegen. |
| Es wird in SQL Server 2000 eingeführt. | Es wird in SQL Server 2012 eingeführt. |
| Diese Eigenschaft kann keinen Identitätswert in absteigender Reihenfolge generieren. | Es kann Werte in absteigender Reihenfolge generieren. |
Abschluss
Dieser Artikel gibt einen vollständigen Überblick über die IDENTITY-Eigenschaft in SQL Server. Hier haben wir gelernt, wie und wann Identitätseigenschaft verwendet wird, welche unterschiedlichen Funktionen sie hat, welche Missverständnisse es gibt und wie sie sich von der Sequenz unterscheidet.