In diesem Artikel werden wir den BFS-Algorithmus in der Datenstruktur diskutieren. Die Breitensuche ist ein Graph-Traversal-Algorithmus, der mit der Traversierung des Graphen vom Wurzelknoten aus beginnt und alle benachbarten Knoten untersucht. Anschließend wählt es den nächstgelegenen Knoten aus und erkundet alle unerforschten Knoten. Bei der Verwendung von BFS zum Durchlaufen kann jeder Knoten im Diagramm als Wurzelknoten betrachtet werden.
Es gibt viele Möglichkeiten, den Graphen zu durchlaufen, aber unter diesen ist BFS der am häufigsten verwendete Ansatz. Es handelt sich um einen rekursiven Algorithmus zum Durchsuchen aller Eckpunkte einer Baum- oder Diagrammdatenstruktur. BFS ordnet jeden Scheitelpunkt des Diagramms zwei Kategorien zu: besucht und nicht besucht. Es wählt einen einzelnen Knoten in einem Diagramm aus und besucht anschließend alle Knoten neben dem ausgewählten Knoten.
Anwendungen des BFS-Algorithmus
Die Anwendungen des Breiten-zuerst-Algorithmus sind wie folgt angegeben:
- BFS kann verwendet werden, um die benachbarten Standorte eines bestimmten Quellstandorts zu finden.
- In einem Peer-to-Peer-Netzwerk kann der BFS-Algorithmus als Traversalmethode verwendet werden, um alle benachbarten Knoten zu finden. Die meisten Torrent-Clients wie BitTorrent, uTorrent usw. verwenden diesen Prozess, um „Seeds“ und „Peers“ im Netzwerk zu finden.
- BFS kann in Webcrawlern zum Erstellen von Webseitenindizes verwendet werden. Es handelt sich um einen der wichtigsten Algorithmen, der zum Indexieren von Webseiten verwendet werden kann. Der Durchlauf beginnt auf der Quellseite und folgt den mit der Seite verknüpften Links. Dabei wird jede Webseite als Knoten im Diagramm betrachtet.
- BFS wird verwendet, um den kürzesten Pfad und den minimalen Spannbaum zu bestimmen.
- BFS wird auch in Cheneys Technik verwendet, um die Garbage Collection zu duplizieren.
- Es kann in der Ford-Fulkerson-Methode verwendet werden, um den maximalen Fluss in einem Flussnetzwerk zu berechnen.
Algorithmus
Die Schritte des BFS-Algorithmus zur Untersuchung eines Diagramms sind wie folgt:
Schritt 1: SET STATUS = 1 (Bereitschaftszustand) für jeden Knoten in G
Schritt 2: Stellen Sie den Startknoten A in die Warteschlange und setzen Sie seinen STATUS = 2 (Wartezustand).
Schritt 3: Wiederholen Sie die Schritte 4 und 5, bis die Warteschlange leer ist
Schritt 4: Entfernen Sie einen Knoten N aus der Warteschlange. Verarbeiten Sie ihn und setzen Sie seinen STATUS = 3 (verarbeiteter Status).
Schritt 5: Alle Nachbarn von N, die sich im Bereitschaftszustand befinden (deren STATUS = 1 ist), in die Warteschlange stellen und festlegen
Python sortiert Tupel
ihr STATUS = 2
(Wartezustand)
[ENDE DER SCHLEIFE]
Schritt 6: AUSFAHRT
Beispiel eines BFS-Algorithmus
Lassen Sie uns nun die Funktionsweise des BFS-Algorithmus anhand eines Beispiels verstehen. Im folgenden Beispiel gibt es einen gerichteten Graphen mit 7 Eckpunkten.
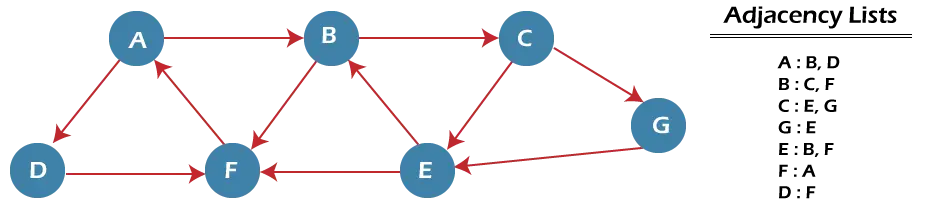
In der obigen Grafik kann der minimale Pfad „P“ mithilfe des BFS ermittelt werden, der bei Knoten A beginnt und bei Knoten E endet. Der Algorithmus verwendet zwei Warteschlangen, nämlich QUEUE1 und QUEUE2. QUEUE1 enthält alle Knoten, die verarbeitet werden sollen, während QUEUE2 alle Knoten enthält, die verarbeitet und aus QUEUE1 gelöscht werden.
Beginnen wir nun mit der Untersuchung des Diagramms beginnend bei Knoten A.
Schritt 1 - Fügen Sie zunächst A zu Warteschlange1 und NULL zu Warteschlange2 hinzu.
QUEUE1 = {A} QUEUE2 = {NULL} Schritt 2 - Löschen Sie nun Knoten A aus Warteschlange1 und fügen Sie ihn zu Warteschlange2 hinzu. Fügen Sie alle Nachbarn von Knoten A in Warteschlange1 ein.
QUEUE1 = {B, D} QUEUE2 = {A} Schritt 3 - Löschen Sie nun Knoten B aus Warteschlange1 und fügen Sie ihn zu Warteschlange2 hinzu. Fügen Sie alle Nachbarn von Knoten B in Warteschlange1 ein.
QUEUE1 = {D, C, F} QUEUE2 = {A, B} Schritt 4 - Löschen Sie nun Knoten D aus Warteschlange1 und fügen Sie ihn zu Warteschlange2 hinzu. Fügen Sie alle Nachbarn von Knoten D in Warteschlange1 ein. Der einzige Nachbar von Knoten D ist F, da er bereits eingefügt ist und daher nicht noch einmal eingefügt wird.
QUEUE1 = {C, F} QUEUE2 = {A, B, D} Schritt 5 - Löschen Sie Knoten C aus Warteschlange1 und fügen Sie ihn zu Warteschlange2 hinzu. Fügen Sie alle Nachbarn von Knoten C in Warteschlange1 ein.
QUEUE1 = {F, E, G} QUEUE2 = {A, B, D, C} Schritt 5 - Löschen Sie Knoten F aus Warteschlange1 und fügen Sie ihn zu Warteschlange2 hinzu. Fügen Sie alle Nachbarn von Knoten F in Warteschlange1 ein. Da alle Nachbarn von Knoten F bereits vorhanden sind, werden wir sie nicht noch einmal einfügen.
QUEUE1 = {E, G} QUEUE2 = {A, B, D, C, F} Schritt 6 - Löschen Sie Knoten E aus Warteschlange1. Da alle seine Nachbarn bereits hinzugefügt wurden, werden wir sie nicht noch einmal einfügen. Jetzt werden alle Knoten besucht und der Zielknoten E wird in Warteschlange2 gefunden.
QUEUE1 = {G} QUEUE2 = {A, B, D, C, F, E} Komplexität des BFS-Algorithmus
Die zeitliche Komplexität von BFS hängt von der Datenstruktur ab, die zur Darstellung des Diagramms verwendet wird. Die zeitliche Komplexität des BFS-Algorithmus beträgt O(V+E) , da der BFS-Algorithmus im schlimmsten Fall jeden Knoten und jede Kante untersucht. In einem Diagramm beträgt die Anzahl der Eckpunkte O(V), während die Anzahl der Kanten O(E) beträgt.
Die räumliche Komplexität von BFS kann ausgedrückt werden als: O(V) , wobei V die Anzahl der Eckpunkte ist.
Implementierung des BFS-Algorithmus
Sehen wir uns nun die Implementierung des BFS-Algorithmus in Java an.
In diesem Code verwenden wir die Adjazenzliste zur Darstellung unseres Diagramms. Die Implementierung des Breadth-First-Suchalgorithmus in Java erleichtert den Umgang mit der Adjazenzliste erheblich, da wir nur die Liste der an jeden Knoten angehängten Knoten durchgehen müssen, sobald der Knoten vom Kopf (oder Anfang) der Warteschlange entfernt wird.
Java-Multithreading
In diesem Beispiel sieht das Diagramm, das wir zur Veranschaulichung des Codes verwenden, wie folgt aus:

import java.io.*; import java.util.*; public class BFSTraversal { private int vertex; /* total number number of vertices in the graph */ private LinkedList adj[]; /* adjacency list */ private Queue que; /* maintaining a queue */ BFSTraversal(int v) { vertex = v; adj = new LinkedList[vertex]; for (int i=0; i<v; i++) { adj[i]="new" linkedlist(); } que="new" void insertedge(int v,int w) adj[v].add(w); * adding an edge to the adjacency list (edges are bidirectional in this example) bfs(int n) boolean nodes[]="new" boolean[vertex]; initialize array for holding data int a="0;" nodes[n]="true;" que.add(n); root node is added top of queue while (que.size() !="0)" n="que.poll();" remove element system.out.print(n+' '); print (int i="0;" < adj[n].size(); iterate through linked and push all neighbors into if (!nodes[a]) only insert nodes they have not been explored already nodes[a]="true;" que.add(a); public static main(string args[]) bfstraversal graph="new" bfstraversal(10); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, graph.insertedge(6, graph.insertedge(7, 8); system.out.println('breadth first traversal is:'); graph.bfs(2); pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/64/bfs-algorithm-3.webp" alt="Breadth First Search Algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the Breadth-first search technique along with its example, complexity, and implementation in java programming language. Here, we have also seen the real-life applications of BFS that show it the important data structure algorithm.</p> <p>So, that's all about the article. Hope, it will be helpful and informative to you.</p> <hr></v;>