- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>Wo,
– X stellt den Datensatz von Werten dar – Mittelwert(x) stellt den Mittelwert des Datensatzes dar X . Der Standardwert ist 0.>– sd(x) stellt die Standardabweichung des Datensatzes dar X . Der Standardwert ist 1.>– N ist die Anzahl der Beobachtungen. – P ist ein Wahrscheinlichkeitsvektor
Funktionen zum Erzeugen einer Normalverteilung in R
dnorm()
dnorm()> Funktion in der R-Programmierung misst die Dichtefunktion der Verteilung. In der Statistik wird es mit der folgenden Formel gemessen:>Wo,
 ist gemein und
ist gemein und 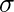 ist die Standardabweichung. Syntax :
ist die Standardabweichung. Syntax : dnorm(x, mean, sd)>Beispiel:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Ausgabe:
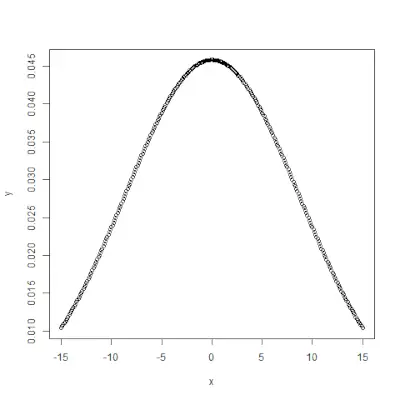
pnorm()
pnorm()> Funktion ist die kumulative Verteilungsfunktion, die die Wahrscheinlichkeit misst, dass eine Zufallszahl X einen Wert kleiner oder gleich x annimmt, d. h. in der Statistik wird sie gegeben durch:>Syntax:
pnorm(x, mean, sd)>Beispiel:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Ausgabe :
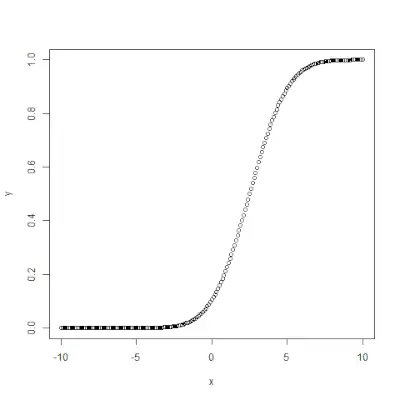
qnorm()
qnorm()> Funktion ist die Umkehrung von pnorm()>Funktion. Es nimmt den Wahrscheinlichkeitswert und gibt eine Ausgabe aus, die dem Wahrscheinlichkeitswert entspricht. Es ist nützlich, um die Perzentile einer Normalverteilung zu ermitteln. Syntax: qnorm(p, mean, sd)>Beispiel:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Ausgabe:
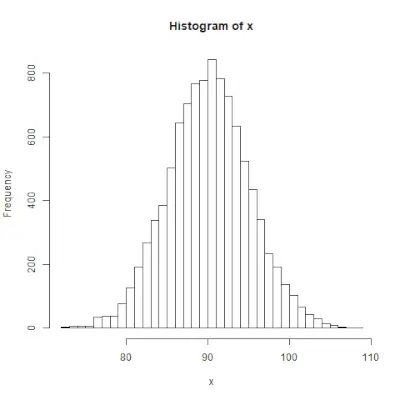
rnorm()
rnorm()> Die Funktion in der R-Programmierung wird verwendet, um einen Vektor normalverteilter Zufallszahlen zu generieren. Syntax: rnorm(x, mean, sd)>Beispiel:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Ausgabe :