Es gibt zwei Arten von Prozessen:
- Unabhängiger Prozess.
- Kooperationsprozess.
Ein unabhängiger Prozess wird von der Ausführung anderer Prozesse nicht beeinflusst, während ein kooperierender Prozess von anderen ausführenden Prozessen beeinflusst werden kann. Obwohl man davon ausgehen kann, dass diese unabhängig voneinander ablaufenden Prozesse sehr effizient ablaufen, gibt es in der Realität viele Situationen, in denen der kooperative Charakter zur Erhöhung der Rechengeschwindigkeit, des Komforts und der Modularität genutzt werden kann. Interprozesskommunikation (IPC) ist ein Mechanismus, der es Prozessen ermöglicht, miteinander zu kommunizieren und ihre Aktionen zu synchronisieren. Die Kommunikation zwischen diesen Prozessen kann als eine Methode der Zusammenarbeit zwischen ihnen angesehen werden. Prozesse können über beides miteinander kommunizieren:
- Geteilte Erinnerung
- Nachrichtenübermittlung
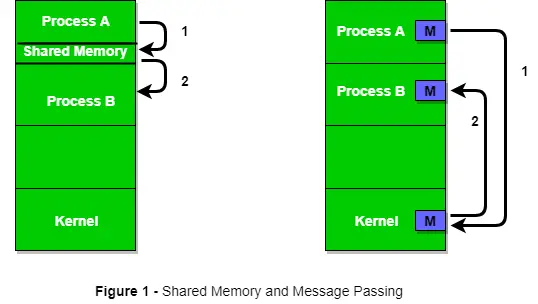
Abbildung 1 unten zeigt eine Grundstruktur der Kommunikation zwischen Prozessen über die Shared-Memory-Methode und über die Message-Passing-Methode.
Ein Betriebssystem kann beide Kommunikationsmethoden implementieren. Zuerst besprechen wir die Shared-Memory-Kommunikationsmethoden und dann die Nachrichtenübermittlung. Die Kommunikation zwischen Prozessen, die gemeinsam genutzten Speicher nutzen, erfordert, dass Prozesse eine Variable gemeinsam nutzen, und es hängt vollständig davon ab, wie der Programmierer sie implementiert. Eine Art der Kommunikation mithilfe des Shared Memory kann man sich wie folgt vorstellen: Angenommen, Prozess1 und Prozess2 werden gleichzeitig ausgeführt und sie teilen sich einige Ressourcen oder nutzen einige Informationen von einem anderen Prozess. Prozess1 generiert Informationen über bestimmte Berechnungen oder verwendete Ressourcen und speichert sie als Datensatz im gemeinsam genutzten Speicher. Wenn Prozess2 die gemeinsam genutzten Informationen verwenden muss, checkt er den im gemeinsam genutzten Speicher gespeicherten Datensatz ein, nimmt die von Prozess1 generierten Informationen zur Kenntnis und handelt entsprechend. Prozesse können Shared Memory zum Extrahieren von Informationen als Datensatz aus einem anderen Prozess sowie zum Übermitteln spezifischer Informationen an andere Prozesse verwenden.
Lassen Sie uns ein Beispiel für die Kommunikation zwischen Prozessen mithilfe der Shared-Memory-Methode diskutieren.
i) Shared-Memory-Methode
Beispiel: Producer-Consumer-Problem
Es gibt zwei Prozesse: Produzent und Verbraucher. Der Produzent produziert einige Artikel und der Verbraucher konsumiert diesen Artikel. Die beiden Prozesse teilen sich einen gemeinsamen Raum oder Speicherort, der als Puffer bezeichnet wird, in dem der vom Produzenten produzierte Artikel gespeichert wird und von dem aus der Verbraucher den Artikel bei Bedarf konsumiert. Es gibt zwei Versionen dieses Problems: Die erste ist als Problem des unbegrenzten Puffers bekannt, bei dem der Produzent weiterhin Elemente produzieren kann und es keine Begrenzung für die Größe des Puffers gibt, die zweite Version ist als Problem des begrenzten Puffers bekannt Dabei kann der Produzent bis zu einer bestimmten Anzahl von Artikeln produzieren, bevor er darauf wartet, dass der Verbraucher sie verbraucht. Wir werden das Problem des begrenzten Puffers diskutieren. Zunächst teilen der Produzent und der Verbraucher ein gemeinsames Gedächtnis, dann beginnt der Produzent mit der Produktion von Artikeln. Wenn der insgesamt produzierte Artikel der Größe des Puffers entspricht, wartet der Produzent darauf, dass er vom Verbraucher verbraucht wird. Ebenso prüft der Verbraucher zunächst die Verfügbarkeit des Artikels. Wenn kein Artikel verfügbar ist, wartet der Verbraucher darauf, dass der Produzent ihn produziert. Wenn Artikel verfügbar sind, wird der Verbraucher diese konsumieren. Der zu demonstrierende Pseudocode ist unten aufgeführt:
Gemeinsame Daten zwischen den beiden Prozessen
C
#define buff_max 25> #define mod %> >struct> item{> >// different member of the produced data> >// or consumed data> >---------> >}> > >// An array is needed for holding the items.> >// This is the shared place which will be> >// access by both process> >// item shared_buff [ buff_max ];> > >// Two variables which will keep track of> >// the indexes of the items produced by producer> >// and consumer The free index points to> >// the next free index. The full index points to> >// the first full index.> >int> free_index = 0;> >int> full_index = 0;> > |
>
>
Produzentenprozesscode
C
item nextProduced;> > >while>(1){> > >// check if there is no space> >// for production.> >// if so keep waiting.> >while>((free_index+1) mod buff_max == full_index);> > >shared_buff[free_index] = nextProduced;> >free_index = (free_index + 1) mod buff_max;> >}> |
>
>
Verbraucherprozesscode
C
item nextConsumed;> > >while>(1){> > >// check if there is an available> >// item for consumption.> >// if not keep on waiting for> >// get them produced.> >while>((free_index == full_index);> > >nextConsumed = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >}> |
>
>
Im obigen Code beginnt der Produzent erneut mit der Produktion, wenn der maximale Mod-Buff (free_index+1) frei ist, denn wenn er nicht frei ist, bedeutet dies, dass es noch Elemente gibt, die vom Verbraucher konsumiert werden können, sodass kein Bedarf besteht mehr zu produzieren. Wenn der freie Index und der vollständige Index auf denselben Index verweisen, bedeutet dies ebenfalls, dass keine Elemente zum Konsumieren vorhanden sind.
Gesamtimplementierung von C++:
C++
#include> #include> #include> #include> #define buff_max 25> #define mod %> struct> item {> >// different member of the produced data> >// or consumed data> >// ---------> };> // An array is needed for holding the items.> // This is the shared place which will be> // access by both process> // item shared_buff[buff_max];> // Two variables which will keep track of> // the indexes of the items produced by producer> // and consumer The free index points to> // the next free index. The full index points to> // the first full index.> std::atomic<>int>>free_index(0);> std::atomic<>int>>full_index(0);> std::mutex mtx;> void> producer() {> >item new_item;> >while> (>true>) {> >// Produce the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >// Add the item to the buffer> >while> (((free_index + 1) mod buff_max) == full_index) {> >// Buffer is full, wait for consumer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Add the item to the buffer> >// shared_buff[free_index] = new_item;> >free_index = (free_index + 1) mod buff_max;> >mtx.unlock();> >}> }> void> consumer() {> >item consumed_item;> >while> (>true>) {> >while> (free_index == full_index) {> >// Buffer is empty, wait for producer> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> >mtx.lock();> >// Consume the item from the buffer> >// consumed_item = shared_buff[full_index];> >full_index = (full_index + 1) mod buff_max;> >mtx.unlock();> >// Consume the item> >// ...> >std::this_thread::sleep_for(std::chrono::milliseconds(100));> >}> }> int> main() {> >// Create producer and consumer threads> >std::vectorthread>Fäden; threads.emplace_back(producer); threads.emplace_back(consumer); // Warten, bis Threads beendet sind for (auto& thread : threads) { thread.join(); } return 0; }> |
>
>
Java-Objektgleichheit
Beachten Sie, dass die atomare Klasse verwendet wird, um sicherzustellen, dass die gemeinsam genutzten Variablen free_index und full_index atomar aktualisiert werden. Der Mutex wird verwendet, um den kritischen Abschnitt zu schützen, in dem auf den gemeinsam genutzten Puffer zugegriffen wird. Die Funktion „sleep_for“ wird verwendet, um die Produktion und den Verbrauch von Artikeln zu simulieren.
ii) Messaging-Weiterleitungsmethode
Jetzt beginnen wir mit der Diskussion der Kommunikation zwischen Prozessen über die Nachrichtenübermittlung. Bei dieser Methode kommunizieren Prozesse miteinander, ohne einen gemeinsamen Speicher zu nutzen. Wenn zwei Prozesse p1 und p2 miteinander kommunizieren wollen, gehen sie wie folgt vor:
- Stellen Sie eine Kommunikationsverbindung her (falls bereits eine Verbindung besteht, muss diese nicht erneut hergestellt werden.)
- Beginnen Sie mit dem Austausch von Nachrichten mithilfe grundlegender Grundelemente.
Wir brauchen mindestens zwei Grundelemente:
– schicken (Nachricht, Ziel) oder schicken (Nachricht)
– erhalten (Nachricht, Host) oder erhalten (Nachricht)

Die Nachrichtengröße kann eine feste Größe oder eine variable Größe haben. Wenn es eine feste Größe hat, ist es für einen Betriebssystem-Designer einfach, aber kompliziert für einen Programmierer, und wenn es eine variable Größe hat, ist es für einen Programmierer einfach, aber für einen Betriebssystem-Designer kompliziert. Eine Standardnachricht kann aus zwei Teilen bestehen: Kopf und Körper.
Der Kopfteil wird zum Speichern von Nachrichtentyp, Ziel-ID, Quell-ID, Nachrichtenlänge und Steuerinformationen verwendet. Die Steuerinformationen enthalten Informationen wie die Vorgehensweise, wenn der Pufferspeicher knapp wird, die Sequenznummer und die Priorität. Im Allgemeinen werden Nachrichten im FIFO-Stil gesendet.
Nachrichtenübermittlung über Kommunikationsverbindung.
Direkte und indirekte Kommunikationsverbindung
Nun beginnen wir unsere Diskussion über die Methoden zur Implementierung von Kommunikationsverbindungen. Bei der Implementierung des Links müssen einige Fragen beachtet werden, wie zum Beispiel:
- Wie werden Links hergestellt?
- Kann ein Link mehr als zwei Prozessen zugeordnet werden?
- Wie viele Verbindungen kann es zwischen jedem Paar kommunizierender Prozesse geben?
- Welche Kapazität hat ein Link? Ist die Größe einer Nachricht, die der Link aufnehmen kann, fest oder variabel?
- Ist eine Verbindung unidirektional oder bidirektional?
Eine Verbindung verfügt über eine gewisse Kapazität, die die Anzahl der Nachrichten bestimmt, die sich vorübergehend darin befinden können. Jedem Link ist eine Warteschlange zugeordnet, die eine Kapazität von Null, eine begrenzte Kapazität oder eine unbegrenzte Kapazität haben kann. Bei Nullkapazität wartet der Sender, bis der Empfänger den Sender darüber informiert, dass er die Nachricht erhalten hat. In Fällen mit einer Kapazität ungleich Null weiß ein Prozess nach dem Sendevorgang nicht, ob eine Nachricht empfangen wurde oder nicht. Hierzu muss der Sender explizit mit dem Empfänger kommunizieren. Die Implementierung der Verbindung hängt von der Situation ab und kann entweder eine direkte Kommunikationsverbindung oder eine indirekte Kommunikationsverbindung sein.
Direkte Kommunikationslinks werden implementiert, wenn die Prozesse eine bestimmte Prozesskennung für die Kommunikation verwenden, es jedoch schwierig ist, den Absender im Voraus zu identifizieren.
Zum Beispiel der Druckserver.
Indirekte Kommunikation erfolgt über ein gemeinsames Postfach (Port), das aus einer Warteschlange von Nachrichten besteht. Der Absender bewahrt die Nachricht im Briefkasten auf und der Empfänger holt sie ab.
Message Passing durch Austausch der Nachrichten.
Synchrone und asynchrone Nachrichtenübermittlung:
Ein blockierter Prozess ist ein Prozess, der auf ein Ereignis wartet, beispielsweise die Verfügbarkeit einer Ressource oder den Abschluss eines E/A-Vorgangs. IPC ist sowohl zwischen den Prozessen auf demselben Computer als auch auf den Prozessen möglich, die auf verschiedenen Computern, d. h. in einem vernetzten/verteilten System, ausgeführt werden. In beiden Fällen kann der Prozess beim Senden einer Nachricht oder beim Versuch, eine Nachricht zu empfangen, blockiert sein oder auch nicht, sodass die Nachrichtenübermittlung blockierend oder nicht blockierend sein kann. Eine Sperrung wird berücksichtigt synchron Und Senden blockieren bedeutet, dass der Absender blockiert wird, bis die Nachricht beim Empfänger eingeht. Ähnlich, Empfang blockieren hat den Empfänger blockiert, bis eine Nachricht verfügbar ist. Nicht-blockierend wird berücksichtigt asynchron und „Nicht blockierendes Senden“ bedeutet, dass der Absender die Nachricht sendet und fortfährt. In ähnlicher Weise empfängt der Empfänger beim nicht blockierenden Empfang eine gültige Nachricht oder eine Null. Nach einer sorgfältigen Analyse können wir zu dem Schluss kommen, dass es für einen Absender natürlicher ist, nach der Nachrichtenübermittlung nicht blockierend zu sein, da möglicherweise die Notwendigkeit besteht, die Nachricht an verschiedene Prozesse zu senden. Der Absender erwartet jedoch eine Bestätigung vom Empfänger, falls der Versand fehlschlägt. Ebenso ist es für einen Empfänger natürlicher, nach der Ausgabe des Empfangs zu blockieren, da die Informationen aus der empfangenen Nachricht für die weitere Ausführung verwendet werden können. Wenn gleichzeitig der Nachrichtenversand weiterhin fehlschlägt, muss der Empfänger auf unbestimmte Zeit warten. Deshalb ziehen wir auch die andere Möglichkeit der Nachrichtenübermittlung in Betracht. Grundsätzlich gibt es drei bevorzugte Kombinationen:
- Senden und Empfangen blockieren
- Nicht blockierendes Senden und nicht blockierendes Empfangen
- Nicht blockierendes Senden und blockierendes Empfangen (meistens verwendet)
Bei der Weitergabe von Direktnachrichten , Der Prozess, der kommunizieren möchte, muss den Empfänger oder Absender der Kommunikation explizit benennen.
z.B. send(p1, Nachricht) bedeutet, die Nachricht an p1 zu senden.
Ähnlich, Erhalte (p2, Nachricht) bedeutet, die Nachricht von p2 zu empfangen.
Bei dieser Kommunikationsmethode wird die Kommunikationsverbindung automatisch hergestellt, die entweder unidirektional oder bidirektional sein kann, aber eine Verbindung kann zwischen einem Sender-Empfänger-Paar verwendet werden und ein Sender-Empfänger-Paar sollte nicht mehr als ein Paar besitzen Links. Symmetrie und Asymmetrie zwischen Senden und Empfangen können ebenfalls implementiert werden, d. h. entweder benennen sich beide Prozesse gegenseitig zum Senden und Empfangen der Nachrichten, oder nur der Sender benennt den Empfänger zum Senden der Nachricht und es besteht keine Notwendigkeit für den Empfänger, den Sender zu benennen Empfangen der Nachricht. Das Problem bei dieser Kommunikationsmethode besteht darin, dass diese Methode nicht funktioniert, wenn sich der Name eines Prozesses ändert.
Bei der indirekten Nachrichtenübermittlung , Prozesse verwenden Postfächer (auch als Ports bezeichnet) zum Senden und Empfangen von Nachrichten. Jedes Postfach hat eine eindeutige ID und Prozesse können nur kommunizieren, wenn sie ein Postfach gemeinsam nutzen. Die Verbindung wird nur hergestellt, wenn Prozesse ein gemeinsames Postfach nutzen und ein einzelner Link vielen Prozessen zugeordnet werden kann. Jedes Prozesspaar kann mehrere Kommunikationsverbindungen gemeinsam nutzen und diese Verbindungen können unidirektional oder bidirektional sein. Angenommen, zwei Prozesse möchten über die indirekte Nachrichtenübermittlung kommunizieren. Die erforderlichen Vorgänge sind: Erstellen eines Postfachs, Verwenden dieses Postfachs zum Senden und Empfangen von Nachrichten und anschließendes Zerstören des Postfachs. Die verwendeten Standardprimitive sind: eine Nachricht schicken) was bedeutet, dass die Nachricht an Mailbox A gesendet wird. Das Primitiv zum Empfangen der Nachricht funktioniert ebenfalls auf die gleiche Weise, z. B. empfangen (A, Nachricht) . Bei dieser Postfachimplementierung liegt ein Problem vor. Angenommen, es gibt mehr als zwei Prozesse, die sich dasselbe Postfach teilen, und angenommen, der Prozess p1 sendet eine Nachricht an das Postfach. Welcher Prozess wird der Empfänger sein? Dies kann gelöst werden, indem entweder erzwungen wird, dass nur zwei Prozesse ein einzelnes Postfach gemeinsam nutzen können, oder indem erzwungen wird, dass nur ein Prozess den Empfang zu einem bestimmten Zeitpunkt ausführen darf, oder indem man einen beliebigen Prozess zufällig auswählt und den Absender über den Empfänger benachrichtigt. Ein Postfach kann für ein einzelnes Sender/Empfänger-Paar privat gemacht werden und kann auch von mehreren Sender/Empfänger-Paaren gemeinsam genutzt werden. Port ist eine Implementierung eines solchen Postfachs, das mehrere Absender und einen einzelnen Empfänger haben kann. Es wird in Client/Server-Anwendungen verwendet (in diesem Fall ist der Server der Empfänger). Der Port ist Eigentum des empfangenden Prozesses und wird vom Betriebssystem auf Anfrage des Empfängerprozesses erstellt und kann entweder auf Anfrage desselben Empfängerprozessors zerstört werden, wenn der Empfänger sich selbst beendet. Um zu erzwingen, dass nur ein Prozess den Empfang ausführen darf, kann das Konzept des gegenseitigen Ausschlusses verwendet werden. Mutex-Postfach wird erstellt, das von n Prozessen gemeinsam genutzt wird. Der Absender blockiert nicht und sendet die Nachricht. Der erste Prozess, der den Empfang ausführt, gelangt in den kritischen Abschnitt und alle anderen Prozesse blockieren und warten.
Lassen Sie uns nun das Producer-Consumer-Problem anhand des Message-Passing-Konzepts diskutieren. Der Produzent platziert Elemente (in Nachrichten) im Postfach und der Verbraucher kann ein Element konsumieren, wenn mindestens eine Nachricht im Postfach vorhanden ist. Der Code ist unten angegeben:
Produzentencode
C
void> Producer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Consumer, &m);> >item = produce();> >build_message(&m , item ) ;> >send(Consumer, &m);> >}> >}> |
>
>
Verbrauchergesetzbuch
C
void> Consumer(>void>){> > >int> item;> >Message m;> > >while>(1){> > >receive(Producer, &m);> >item = extracted_item();> >send(Producer, &m);> >consume_item(item);> >}> >}> |
>
>
Beispiele für IPC-Systeme
- Posix: verwendet die Shared-Memory-Methode.
- Mach: nutzt Message-Passing
- Windows XP: nutzt die Nachrichtenübermittlung mithilfe lokaler prozeduraler Aufrufe
Kommunikation in Client/Server-Architektur:
Es gibt verschiedene Mechanismen:
- Rohr
- Steckdose
- Remote-Prozeduraufrufe (RPCs)
Die oben genannten drei Methoden werden in späteren Artikeln besprochen, da sie alle recht konzeptionell sind und einen eigenen separaten Artikel verdienen.
Verweise:
- Betriebssystemkonzepte von Galvin et al.
- Vorlesungsskript/ppt von Ariel J. Frank, Bar-Ilan-Universität
Interprozesskommunikation (IPC) ist der Mechanismus, über den Prozesse oder Threads auf einem Computer oder über ein Netzwerk miteinander kommunizieren und Daten austauschen können. IPC ist ein wichtiger Aspekt moderner Betriebssysteme, da es die Zusammenarbeit verschiedener Prozesse und die gemeinsame Nutzung von Ressourcen ermöglicht, was zu mehr Effizienz und Flexibilität führt.
Vorteile von IPC:
- Ermöglicht die Kommunikation von Prozessen untereinander und die gemeinsame Nutzung von Ressourcen, was zu mehr Effizienz und Flexibilität führt.
- Erleichtert die Koordination zwischen mehreren Prozessen und führt so zu einer besseren Gesamtsystemleistung.
- Ermöglicht die Erstellung verteilter Systeme, die mehrere Computer oder Netzwerke umfassen können.
- Kann zur Implementierung verschiedener Synchronisations- und Kommunikationsprotokolle wie Semaphoren, Pipes und Sockets verwendet werden.
Nachteile von IPC:
- Erhöht die Systemkomplexität und erschwert das Entwerfen, Implementieren und Debuggen.
- Kann zu Sicherheitslücken führen, da Prozesse möglicherweise auf Daten anderer Prozesse zugreifen oder diese ändern können.
- Erfordert eine sorgfältige Verwaltung der Systemressourcen wie Speicher und CPU-Zeit, um sicherzustellen, dass IPC-Vorgänge die Gesamtsystemleistung nicht beeinträchtigen.
Kann zu Dateninkonsistenzen führen, wenn mehrere Prozesse gleichzeitig versuchen, auf dieselben Daten zuzugreifen oder diese zu ändern. - Insgesamt überwiegen die Vorteile von IPC die Nachteile, da es sich um einen notwendigen Mechanismus für moderne Betriebssysteme handelt und es Prozessen ermöglicht, flexibel und effizient zusammenzuarbeiten und Ressourcen zu teilen. Es muss jedoch darauf geachtet werden, IPC-Systeme sorgfältig zu entwerfen und zu implementieren, um potenzielle Sicherheitslücken und Leistungsprobleme zu vermeiden.
Weitere Referenz:
http://nptel.ac.in/courses/106108101/pdf/Lecture_Notes/Mod%207_LN.pdf
https://www.youtube.com/watch?v=lcRqHwIn5Dk