Was ist LRU-Cache?
Cache-Ersetzungsalgorithmen sind effizient darauf ausgelegt, den Cache zu ersetzen, wenn der Speicherplatz voll ist. Der Zuletzt benutzt (LRU) ist einer dieser Algorithmen. Wie der Name schon sagt, wenn der Cache-Speicher voll ist, LRU Wählt die Daten aus, die am längsten nicht verwendet wurden, und entfernt sie, um Platz für die neuen Daten zu schaffen. Die Priorität der Daten im Cache ändert sich je nach Bedarf dieser Daten, d. h. wenn einige Daten kürzlich abgerufen oder aktualisiert wurden, wird die Priorität dieser Daten geändert und der höchsten Priorität zugewiesen, und die Priorität der Daten verringert sich, wenn dies der Fall ist bleibt nach Operationen ungenutzt.
Inhaltsverzeichnis
- Was ist LRU-Cache?
- Vorgänge im LRU-Cache:
- Funktionsweise des LRU-Cache:
- Möglichkeiten zur Implementierung des LRU-Cache:
- LRU-Cache-Implementierung mit Warteschlange und Hashing:
- LRU-Cache-Implementierung mit doppelt verknüpfter Liste und Hashing:
- LRU-Cache-Implementierung mit Deque & Hashmap:
- LRU-Cache-Implementierung mit Stack & Hashmap:
- LRU-Cache mit Counter-Implementierung:
- LRU-Cache-Implementierung mit Lazy Updates:
- Komplexitätsanalyse des LRU-Cache:
- Vorteile des LRU-Cache:
- Nachteile des LRU-Cache:
- Reale Anwendung des LRU-Cache:
LRU Der Algorithmus ist ein Standardproblem und kann je nach Bedarf, beispielsweise in Betriebssystemen, variieren LRU spielt eine entscheidende Rolle, da es als Seitenersetzungsalgorithmus verwendet werden kann, um Seitenfehler zu minimieren.
Vorgänge im LRU-Cache:
- LRUCache (Kapazität c): Initialisieren Sie den LRU-Cache mit einer positiven Kapazitätsgröße C.
- (Schlüssel) bekommen : Gibt den Wert von Key ' zurück k’ Wenn es im Cache vorhanden ist, wird andernfalls -1 zurückgegeben. Aktualisiert außerdem die Priorität der Daten im LRU-Cache.
- put (Schlüssel, Wert): Aktualisieren Sie den Wert des Schlüssels, wenn dieser Schlüssel vorhanden ist. Andernfalls fügen Sie dem Cache ein Schlüssel-Wert-Paar hinzu. Wenn die Anzahl der Schlüssel die Kapazität des LRU-Cache überschreitet, verwerfen Sie den zuletzt verwendeten Schlüssel.
Funktionsweise des LRU-Cache:
Nehmen wir an, wir haben einen LRU-Cache mit einer Kapazität von 3 und möchten folgende Vorgänge ausführen:
- Legen Sie (Schlüssel=1, Wert=A) in den Cache
- Legen Sie (Schlüssel=2, Wert=B) in den Cache
- Legen Sie (Schlüssel=3, Wert=C) in den Cache
- Holen Sie sich (Schlüssel=2) aus dem Cache
- Holen Sie sich (Schlüssel=4) aus dem Cache
- Legen Sie (Schlüssel=4, Wert=D) in den Cache
- Legen Sie (Schlüssel=3, Wert=E) in den Cache
- Holen Sie sich (Schlüssel=4) aus dem Cache
- Legen Sie (Schlüssel=1, Wert=A) in den Cache
Die oben genannten Vorgänge werden nacheinander ausgeführt, wie im Bild unten gezeigt:
Detaillierte Erläuterung jeder Operation:
- Put (Schlüssel 1, Wert A) : Da der LRU-Cache eine leere Kapazität = 3 hat, ist kein Ersatz erforderlich und wir setzen {1 : A} an die Spitze, d. h. {1 : A} hat die höchste Priorität.
- Put (Schlüssel 2, Wert B) : Da der LRU-Cache eine leere Kapazität = 2 hat, besteht wiederum kein Bedarf für einen Ersatz, aber jetzt hat {2: B} die höchste Priorität und die Priorität von {1: A} nimmt ab.
- Put (Schlüssel 3, Wert C) : Im Cache ist immer noch 1 leerer Platz frei. Geben Sie daher {3 : C} ohne Ersatz ein. Beachten Sie, dass der Cache jetzt voll ist und die aktuelle Prioritätsreihenfolge von der höchsten zur niedrigsten {3:C}, {2:B }, {1:A}.
- Holen Sie sich (Schlüssel 2) : Nun wird während dieser Operation der Wert „key=2“ zurückgegeben, da auch „key=2“ verwendet wird. Die neue Prioritätsreihenfolge lautet nun {2:B}, {3:C}, {1:A}.
- Holen Sie sich (Schlüssel 4): Beachten Sie, dass Schlüssel 4 nicht im Cache vorhanden ist. Wir geben für diesen Vorgang „-1“ zurück.
- Put (Schlüssel 4, Wert D) : Beachten Sie, dass der Cache VOLL ist. Verwenden Sie nun den LRU-Algorithmus, um zu bestimmen, welcher Schlüssel am längsten nicht verwendet wurde. Da {1:A} die geringste Priorität hatte, entfernen Sie {1:A} aus unserem Cache und legen Sie {4:D} in den Cache. Beachten Sie, dass die neue Prioritätsreihenfolge {4:D}, {2:B}, {3:C} ist.
- Put (Schlüssel 3, Wert E) : Da „key=3“ bereits im Cache mit dem Wert „C“ vorhanden war, führt dieser Vorgang nicht zum Entfernen eines Schlüssels, sondern aktualisiert den Wert von „key=3“ auf „ UND' . Die neue Prioritätsreihenfolge lautet nun {3:E}, {4:D}, {2:B}.
- Holen Sie sich (Schlüssel 4) : Gibt den Wert von key=4 zurück. Jetzt wird die neue Priorität zu {4:D}, {3:E}, {2:B}.
- Put (Schlüssel 1, Wert A) : Da unser Cache VOLL ist, verwenden Sie unseren LRU-Algorithmus, um zu ermitteln, welcher Schlüssel zuletzt verwendet wurde. Da {2:B} die geringste Priorität hatte, entfernen Sie {2:B} aus unserem Cache und fügen Sie {1:A} in den ein Zwischenspeicher. Die neue Prioritätsreihenfolge lautet nun {1:A}, {4:D}, {3:E}
Möglichkeiten zur Implementierung des LRU-Cache:
Der LRU-Cache kann auf verschiedene Arten implementiert werden, und jeder Programmierer kann einen anderen Ansatz wählen. Im Folgenden sind jedoch häufig verwendete Ansätze aufgeführt:
Länge eines Strings in Java
- LRU nutzt Warteschlange und Hashing
- LRU verwendet Doppelt verknüpfte Liste + Hashing
- LRU mit Deque
- LRU mit Stack
- LRU verwendet Gegenimplementierung
- LRU nutzt Lazy Updates
LRU-Cache-Implementierung mit Warteschlange und Hashing:
Wir verwenden zwei Datenstrukturen, um einen LRU-Cache zu implementieren.
- Warteschlange wird mithilfe einer doppelt verknüpften Liste implementiert. Die maximale Größe der Warteschlange entspricht der Gesamtzahl der verfügbaren Frames (Cache-Größe). Die zuletzt verwendeten Seiten befinden sich im vorderen Bereich und die zuletzt verwendeten Seiten im hinteren Bereich.
- Ein Hash mit der Seitennummer als Schlüssel und der Adresse des entsprechenden Warteschlangenknotens als Wert.
Wenn auf eine Seite verwiesen wird, befindet sich die erforderliche Seite möglicherweise im Speicher. Wenn es sich im Speicher befindet, müssen wir den Knoten von der Liste trennen und ihn an den Anfang der Warteschlange stellen.
Wenn die erforderliche Seite nicht im Speicher ist, bringen wir sie in den Speicher. Mit einfachen Worten: Wir fügen einen neuen Knoten am Anfang der Warteschlange hinzu und aktualisieren die entsprechende Knotenadresse im Hash. Wenn die Warteschlange voll ist, d. h. alle Frames voll sind, entfernen wir einen Knoten am Ende der Warteschlange und fügen den neuen Knoten am Anfang der Warteschlange hinzu.
Illustration:
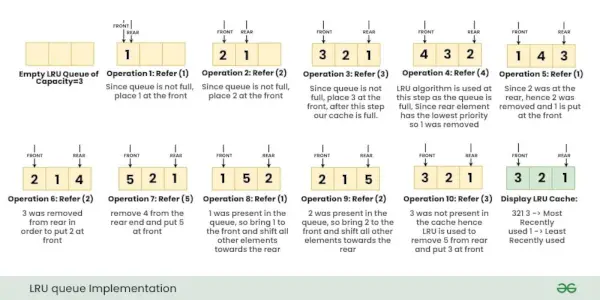
Betrachten wir die Operationen, Bezieht sich Schlüssel X mit im LRU-Cache: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Notiz: Zunächst ist keine Seite im Speicher.Die folgenden Bilder zeigen die schrittweise Ausführung der oben genannten Vorgänge im LRU-Cache.
Algorithmus:
- Erstellen Sie eine Klasse LRUCache mit der Deklaration einer Liste vom Typ int, einer ungeordneten Karte vom Typ
- In der Refer-Funktion von LRUCache
- Wenn dieser Wert in der Warteschlange nicht vorhanden ist, schieben Sie diesen Wert vor die Warteschlange und entfernen Sie den letzten Wert, wenn die Warteschlange voll ist
- Wenn der Wert bereits vorhanden ist, entfernen Sie ihn aus der Warteschlange und schieben Sie ihn an den Anfang der Warteschlange
- In der Anzeigefunktion print verwendet der LRUCache die Warteschlange von vorne
Nachfolgend finden Sie die Umsetzung des oben genannten Ansatzes:
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->Seitennummer = Seitennummer;> > >// Initialize prev and next as NULL> >temp->prev = temp->next = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->Anzahl = 0;> >queue->front = queue->rear = NULL;> > >// Number of frames that can be stored in memory> >queue->numberOfFrames = numberOfFrames;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->Kapazität = Kapazität;> > >// Create an array of pointers for referring queue nodes> >hash->Array> >= (QNode**)>malloc>(hash->Kapazität *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->array[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == queue->numberOfFrames;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->hinten == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->front == queue->rear)> >queue->vorne = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->hinteren;> >queue->hinten = queue->rear->prev;> > >if> (queue->hinten)> >queue->hinten->nächste = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->zählen--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->array[queue->rear->pageNumber] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->next = queue->front;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->hinten = Warteschlange->vorne = temp;> >else> // Else change the front> >{> >queue->front->prev = temp;> >queue->Vorderseite = Temperatur;> >}> > >// Add page entry to hash also> >hash->array[pageNumber] = temp;> > >// increment number of full frames> >queue->count++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->array[Seitennummer];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->vorne) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->prev->next = reqPage->next;> >if> (reqPage->weiter)> >reqPage->next->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->hinten) {> >queue->hinten = reqPage->prev;> >queue->hinten->nächste = NULL;> >}> > >// Put the requested page before current front> >reqPage->next = queue->front;> >reqPage->prev = NULL;> > >// Change prev of current front> >reqPage->next->prev = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);> >printf>(>'%d '>, q->front->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->next->pageNumber);> > >return> 0;> }> |
>
>
k nächster Nachbar
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
Java-String ist leer
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doubleQueue;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Primzahl in Java
LRU-Cache-Implementierung mit doppelt verknüpfter Liste und Hashing :
Die Idee ist sehr einfach, d. h. die Elemente werden immer wieder am Kopf eingefügt.
- Wenn das Element nicht in der Liste vorhanden ist, fügen Sie es am Kopf der Liste hinzu
- Wenn das Element in der Liste vorhanden ist, verschieben Sie das Element an den Kopf und verschieben Sie das verbleibende Element der Liste
Beachten Sie, dass die Priorität des Knotens von der Entfernung dieses Knotens vom Kopf abhängt. Je näher der Knoten am Kopf liegt, desto höher ist seine Priorität. Wenn also der Cache voll ist und wir ein Element entfernen müssen, entfernen wir das Element neben dem Ende der doppelt verknüpften Liste.
LRU-Cache-Implementierung mit Deque & Hashmap:
Die Deque-Datenstruktur ermöglicht das Einfügen und Löschen sowohl von vorne als auch von hinten. Diese Eigenschaft ermöglicht die Implementierung von LRU, da das vordere Element ein Element mit hoher Priorität darstellen kann, während das Endelement das Element mit niedriger Priorität sein kann, d. h. am wenigsten kürzlich verwendet.
Arbeiten:
- Holen Sie sich den Betrieb : Überprüft, ob der Schlüssel in der Hash-Map des Caches vorhanden ist, und befolgt die folgenden Fälle auf der Deque:
- Wenn der Schlüssel gefunden wird:
- Der Artikel gilt als kürzlich verwendet und wird daher an die Vorderseite der Deque verschoben.
- Als Ergebnis wird der dem Schlüssel zugeordnete Wert zurückgegeben
get>Betrieb.- Wenn der Schlüssel nicht gefunden wird:
- Geben Sie -1 zurück, um anzuzeigen, dass kein solcher Schlüssel vorhanden ist.
- Put-Operation: Überprüfen Sie zunächst, ob der Schlüssel bereits in der Hash-Map des Caches vorhanden ist, und befolgen Sie die folgenden Fälle für die Deque
- Wenn der Schlüssel vorhanden ist:
- Der dem Schlüssel zugeordnete Wert wird aktualisiert.
- Der Gegenstand wird an die Vorderseite der Doppelschlange verschoben, da er nun der zuletzt verwendete ist.
- Wenn der Schlüssel nicht existiert:
- Wenn der Cache voll ist, bedeutet dies, dass ein neues Element eingefügt werden muss und das zuletzt verwendete Element entfernt werden muss. Dies geschieht durch Entfernen des Elements vom Ende der Deque und des entsprechenden Eintrags aus der Hash-Map.
- Das neue Schlüssel-Wert-Paar wird dann sowohl in die Hash-Map als auch an die Vorderseite der Deque eingefügt, um anzuzeigen, dass es sich um das zuletzt verwendete Element handelt
LRU-Cache-Implementierung mit Stack & Hashmap:
Die Implementierung eines LRU-Cache (Least Recent Used) mithilfe einer Stack-Datenstruktur und Hashing kann etwas schwierig sein, da ein einfacher Stack keinen effizienten Zugriff auf das zuletzt verwendete Element bietet. Sie können jedoch einen Stack mit einer Hash-Map kombinieren, um dies effizient zu erreichen. Hier ist ein allgemeiner Ansatz zur Implementierung:
- Verwenden Sie eine Hash-Map : Die Hash-Map speichert die Schlüssel-Wert-Paare des Caches. Die Schlüssel werden den entsprechenden Knoten im Stapel zugeordnet.
- Verwenden Sie einen Stapel : Der Stapel behält die Reihenfolge der Schlüssel basierend auf ihrer Verwendung bei. Der zuletzt verwendete Gegenstand befindet sich unten im Stapel und der zuletzt verwendete Gegenstand ganz oben
Dieser Ansatz ist nicht besonders effizient und wird daher nicht oft verwendet.
LRU-Cache mit Counter-Implementierung:
Jeder Block im Cache verfügt über einen eigenen LRU-Zähler, zu dem der Wert des Zählers gehört {0 bis n-1} , Hier ' N ‘ stellt die Größe des Caches dar. Der Block, der beim Blockaustausch geändert wird, wird zum MRU-Block, und dadurch wird sein Zählerwert auf n – 1 geändert. Die Zählerwerte, die größer als der Zählerwert des Blocks, auf den zugegriffen wird, sind, werden um eins dekrementiert. Die übrigen Blöcke bleiben unverändert.
| Wert von Conter | Priorität | Gebrauchtstatus |
|---|---|---|
| 0 | Niedrig | Zuletzt benutzt |
| n-1 | Hoch | Zuletzt verwendet |
LRU-Cache-Implementierung mit Lazy Updates:
Die Implementierung eines LRU-Cache (Least Recent Used) mithilfe verzögerter Aktualisierungen ist eine gängige Technik zur Verbesserung der Effizienz der Cache-Vorgänge. Bei verzögerten Aktualisierungen wird die Reihenfolge verfolgt, in der auf Elemente zugegriffen wird, ohne dass sofort die gesamte Datenstruktur aktualisiert wird. Wenn ein Cache-Fehler auftritt, können Sie anhand einiger Kriterien entscheiden, ob eine vollständige Aktualisierung durchgeführt werden soll oder nicht.
Komplexitätsanalyse des LRU-Cache:
- Zeitkomplexität:
- Put()-Operation: O(1), d. h. die zum Einfügen oder Aktualisieren eines neuen Schlüssel-Wert-Paares erforderliche Zeit ist konstant
- Get()-Operation: O(1), d. h. die Zeit, die benötigt wird, um den Wert eines Schlüssels zu erhalten, ist konstant
- Hilfsraum: O(N) wobei N die Kapazität des Caches ist.
Vorteile des LRU-Cache:
- Schneller Zugriff : Der Zugriff auf die Daten aus dem LRU-Cache dauert O(1).
- Schnelles Update : Es dauert O(1) Zeit, ein Schlüssel-Wert-Paar im LRU-Cache zu aktualisieren.
- Schnelle Entfernung der zuletzt verwendeten Daten : Es dauert O(1), um alles zu löschen, was kürzlich nicht verwendet wurde.
- Kein Prügel: LRU ist im Vergleich zu FIFO weniger anfällig für Thrashing, da es den Nutzungsverlauf von Seiten berücksichtigt. Es kann erkennen, welche Seiten häufig verwendet werden, und diese bei der Speicherzuweisung priorisieren, wodurch die Anzahl von Seitenfehlern und Festplatten-E/A-Vorgängen reduziert wird.
Nachteile des LRU-Cache:
- Um die Effizienz zu steigern, ist eine große Cache-Größe erforderlich.
- Es erfordert die Implementierung zusätzlicher Datenstrukturen.
- Die Hardwareunterstützung ist hoch.
- Bei LRU ist die Fehlererkennung im Vergleich zu anderen Algorithmen schwierig.
- Die Akzeptanz ist begrenzt.
Reale Anwendung des LRU-Cache:
- In Datenbanksystemen für schnelle Abfrageergebnisse.
- In Betriebssystemen, um Seitenfehler zu minimieren.
- Texteditoren und IDEs zum Speichern häufig verwendeter Dateien oder Codefragmente
- Netzwerkrouter und Switches nutzen LRU, um die Effizienz des Computernetzwerks zu steigern
- Bei Compileroptimierungen
- Tools zur Textvorhersage und Autovervollständigung