Im Betriebssystem mussten wir die Eingabe an die CPU übergeben, und die CPU führt die Anweisungen aus und gibt schließlich die Ausgabe aus. Bei diesem Ansatz gab es jedoch ein Problem. In einer normalen Situation müssen wir uns mit vielen Prozessen befassen, und wir wissen, dass die Zeit, die für den E/A-Vorgang benötigt wird, im Vergleich zu der Zeit, die die CPU für die Ausführung der Anweisungen benötigt, sehr groß ist. Beim alten Ansatz gibt also ein Prozess die Eingabe mithilfe eines Eingabegeräts ein, und während dieser Zeit befindet sich die CPU in einem Leerlaufzustand.
Heap-Sortierung
Dann führt die CPU den Befehl aus und die Ausgabe wird erneut an ein Ausgabegerät übergeben. Zu diesem Zeitpunkt befindet sich die CPU ebenfalls im Ruhezustand. Nachdem die Ausgabe angezeigt wurde, beginnt der nächste Prozess mit der Ausführung. Daher ist die CPU die meiste Zeit im Leerlauf, was der schlimmste Zustand ist, den wir in Betriebssystemen haben können. Hier kommt das Konzept des Spoolings ins Spiel.
Was ist Spoolen?
Spooling ist ein Prozess, bei dem Daten vorübergehend für die Verwendung und Ausführung durch ein Gerät, Programm oder System gespeichert werden. Daten werden an den Arbeitsspeicher oder einen anderen flüchtigen Speicher gesendet und dort gespeichert, bis das Programm oder der Computer sie zur Ausführung anfordert.
SPOOL ist ein Akronym für gleichzeitige periphere Operationen online . Im Allgemeinen wird der Spool im physischen Speicher, in den Puffern oder in den E/A-gerätespezifischen Interrupts des Computers verwaltet. Der Spool wird in aufsteigender Reihenfolge verarbeitet und basiert auf einem FIFO-Algorithmus (First-In, First-Out).
Unter Spooling versteht man das Ablegen von Daten verschiedener I/O-Jobs in einem Puffer. Dieser Puffer ist ein spezieller Bereich im Speicher oder auf der Festplatte, auf den E/A-Geräte zugreifen können. Ein Betriebssystem führt die folgenden Aktivitäten im Zusammenhang mit der verteilten Umgebung aus:
- Verwaltet das Spoolen von E/A-Gerätedaten, da Geräte unterschiedliche Datenzugriffsraten haben.
- Verwaltet den Spool-Puffer, der eine Wartestation bietet, in der Daten ruhen können, während das langsamere Gerät aufholt.
- Behält parallele Berechnungen aufgrund des Spooling-Prozesses bei, da ein Computer E/A in paralleler Reihenfolge ausführen kann. Es wird möglich, dass der Computer Daten von einem Band liest, Daten auf die Festplatte schreibt und auf einen Banddrucker schreibt, während er seine Rechenaufgabe erledigt.
Funktionsweise des Spoolens im Betriebssystem
In einem Betriebssystem funktioniert das Spoolen in den folgenden Schritten, wie zum Beispiel:
- Beim Spoolen wird ein Puffer namens SPOOL erstellt, der zum Zurückhalten von Jobs und Daten verwendet wird, bis das Gerät, in dem der SPOOL erstellt wird, bereit ist, diesen Job zu verwenden und auszuführen oder mit den Daten zu arbeiten.
- Wenn ein schnelleres Gerät Daten an ein langsameres Gerät sendet, um einen Vorgang auszuführen, verwendet es den angeschlossenen sekundären Speicher als SPOOL-Puffer. Diese Daten werden im SPOOL gehalten, bis das langsamere Gerät bereit ist, mit diesen Daten zu arbeiten. Wenn das langsamere Gerät bereit ist, werden die Daten im SPOOL für die erforderlichen Operationen in den Hauptspeicher geladen.
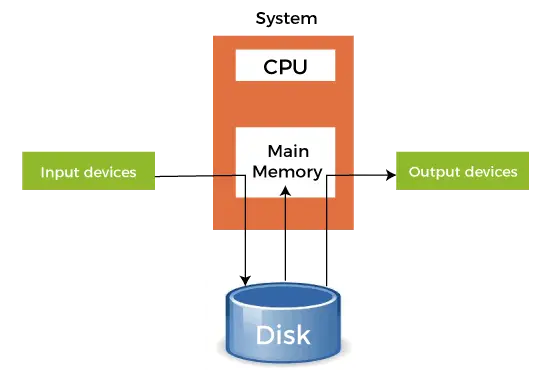
- Beim Spoolen wird der gesamte Sekundärspeicher als riesiger Puffer betrachtet, der viele Jobs und Daten für viele Vorgänge speichern kann. Der Vorteil des Spoolens besteht darin, dass eine Warteschlange von Jobs erstellt werden kann, die in FIFO-Reihenfolge ausgeführt werden, um die Jobs einzeln auszuführen.
- Ein Gerät kann mit vielen Eingabegeräten verbunden werden, was möglicherweise eine Bearbeitung der Daten erfordert. Daher können alle diese Eingabegeräte ihre Daten im Sekundärspeicher (SPOOL) ablegen, die dann vom Gerät einzeln ausgeführt werden können. Dadurch wird sichergestellt, dass die CPU zu keinem Zeitpunkt im Leerlauf ist. Wir können also sagen, dass Spooling eine Kombination aus Pufferung und Warteschlangen ist.
- Nachdem die CPU eine Ausgabe generiert, wird diese Ausgabe zunächst im Hauptspeicher gespeichert. Diese Ausgabe wird vom Hauptspeicher in den Sekundärspeicher übertragen und von dort aus an die jeweiligen Ausgabegeräte gesendet.

Beispiel für Spoolen
Das größte Beispiel für Spooling ist Drucken . Die zu druckenden Dokumente werden im SPOOL abgelegt und anschließend in die Druckwarteschlange gestellt. Während dieser Zeit können viele Prozesse ihre Vorgänge ausführen und die CPU beanspruchen, ohne warten zu müssen, während der Drucker den Druckvorgang für die Dokumente einzeln ausführt.

Dem Spooling-Druckprozess können auch viele Funktionen hinzugefügt werden, z. B. das Festlegen von Prioritäten oder die Benachrichtigung, wenn der Druckvorgang abgeschlossen ist, oder die Auswahl der verschiedenen Papiersorten, auf denen je nach Wunsch des Benutzers gedruckt werden soll.
Vorteile des Spoolens
Hier sind die folgenden Vorteile des Spoolens in einem Betriebssystem, wie zum Beispiel:
Base64-Javascript dekodieren
- Die Anzahl der E/A-Geräte oder Vorgänge spielt keine Rolle. Viele E/A-Geräte können gleichzeitig zusammenarbeiten, ohne dass es zu gegenseitigen Störungen oder Störungen kommt.
- Beim Spoolen gibt es keine Interaktion zwischen den E/A-Geräten und der CPU. Das bedeutet, dass die CPU nicht auf die Ausführung der E/A-Vorgänge warten muss. Die Ausführung solcher Vorgänge dauert lange, sodass die CPU nicht auf deren Abschluss wartet.
- Die CPU im Ruhezustand gilt als nicht sehr effizient. Die meisten Protokolle werden erstellt, um die CPU in kürzester Zeit effizient zu nutzen. Beim Spoolen ist die CPU die meiste Zeit beschäftigt und geht erst in den Ruhezustand, wenn die Warteschlange erschöpft ist. Daher werden alle Aufgaben zur Warteschlange hinzugefügt, und die CPU beendet alle diese Aufgaben und geht dann in den Ruhezustand über.
- Dadurch können Anwendungen mit der Geschwindigkeit der CPU ausgeführt werden, während die E/A-Geräte mit ihrer jeweiligen vollen Geschwindigkeit betrieben werden.
Nachteile des Spoolens
In einem Betriebssystem hat das Spoolen folgende Nachteile, wie zum Beispiel:
- Das Spoolen erfordert eine große Menge an Speicher, abhängig von der Anzahl der von der Eingabe gestellten Anforderungen und der Anzahl der angeschlossenen Eingabegeräte.
- Da der SPOOL im Sekundärspeicher erstellt wird, kann die gleichzeitige Arbeit vieler Eingabegeräte viel Platz auf dem Sekundärspeicher beanspruchen und somit den Festplattenverkehr erhöhen. Dies führt dazu, dass die Festplatte mit zunehmendem Datenverkehr immer langsamer wird.
- Spooling wird zum Kopieren und Ausführen von Daten von einem langsameren Gerät auf ein schnelleres Gerät verwendet. Das langsamere Gerät erstellt einen SPOOL, um die zu bearbeitenden Daten in einer Warteschlange zu speichern, und die CPU arbeitet daran. Dieser Prozess allein macht die Verwendung von Spooling in Echtzeitumgebungen, in denen wir Echtzeitergebnisse von der CPU benötigen, sinnlos. Dies liegt daran, dass das Eingabegerät langsamer ist und seine Daten daher langsamer produziert, während die CPU schneller arbeiten kann, sodass sie zum nächsten Prozess in der Warteschlange übergeht. Aus diesem Grund wird das Endergebnis oder die Ausgabe zu einem späteren Zeitpunkt und nicht in Echtzeit erstellt.
Unterschied zwischen Spoolen und Puffern
Spooling und Buffering sind die beiden Möglichkeiten, mit denen I/O-Subsysteme die Leistung und Effizienz des Computers verbessern, indem sie einen Speicherplatz im Hauptspeicher oder auf der Festplatte nutzen.

Der grundlegende Unterschied zwischen Spoolen und Puffern besteht darin, dass beim Spoolen die E/A eines Jobs mit der Ausführung eines anderen Jobs überlappt. Im Vergleich dazu überlappt die Pufferung die E/A eines Jobs mit der Ausführung desselben Jobs. Im Folgenden sind einige weitere Unterschiede zwischen Spoolen und Puffern aufgeführt, z. B.:
| Bedingungen | Spulen | Pufferung |
|---|---|---|
| Definition | Beim Spoolen, einem Akronym für Simultaneous Peripheral Operation Online (SPOOL), werden Daten in einen temporären Arbeitsbereich verschoben, damit sie von einem anderen Programm oder einer anderen Ressource abgerufen und verarbeitet werden können. | Beim Puffern werden Daten vorübergehend im Puffer gespeichert. Es hilft dabei, die Geschwindigkeit des Datenstroms zwischen Sender und Empfänger anzupassen. |
| Ressourcenbedarf | Das Spoolen erfordert weniger Ressourcenmanagement, da verschiedene Ressourcen den Prozess für bestimmte Aufgaben verwalten. | Das Puffern erfordert mehr Ressourcenmanagement, da dieselbe Ressource den Prozess desselben geteilten Jobs verwaltet. |
| Interne Umsetzung | Beim Spoolen überlappen sich die Ein- und Ausgabe eines Jobs mit der Berechnung eines anderen Jobs. | Beim Puffern überlappen sich die Eingabe und Ausgabe eines Jobs mit der Berechnung desselben Jobs. |
| Effizient | Spoolen ist effizienter als Puffern. | Pufferung ist weniger effizient als Spoolen. |
| Prozessor | Durch Spoolen können Daten auch an entfernten Standorten verarbeitet werden. Der Spooler muss nur benachrichtigen, wenn ein Prozess am Remote-Standort abgeschlossen wird, um den nächsten Prozess auf das Remote-Gerät zu spoolen. | Die Pufferung unterstützt keine Remote-Verarbeitung. |
| Größe im Speicher | Die Festplatte wird als riesige Spule oder Puffer betrachtet. | Puffer ist ein begrenzter Bereich im Hauptspeicher. |