- Redshift ist ein schneller und leistungsstarker, vollständig verwalteter Data Warehouse-Dienst im Petabyte-Bereich in der Cloud.
- Kunden können Redshift für nur 0,25 US-Dollar pro Stunde ohne Verpflichtungen oder Vorabkosten nutzen und für 1.000 US-Dollar pro Terabyte und Jahr auf ein Petabyte oder mehr skalieren.
OLAP
OLAP ist ein Online-Analyse-Verarbeitungssystem von der verwendet Rotverschiebung .
Beispiel für eine OLAP-Transaktion:
Angenommen, wir möchten den Nettogewinn für EMEA und Pazifik für das Digitalradio-Produkt berechnen. Dies erfordert das Abrufen einer großen Anzahl von Datensätzen. Im Folgenden sind die Unterlagen aufgeführt, die zur Berechnung eines Nettogewinns erforderlich sind:
- Summe der in EMEA verkauften Radios.
- Summe der im Pazifik verkauften Radios.
- Stückkosten für Radio in jeder Region.
- Verkaufspreis für jedes Radio
- Verkaufspreis – Stückkosten
Zum Abrufen der oben angegebenen Datensätze sind komplexe Abfragen erforderlich. Data Warehousing-Datenbanken verwenden sowohl aus Datenbankperspektive als auch auf Infrastrukturebene unterschiedliche Architekturtypen.
Redshift-Konfiguration
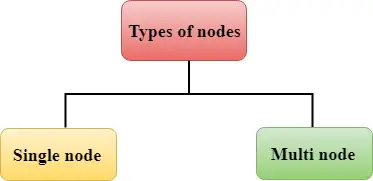
Redshift besteht aus zwei Arten von Knoten:
Einzelner Knoten: Ein einzelner Knoten speichert bis zu 160 GB.
Multi-Knoten: Multi-Node ist ein Knoten, der aus mehr als einem Knoten besteht. Es gibt zwei Arten:
Es verwaltet die Client-Verbindungen und empfängt Anfragen. Ein Führungsknoten empfängt die Abfragen von den Clientanwendungen, analysiert die Abfragen und entwickelt die Ausführungspläne. Es koordiniert die parallele Ausführung dieser Pläne mit dem Rechenknoten, kombiniert die Zwischenergebnisse aller Knoten und gibt dann das Endergebnis an die Clientanwendung zurück.
Ein Rechenknoten führt die Ausführungspläne aus, und dann werden Zwischenergebnisse zur Aggregation an den Führungsknoten gesendet, bevor sie an die Clientanwendung zurückgesendet werden. Es kann bis zu 128 Rechenknoten haben.
Lassen Sie uns das Konzept von Leader-Knoten und Rechenknoten anhand eines Beispiels verstehen.
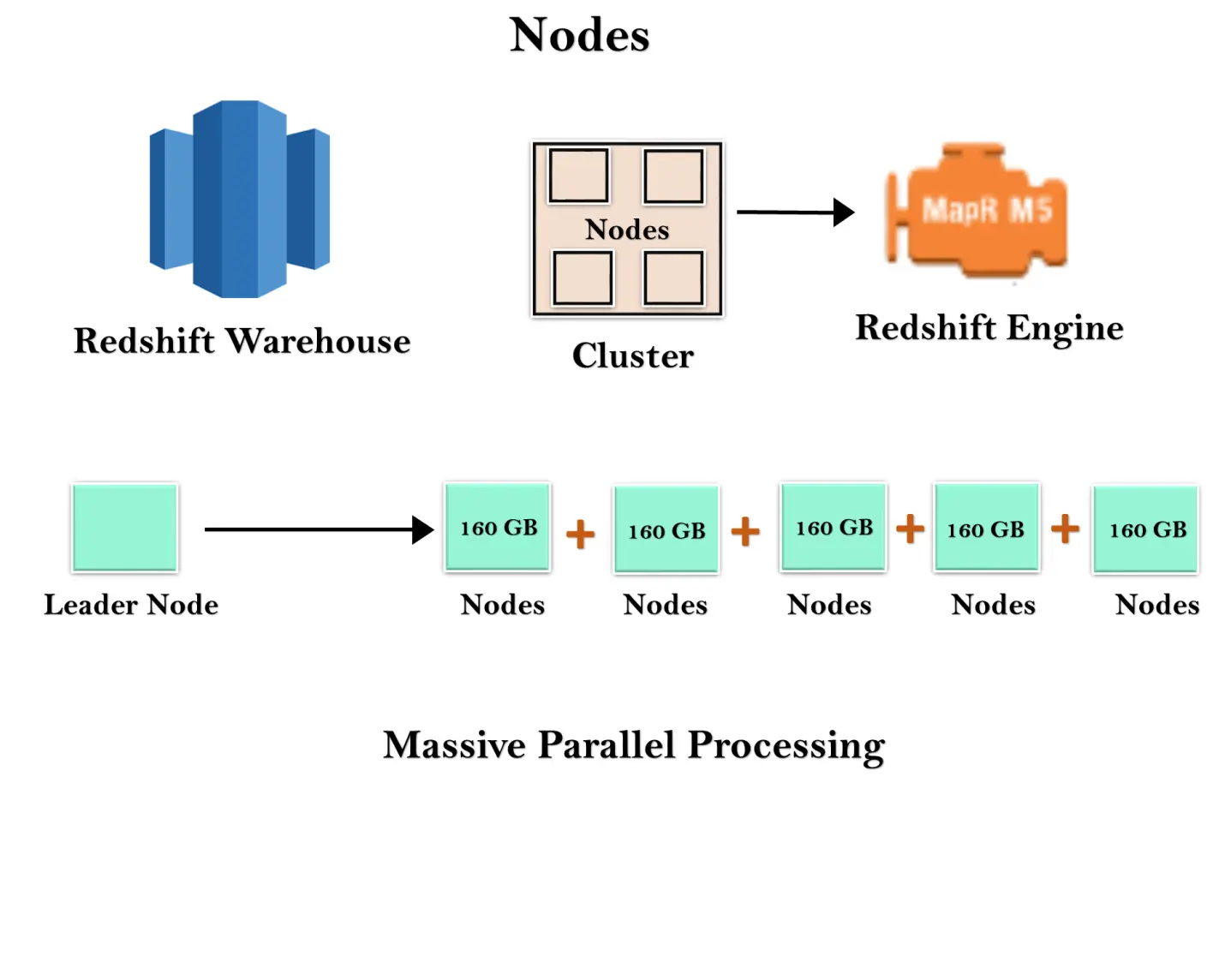
Das Redshift-Warehouse ist eine Sammlung von Rechenressourcen, die als Knoten bezeichnet werden. Diese Knoten sind in einer Gruppe organisiert, die als Cluster bezeichnet wird. Jeder Cluster läuft in einer Redshift Engine, die eine oder mehrere Datenbanken enthält.
Wenn Sie eine Redshift-Instanz starten, beginnt diese mit einem einzelnen Knoten mit einer Größe von 160 GB. Wenn Sie wachsen möchten, können Sie zusätzliche Knoten hinzufügen, um die Vorteile der Parallelverarbeitung zu nutzen. Sie haben einen Führungsknoten, der die mehreren Knoten verwaltet. Der Leader-Knoten verwaltet die Client-Verbindung sowie die Rechenknoten. Es speichert die Daten in Rechenknoten und führt die Abfrage durch.
Warum Redshift zehnmal schneller ist
Redshift ist aus folgenden Gründen zehnmal schneller:
Anstatt Daten als Reihe von Zeilen zu speichern, organisiert Amazon Redshift die Daten nach Spalten. Zeilenbasierte Systeme eignen sich ideal für die Transaktionsverarbeitung, während spaltenbasierte Systeme ideal für Data Warehousing und Analysen sind, bei denen Abfragen häufig Aggregationen umfassen, die über große Datensätze durchgeführt werden. Da nur die an den Abfragen beteiligten Spalten verarbeitet werden und die Spaltendaten nacheinander in einem Speichermedium gespeichert werden, erfordern spaltenbasierte Systeme weniger E/As und verbessern so die Abfrageleistung.
Spaltenbasierte Datenspeicher können viel stärker komprimiert werden als zeilenbasierte Datenspeicher, da ähnliche Daten sequentiell auf der Festplatte gespeichert werden. Amazon Redshift verwendet mehrere Komprimierungstechniken und kann im Vergleich zu herkömmlichen Beziehungsdatenspeichern häufig eine erhebliche Komprimierung erreichen.
Amazon Redshift erfordert keine Indizes oder materialisierten Ansichten und benötigt daher weniger Speicherplatz als herkömmliche relationale Datenbanksysteme. Wenn Sie Daten in eine leere Tabelle laden, prüft Amazon Redshift Ihre Daten automatisch und wählt die am besten geeignete Komprimierungstechnik aus.
Amazon Redshift verteilt die Daten automatisch und lädt die Abfrage auf verschiedene Knoten. Ein Amazon Redshift erleichtert das Hinzufügen neuer Knoten zu Ihrem Data Warehouse und ermöglicht uns eine schnellere Abfrageleistung, wenn Ihr Data Warehouse wächst.
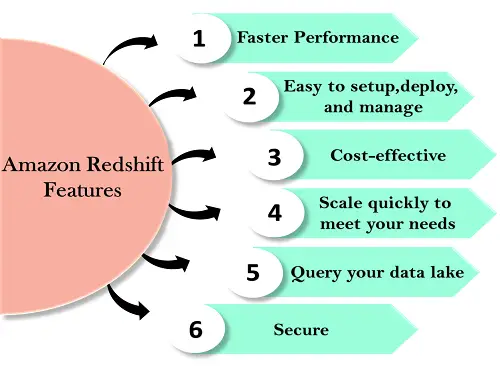
Redshift-Funktionen
Die Funktionen von Redshift sind unten aufgeführt:
Netzwerktopologien
Redshift ist einfach einzurichten und zu bedienen. Sie können ein neues Data Warehouse mit nur wenigen Klicks in der AWS-Konsole bereitstellen und Redshift stellt die Infrastruktur automatisch für Sie bereit. In AWS sind alle Verwaltungsaufgaben wie Backups und Replikation automatisiert. Sie müssen sich auf Ihre Daten konzentrieren und nicht auf die Verwaltung.
Redshift sichert Ihre Daten automatisch auf S3. Sie können die Snapshots auch in S3 in einer anderen Region für eine Notfallwiederherstellung replizieren.
Amazon Redshift ist der kostengünstigste Data Warehouse-Dienst, da Sie nur für das bezahlen müssen, was Sie nutzen.
Die Kosten beginnen bei 0,25 US-Dollar pro Stunde ohne Verpflichtung und ohne Vorabkosten und können auf 250 US-Dollar pro Terabyte und Jahr angehoben werden.
Amazon Redshift ist der einzige Data-Warehouse-Dienst, der On-Demand-Preise ohne Vorabkosten bietet. Darüber hinaus bietet es Preise für reservierte Instanzen, die durch eine Laufzeit von 1 bis 3 Jahren bis zu 75 % sparen.
Sie können einen der beiden Knoten auswählen, um den Redshift zu optimieren.
Ein dichter Rechenknoten kann durch den Einsatz schneller CPUs, einer großen Menge RAM und Solid-State-Festplatten ein leistungsstarkes Data Warehouse erstellen.
Wenn Sie die Kosten senken möchten, können Sie einen dichten Speicherknoten verwenden. Durch die Verwendung einer größeren Festplatte entsteht ein kostengünstiges Data Warehouse.
Amazon Redshift skaliert die Knoten je nach Bedarf automatisch nach oben oder unten. Mit nur wenigen Klicks in der AWS-Konsole oder einem einzigen API-Aufruf können Sie die Anzahl der Knoten in einem Data Warehouse problemlos ändern.
Es handelt sich um eine Funktion von Redshift, mit der Sie Abfragen für Exabytes an Daten in Amazon S3 ausführen können. Amazon S3 ist eine sichere und kostengünstige Datenlösung zum Speichern unbegrenzter Daten in einem offenen Format.
Diese Funktion von Redshift bedeutet, dass mehrere Abfragen auf dieselben Daten in Amazon S3 zugreifen können. Es ermöglicht Ihnen, die Abfragen über mehrere Knoten hinweg auszuführen, unabhängig von der Komplexität einer Abfrage oder der Datenmenge.
Amazon Redshift ist das einzige Data Warehouse, das zur Abfrage des Amazon S3 Data Lake verwendet wird, ohne Daten zu laden. Dies bietet Flexibilität durch die Speicherung häufig aufgerufener Daten in Redshift und unstrukturierter oder selten aufgerufener Daten in Amazon S3.
Mit einigen Parametereinstellungen können Sie Redshift so einstellen, dass es SSL zur Sicherung Ihrer Daten verwendet. Sie können auch die Verschlüsselung aktivieren. Alle auf die Festplatte geschriebenen Daten werden verschlüsselt.
Amazon Redshift bietet spaltenorientierte Datenspeicherung, Komprimierung und parallele Verarbeitung, um die für die Durchführung von Abfragen erforderliche E/A-Menge zu reduzieren. Dies verbessert die Abfrageleistung.