Ein Cursor in SQL Server ist ein d atabase-Objekt, das es uns ermöglicht, jede Zeile einzeln abzurufen und ihre Daten zu bearbeiten . Ein Cursor ist nichts anderes als ein Zeiger auf eine Zeile. Es wird immer in Verbindung mit einer SELECT-Anweisung verwendet. Normalerweise handelt es sich um eine Sammlung von SQL Logik, die eine vorgegebene Anzahl von Zeilen nacheinander durchläuft. Ein einfaches Beispiel für den Cursor ist, wenn wir über eine umfangreiche Datenbank mit Arbeitnehmerakten verfügen und das Gehalt jedes Arbeitnehmers nach Abzug von Steuern und Urlaub berechnen möchten.
Der SQL-Server Der Zweck des Cursors besteht darin, die Daten Zeile für Zeile zu aktualisieren, zu ändern oder Berechnungen durchzuführen, die nicht möglich sind, wenn wir alle Datensätze auf einmal abrufen . Es ist auch nützlich, um Verwaltungsaufgaben wie SQL Server-Datenbanksicherungen in sequentieller Reihenfolge auszuführen. Cursor werden hauptsächlich in Entwicklungs-, DBA- und ETL-Prozessen verwendet.
In diesem Artikel wird alles über den SQL Server-Cursor erklärt, z. B. den Cursor-Lebenszyklus, warum und wann der Cursor verwendet wird, wie Cursor implementiert werden, welche Einschränkungen es gibt und wie wir einen Cursor ersetzen können.
Lebenszyklus des Cursors
Wir können den Lebenszyklus eines Cursors in beschreiben fünf verschiedene Abschnitte wie folgt:
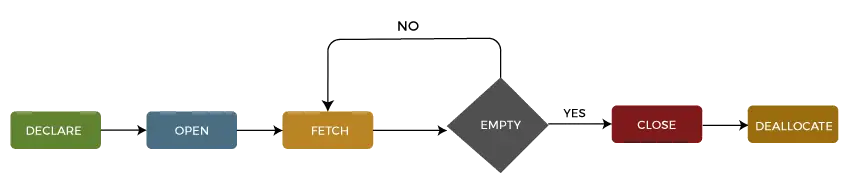
1: Cursor deklarieren
Der erste Schritt besteht darin, den Cursor mit der folgenden SQL-Anweisung zu deklarieren:
Ubuntu-Build-Grundlagen
DECLARE cursor_name CURSOR FOR select_statement;
Wir können einen Cursor deklarieren, indem wir seinen Namen mit dem Datentyp CURSOR nach dem Schlüsselwort DECLARE angeben. Anschließend schreiben wir die SELECT-Anweisung, die die Ausgabe für den Cursor definiert.
2: Cursor öffnen
Es ist ein zweiter Schritt, in dem wir den Cursor öffnen, um aus der Ergebnismenge abgerufene Daten zu speichern. Wir können dies tun, indem wir die folgende SQL-Anweisung verwenden:
OPEN cursor_name;
3: Cursor abrufen
Es handelt sich um einen dritten Schritt, in dem Zeilen einzeln oder in einem Block abgerufen werden können, um Datenmanipulationen wie Einfüge-, Aktualisierungs- und Löschvorgänge für die aktuell aktive Zeile im Cursor durchzuführen. Wir können dies tun, indem wir die folgende SQL-Anweisung verwenden:
FETCH NEXT FROM cursor INTO variable_list;
Wir können auch die verwenden @@FETCHSTATUS-Funktion in SQL Server, um den Status des letzten FETCH-Anweisungscursors abzurufen, der für den Cursor ausgeführt wurde. Der BRINGEN Die Anweisung war erfolgreich, wenn @@FETCHSTATUS keine Ausgabe liefert. Der WÄHREND Mit der Anweisung können alle Datensätze vom Cursor abgerufen werden. Der folgende Code erklärt es deutlicher:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Cursor schließen
Es ist ein vierter Schritt, in dem der Cursor geschlossen werden sollte, nachdem wir die Arbeit mit einem Cursor beendet haben. Wir können dies tun, indem wir die folgende SQL-Anweisung verwenden:
CLOSE cursor_name;
5: Cursor freigeben
Dies ist der fünfte und letzte Schritt, in dem wir die Cursordefinition löschen und alle mit dem Cursor verbundenen Systemressourcen freigeben. Wir können dies tun, indem wir die folgende SQL-Anweisung verwenden:
DEALLOCATE cursor_name;
Verwendung des SQL Server-Cursors
Wir wissen, dass relationale Datenbankverwaltungssysteme, einschließlich SQL Server, Daten in einer Reihe von Zeilen, den sogenannten Ergebnismengen, hervorragend verarbeiten können. Zum Beispiel , wir haben einen Tisch Produkttabelle das die Produktbeschreibungen enthält. Wenn wir das aktualisieren möchten Preis des Produkts, dann das untenstehende ' AKTUALISIEREN' Die Abfrage aktualisiert alle Datensätze, die der Bedingung im ' entsprechen. WO' Klausel:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Manchmal muss die Anwendung die Zeilen im Singleton-Modus verarbeiten, d. h. Zeile für Zeile und nicht den gesamten Ergebnissatz auf einmal. Wir können diesen Prozess durchführen, indem wir Cursor in SQL Server verwenden. Bevor wir den Cursor verwenden, müssen wir wissen, dass Cursor eine sehr schlechte Leistung haben. Sie sollten sie daher immer nur verwenden, wenn außer dem Cursor keine Option vorhanden ist.
Der Cursor verwendet die gleiche Technik wie wir Schleifen wie FOREACH, FOR, WHILE, DO WHILE verwenden, um in allen Programmiersprachen jeweils ein Objekt zu iterieren. Daher könnte es gewählt werden, weil es die gleiche Logik anwendet wie der Schleifenprozess der Programmiersprache.
Arten von Cursorn in SQL Server
Im Folgenden sind die verschiedenen Arten von Cursorn in SQL Server aufgeführt:
- Statische Cursor
- Dynamische Cursor
- Nur-Vorwärts-Cursor
- Keyset-Cursor

Statische Cursor
Die vom statischen Cursor angezeigte Ergebnismenge ist immer dieselbe wie beim ersten Öffnen des Cursors. Da der statische Cursor das Ergebnis speichert tempdb , Sie sind immer schreibgeschützt . Mit dem statischen Cursor können wir uns sowohl vorwärts als auch rückwärts bewegen. Im Gegensatz zu anderen Cursorn ist er langsamer und verbraucht mehr Speicher. Daher können wir es nur verwenden, wenn ein Bildlauf erforderlich ist und andere Cursor nicht geeignet sind.
Dieser Cursor zeigt Zeilen an, die nach dem Öffnen aus der Datenbank entfernt wurden. Ein statischer Cursor stellt keine INSERT-, UPDATE- oder DELETE-Vorgänge dar (es sei denn, der Cursor wird geschlossen und erneut geöffnet).
Dynamische Cursor
Die dynamischen Cursor sind das Gegenteil der statischen Cursor, die es uns ermöglichen, Datenaktualisierungs-, Lösch- und Einfügevorgänge durchzuführen, während der Cursor geöffnet ist. Es ist Standardmäßig scrollbar . Es kann alle an den Zeilen, der Reihenfolge und den Werten im Ergebnissatz vorgenommenen Änderungen erkennen, unabhängig davon, ob die Änderungen innerhalb oder außerhalb des Cursors erfolgen. Außerhalb des Cursors können wir die Aktualisierungen erst sehen, wenn sie festgeschrieben werden.
Nur-Vorwärts-Cursor
Es ist der standardmäßige und schnellste Cursortyp unter allen Cursorn. Er wird als Nur-Vorwärts-Cursor bezeichnet, weil er bewegt sich nur vorwärts durch die Ergebnismenge . Dieser Cursor unterstützt kein Scrollen. Es können nur Zeilen vom Anfang bis zum Ende der Ergebnismenge abgerufen werden. Es ermöglicht uns, Einfüge-, Aktualisierungs- und Löschvorgänge durchzuführen. Hier sind die Auswirkungen von Einfüge-, Aktualisierungs- und Löschvorgängen des Benutzers, die sich auf Zeilen im Ergebnissatz auswirken, sichtbar, wenn die Zeilen vom Cursor abgerufen werden. Beim Abrufen der Zeile können wir die an den Zeilen vorgenommenen Änderungen nicht über den Cursor sehen.
Die Nur-Vorwärts-Cursor werden in drei Typen eingeteilt:
js onclick
- Forward_Only-Schlüsselsatz
- Forward_Only Statisch
- Fast_Forward

Keyset-gesteuerte Cursor
Diese Cursor-Funktionalität liegt zwischen einem statischen und einem dynamischen Cursor hinsichtlich seiner Fähigkeit, Veränderungen zu erkennen. Es kann nicht immer Änderungen in der Zugehörigkeit und Reihenfolge der Ergebnismenge erkennen wie ein statischer Cursor. Es kann Änderungen in den Zeilenwerten der Ergebnismenge wie ein dynamischer Cursor erkennen. Es kann nur Gehen Sie von der ersten zur letzten und von der letzten zur ersten Reihe . Beim Öffnen dieses Cursors werden die Reihenfolge und die Mitgliedschaft fixiert.
Es wird über eine Reihe eindeutiger Kennungen betrieben, die mit den Schlüsseln im Schlüsselsatz identisch sind. Der Schlüsselsatz wird durch alle Zeilen bestimmt, die die SELECT-Anweisung qualifiziert haben, als der Cursor zum ersten Mal geöffnet wurde. Es kann auch alle Änderungen an der Datenquelle erkennen, die Aktualisierungs- und Löschvorgänge unterstützt. Es ist standardmäßig scrollbar.
Implementierung von Beispiel
Lassen Sie uns das Cursor-Beispiel im SQL Server implementieren. Wir können dies tun, indem wir zunächst eine Tabelle mit dem Namen „ Kunde ' mit der folgenden Anweisung:
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Als nächstes fügen wir Werte in die Tabelle ein. Wir können die folgende Anweisung ausführen, um Daten zu einer Tabelle hinzuzufügen:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Wir können die Daten überprüfen, indem wir Folgendes ausführen WÄHLEN Stellungnahme:
SELECT * FROM customer;
Nachdem wir die Abfrage ausgeführt haben, können wir die folgende Ausgabe sehen, wo wir sie haben acht Reihen in die Tabelle:

Jetzt erstellen wir einen Cursor, um die Kundendatensätze anzuzeigen. Die folgenden Codeausschnitte erläutern alle Schritte der Cursordeklaration oder -erstellung, indem sie alles zusammenfügen:
dynamisches Array Java
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Nachdem wir einen Cursor ausgeführt haben, erhalten wir die folgende Ausgabe:

Einschränkungen des SQL Server-Cursors
Ein Cursor hat einige Einschränkungen, sodass er immer nur verwendet werden sollte, wenn außer dem Cursor keine Option vorhanden ist. Diese Einschränkungen sind:
- Cursor verbraucht Netzwerkressourcen, indem er jedes Mal, wenn er einen Datensatz abruft, einen Netzwerk-Roundtrip erfordert.
- Ein Cursor ist eine speicherresidente Menge von Zeigern, was bedeutet, dass er Speicher beansprucht, den andere Prozesse auf unserem Computer nutzen könnten.
- Beim Verarbeiten von Daten werden Sperren für einen Teil der Tabelle oder die gesamte Tabelle verhängt.
- Die Leistung und Geschwindigkeit des Cursors ist langsamer, da Tabellendatensätze jeweils zeilenweise aktualisiert werden.
- Cursor sind schneller als While-Schleifen, haben aber auch mehr Overhead.
- Die Anzahl der Zeilen und Spalten, die in den Cursor gebracht werden, ist ein weiterer Aspekt, der die Cursorgeschwindigkeit beeinflusst. Es bezieht sich darauf, wie lange es dauert, den Cursor zu öffnen und eine Abrufanweisung auszuführen.
Wie können wir Cursor vermeiden?
Die Hauptaufgabe von Cursorn besteht darin, die Tabelle Zeile für Zeile zu durchlaufen. Nachfolgend finden Sie die einfachste Möglichkeit, Cursor zu vermeiden:
Verwendung der SQL-while-Schleife
Der einfachste Weg, die Verwendung eines Cursors zu vermeiden, ist die Verwendung einer While-Schleife, die das Einfügen einer Ergebnismenge in die temporäre Tabelle ermöglicht.
Benutzerdefinierte Funktionen
Manchmal werden Cursor verwendet, um den resultierenden Zeilensatz zu berechnen. Wir können dies erreichen, indem wir eine benutzerdefinierte Funktion verwenden, die den Anforderungen entspricht.
Verwenden von Joins
Join verarbeitet nur die Spalten, die die angegebene Bedingung erfüllen, und reduziert somit die Codezeilen, die eine schnellere Leistung als Cursor bieten, falls große Datensätze verarbeitet werden müssen.