Das Wort ' Versuchen Sie es ' ist ein Auszug aus dem Wort ' Abruf '. Trie ist eine sortierte baumbasierte Datenstruktur, die den Satz von Zeichenfolgen speichert. Die Anzahl der Zeiger entspricht der Anzahl der Zeichen des Alphabets in jedem Knoten. Es kann mithilfe des Wortpräfixes nach einem Wort im Wörterbuch suchen. Wenn wir beispielsweise davon ausgehen, dass alle Zeichenfolgen aus den Buchstaben ' gebildet werden A ' Zu ' Mit ' im englischen Alphabet kann jeder Trie-Knoten maximal sein 26 Punkte.
Java-Programmierarrays
Trie wird auch als digitaler Baum oder Präfixbaum bezeichnet. Die Position eines Knotens im Trie bestimmt den Schlüssel, mit dem dieser Knoten verbunden ist.
Eigenschaften des Trie für eine Menge der Zeichenfolge:
- Der Wurzelknoten des Versuchs stellt immer den Nullknoten dar.
- Jedes untergeordnete Knotenelement wird alphabetisch sortiert.
- Jeder Knoten kann maximal haben 26 Kinder (A bis Z).
- Jeder Knoten (außer der Wurzel) kann einen Buchstaben des Alphabets speichern.
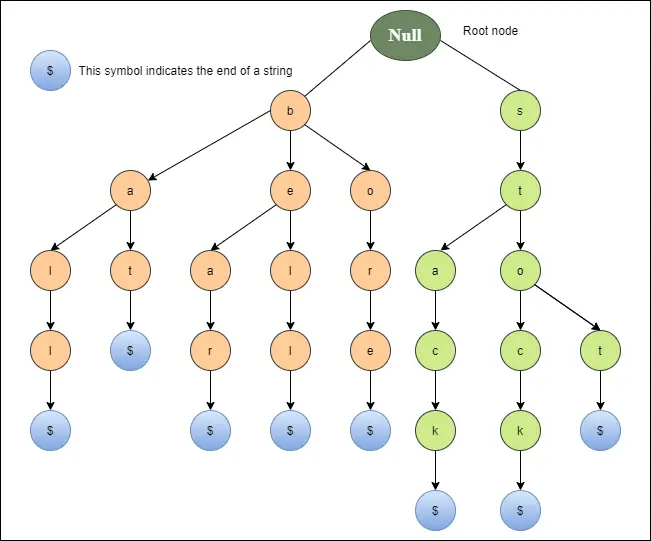
Das folgende Diagramm zeigt eine Trie-Darstellung für Glocke, Bär, Bohrung, Schläger, Ball, Stopp, Schaft und Stapel.
Grundlegende Operationen von Trie
Im Trie gibt es drei Operationen:
- Einfügen eines Knotens
- Suche nach einem Knoten
- Löschen eines Knotens
Einfügen eines Knotens im Trie
Die erste Operation besteht darin, einen neuen Knoten in den Versuch einzufügen. Bevor wir mit der Implementierung beginnen, ist es wichtig, einige Punkte zu verstehen:
- Jeder Buchstabe des Eingabeschlüssels (Wort) wird einzeln im Trie_node eingefügt. Beachten Sie, dass untergeordnete Elemente auf die nächste Ebene von Trie-Knoten verweisen.
- Das Schlüsselzeichenarray fungiert als Index der untergeordneten Elemente.
- Wenn der aktuelle Knoten bereits einen Verweis auf den aktuellen Buchstaben hat, setzen Sie den aktuellen Knoten auf den referenzierten Knoten. Andernfalls erstellen Sie einen neuen Knoten, stellen den Buchstaben so ein, dass er dem aktuellen Buchstaben entspricht, und beginnen sogar den aktuellen Knoten mit diesem neuen Knoten.
- Die Zeichenlänge bestimmt die Tiefe des Versuchs.
Implementierung des Einfügens eines neuen Knotens in den Trie
public class Data_Trie { private Node_Trie root; public Data_Trie(){ this.root = new Node_Trie(); } public void insert(String word){ Node_Trie current = root; int length = word.length(); for (int x = 0; x <length; x++){ char l="word.charAt(x);" node_trie node="current.getNode().get(L);" if (node="=" null){ (); current.getnode().put(l, node); } current="node;" current.setword(true); < pre> <h3>Searching a node in Trie</h3> <p>The second operation is to search for a node in a Trie. The searching operation is similar to the insertion operation. The search operation is used to search a key in the trie. The implementation of the searching operation is shown below.</p> <p>Implementation of search a node in the Trie</p> <pre> class Search_Trie { private Node_Trie Prefix_Search(String W) { Node_Trie node = R; for (int x = 0; x <w.length(); x++) { char curletter="W.charAt(x);" if (node.containskey(curletter)) node="node.get(curLetter);" } else return null; node; public boolean search(string w) node_trie !="null" && node.isend(); < pre> <h3>Deletion of a node in the Trie</h3> <p>The Third operation is the deletion of a node in the Trie. Before we begin the implementation, it is important to understand some points:</p> <ol class="points"> <li>If the key is not found in the trie, the delete operation will stop and exit it.</li> <li>If the key is found in the trie, delete it from the trie.</li> </ol> <p> <strong>Implementation of delete a node in the Trie</strong> </p> <pre> public void Node_delete(String W) { Node_delete(R, W, 0); } private boolean Node_delete(Node_Trie current, String W, int Node_index) { if (Node_index == W.length()) { if (!current.isEndOfWord()) { return false; } current.setEndOfWord(false); return current.getChildren().isEmpty(); } char A = W.charAt(Node_index); Node_Trie node = current.getChildren().get(A); if (node == null) { return false; } boolean Current_Node_Delete = Node_delete(node, W, Node_index + 1) && !node.isEndOfWord(); if (Current_Node_Delete) { current.getChildren().remove(A); return current.getChildren().isEmpty(); } return false; } </pre> <h2>Applications of Trie</h2> <p> <strong>1. Spell Checker</strong> </p> <p>Spell checking is a three-step process. First, look for that word in a dictionary, generate possible suggestions, and then sort the suggestion words with the desired word at the top.</p> <p>Trie is used to store the word in dictionaries. The spell checker can easily be applied in the most efficient way by searching for words on a data structure. Using trie not only makes it easy to see the word in the dictionary, but it is also simple to build an algorithm to include a collection of relevant words or suggestions.</p> <p> <strong>2. Auto-complete</strong> </p> <p>Auto-complete functionality is widely used on text editors, mobile applications, and the Internet. It provides a simple way to find an alternative word to complete the word for the following reasons.</p> <ul> <li>It provides an alphabetical filter of entries by the key of the node.</li> <li>We trace pointers only to get the node that represents the string entered by the user.</li> <li>As soon as you start typing, it tries to complete your input.</li> </ul> <p> <strong>3. Browser history</strong> </p> <p>It is also used to complete the URL in the browser. The browser keeps a history of the URLs of the websites you've visited.</p> <h2>Advantages of Trie</h2> <ol class="points"> <li>It can be insert faster and search the string than hash tables and binary search trees.</li> <li>It provides an alphabetical filter of entries by the key of the node.</li> </ol> <h2>Disadvantages of Trie</h2> <ol class="points"> <li>It requires more memory to store the strings.</li> <li>It is slower than the hash table.</li> </ol> <h2>Complete program in C++</h2> <pre> #include #include #include #define N 26 typedef struct TrieNode TrieNode; struct TrieNode { char info; TrieNode* child[N]; int data; }; TrieNode* trie_make(char info) { TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode)); for (int i = 0; i <n; i++) node → child[i]="NULL;" data="0;" info="info;" return node; } void free_trienode(trienode* node) { for(int i="0;" < n; if (node !="NULL)" free_trienode(node child[i]); else continue; free(node); trie loop start trienode* trie_insert(trienode* flag, char* word) temp="flag;" for (int word[i] ; int idx="(int)" - 'a'; (temp child[idx]="=" null) child[idx]; }trie flag; search_trie(trienode* position="word[i]" child[position]="=" 0; child[position]; && 1) 1; check_divergence(trienode* len="strlen(word);" (len="=" 0) last_index="0;" len; child[position]) j="0;" <n; j++) (j child[j]) + break; last_index; find_longest_prefix(trienode* (!word || word[0]="=" '�') null; longest_prefix="(char*)" calloc 1, sizeof(char)); longest_prefix[i]="word[i];" longest_prefix[len]="�" branch_idx="check_divergence(flag," longest_prefix) (branch_idx>= 0) { longest_prefix[branch_idx] = '�'; longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char)); } return longest_prefix; } int data_node(TrieNode* flag, char* word) { TrieNode* temp = flag; for (int i = 0; word[i]; i++) { int position = (int) word[i] - 'a'; if (temp → child[position]) { temp = temp → child[position]; } } return temp → data; } TrieNode* trie_delete(TrieNode* flag, char* word) { if (!flag) return NULL; if (!word || word[0] == '�') return flag; if (!data_node(flag, word)) { return flag; } TrieNode* temp = flag; char* longest_prefix = find_longest_prefix(flag, word); if (longest_prefix[0] == '�') { free(longest_prefix); return flag; } int i; for (i = 0; longest_prefix[i] != '�'; i++) { int position = (int) longest_prefix[i] - 'a'; if (temp → child[position] != NULL) { temp = temp → child[position]; } else { free(longest_prefix); return flag; } } int len = strlen(word); for (; i <len; i++) { int position="(int)" word[i] - 'a'; if (temp → child[position]) trienode* rm_node="temp→child[position];" temp child[position]="NULL;" free_trienode(rm_node); } free(longest_prefix); return flag; void print_trie(trienode* flag) (!flag) return; printf('%c ', temp→info); for (int i="0;" < n; print_trie(temp child[i]); search(trienode* flag, char* word) printf('search the word %s: word); (search_trie(flag, 0) printf('not found
'); else printf('found!
'); main() flag="trie_make('�');" 'oh'); 'way'); 'bag'); 'can'); search(flag, 'ohh'); 'ways'); print_trie(flag); printf('
'); printf('deleting 'hello'...
'); 'can'...
'); free_trienode(flag); 0; pre> <p> <strong>Output</strong> </p> <pre> Search the word ohh: Not Found Search the word bag: Found! Search the word can: Found! Search the word ways: Not Found Search the word way: Found! → h → e → l → l → o → w → a → y → i → t → e → a → b → a → g → c → a → n deleting the word 'hello'... → w → a → y → h → i → t → e → a → b → a → g → c → a → n deleting the word 'can'... → w → a → y → h → i → t → e → a → b → a → g </pre> <hr></len;></n;></pre></w.length();></pre></length;> Anwendungen von Trie
1. Rechtschreibprüfung
Die Rechtschreibprüfung ist ein dreistufiger Prozess. Suchen Sie zunächst in einem Wörterbuch nach diesem Wort, generieren Sie mögliche Vorschläge und sortieren Sie dann die vorgeschlagenen Wörter so, dass das gewünschte Wort ganz oben steht.
Java-Synchronisierung
Trie wird verwendet, um das Wort in Wörterbüchern zu speichern. Die Rechtschreibprüfung kann ganz einfach und auf die effizienteste Weise angewendet werden, indem nach Wörtern in einer Datenstruktur gesucht wird. Durch die Verwendung von trie ist es nicht nur einfacher, das Wort im Wörterbuch zu erkennen, sondern es ist auch einfach, einen Algorithmus zu erstellen, der eine Sammlung relevanter Wörter oder Vorschläge einbezieht.
2. Automatische Vervollständigung
C++-Teilungszeichenfolge
Die Funktion zur automatischen Vervollständigung wird häufig in Texteditoren, mobilen Anwendungen und im Internet verwendet. Aus folgenden Gründen bietet es eine einfache Möglichkeit, ein alternatives Wort zur Vervollständigung des Wortes zu finden.
- Es bietet einen alphabetischen Filter von Einträgen nach dem Schlüssel des Knotens.
- Wir verfolgen Zeiger nur, um den Knoten zu erhalten, der die vom Benutzer eingegebene Zeichenfolge darstellt.
- Sobald Sie mit der Eingabe beginnen, wird versucht, Ihre Eingabe zu vervollständigen.
3. Browserverlauf
Es wird auch verwendet, um die URL im Browser zu vervollständigen. Der Browser speichert einen Verlauf der URLs der von Ihnen besuchten Websites.
Vorteile von Trie
- Es kann schneller eingefügt werden und die Zeichenfolge durchsuchen als Hash-Tabellen und binäre Suchbäume.
- Es bietet einen alphabetischen Filter von Einträgen nach dem Schlüssel des Knotens.
Nachteile von Trie
- Zum Speichern der Zeichenfolgen ist mehr Speicher erforderlich.
- Es ist langsamer als die Hash-Tabelle.
Komplettes Programm in C++
#include #include #include #define N 26 typedef struct TrieNode TrieNode; struct TrieNode { char info; TrieNode* child[N]; int data; }; TrieNode* trie_make(char info) { TrieNode* node = (TrieNode*) calloc (1, sizeof(TrieNode)); for (int i = 0; i <n; i++) node → child[i]="NULL;" data="0;" info="info;" return node; } void free_trienode(trienode* node) { for(int i="0;" < n; if (node !="NULL)" free_trienode(node child[i]); else continue; free(node); trie loop start trienode* trie_insert(trienode* flag, char* word) temp="flag;" for (int word[i] ; int idx="(int)" - \'a\'; (temp child[idx]="=" null) child[idx]; }trie flag; search_trie(trienode* position="word[i]" child[position]="=" 0; child[position]; && 1) 1; check_divergence(trienode* len="strlen(word);" (len="=" 0) last_index="0;" len; child[position]) j="0;" <n; j++) (j child[j]) + break; last_index; find_longest_prefix(trienode* (!word || word[0]="=" \'�\') null; longest_prefix="(char*)" calloc 1, sizeof(char)); longest_prefix[i]="word[i];" longest_prefix[len]="�" branch_idx="check_divergence(flag," longest_prefix) (branch_idx>= 0) { longest_prefix[branch_idx] = '�'; longest_prefix = (char*) realloc (longest_prefix, (branch_idx + 1) * sizeof(char)); } return longest_prefix; } int data_node(TrieNode* flag, char* word) { TrieNode* temp = flag; for (int i = 0; word[i]; i++) { int position = (int) word[i] - 'a'; if (temp → child[position]) { temp = temp → child[position]; } } return temp → data; } TrieNode* trie_delete(TrieNode* flag, char* word) { if (!flag) return NULL; if (!word || word[0] == '�') return flag; if (!data_node(flag, word)) { return flag; } TrieNode* temp = flag; char* longest_prefix = find_longest_prefix(flag, word); if (longest_prefix[0] == '�') { free(longest_prefix); return flag; } int i; for (i = 0; longest_prefix[i] != '�'; i++) { int position = (int) longest_prefix[i] - 'a'; if (temp → child[position] != NULL) { temp = temp → child[position]; } else { free(longest_prefix); return flag; } } int len = strlen(word); for (; i <len; i++) { int position="(int)" word[i] - \'a\'; if (temp → child[position]) trienode* rm_node="temp→child[position];" temp child[position]="NULL;" free_trienode(rm_node); } free(longest_prefix); return flag; void print_trie(trienode* flag) (!flag) return; printf(\'%c \', temp→info); for (int i="0;" < n; print_trie(temp child[i]); search(trienode* flag, char* word) printf(\'search the word %s: word); (search_trie(flag, 0) printf(\'not found
\'); else printf(\'found!
\'); main() flag="trie_make('�');" \'oh\'); \'way\'); \'bag\'); \'can\'); search(flag, \'ohh\'); \'ways\'); print_trie(flag); printf(\'
\'); printf(\'deleting \'hello\'...
\'); \'can\'...
\'); free_trienode(flag); 0; pre> <p> <strong>Output</strong> </p> <pre> Search the word ohh: Not Found Search the word bag: Found! Search the word can: Found! Search the word ways: Not Found Search the word way: Found! → h → e → l → l → o → w → a → y → i → t → e → a → b → a → g → c → a → n deleting the word 'hello'... → w → a → y → h → i → t → e → a → b → a → g → c → a → n deleting the word 'can'... → w → a → y → h → i → t → e → a → b → a → g </pre> <hr></len;></n;>