Die folgende Architektur erläutert den Ablauf der Übermittlung einer Abfrage an Hive.
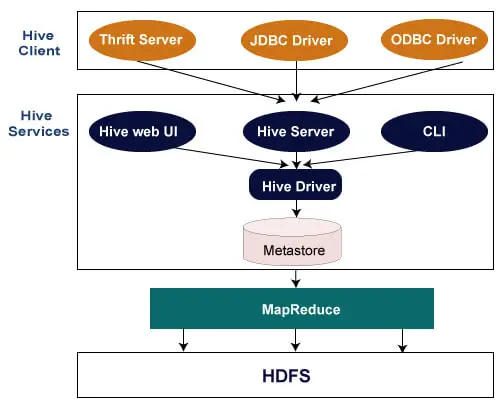
Hive-Client
Hive ermöglicht das Schreiben von Anwendungen in verschiedenen Sprachen, darunter Java, Python und C++. Es unterstützt verschiedene Arten von Clients wie:
- Thrift Server – Hierbei handelt es sich um eine sprachübergreifende Dienstanbieterplattform, die die Anforderungen aller Programmiersprachen bedient, die Thrift unterstützen.
- JDBC-Treiber – Wird zum Herstellen einer Verbindung zwischen Hive- und Java-Anwendungen verwendet. Der JDBC-Treiber ist in der Klasse org.apache.hadoop.hive.jdbc.HiveDriver vorhanden.
- ODBC-Treiber – Ermöglicht Anwendungen, die das ODBC-Protokoll unterstützen, die Verbindung mit Hive.
Hive-Dienste
Im Folgenden sind die von Hive bereitgestellten Dienstleistungen aufgeführt: –
- Hive CLI – Die Hive CLI (Command Line Interface) ist eine Shell, in der wir Hive-Abfragen und -Befehle ausführen können.
- Hive-Web-Benutzeroberfläche – Die Hive-Web-Benutzeroberfläche ist lediglich eine Alternative zur Hive-CLI. Es bietet eine webbasierte GUI zum Ausführen von Hive-Abfragen und -Befehlen.
- Hive MetaStore – Es handelt sich um ein zentrales Repository, das alle Strukturinformationen verschiedener Tabellen und Partitionen im Warehouse speichert. Es umfasst außerdem Metadaten der Spalte und deren Typinformationen, die Serialisierer und Deserialisierer, die zum Lesen und Schreiben von Daten verwendet werden, sowie die entsprechenden HDFS-Dateien, in denen die Daten gespeichert sind.
- Hive Server – Er wird als Apache Thrift Server bezeichnet. Es nimmt die Anfrage verschiedener Clients entgegen und stellt sie Hive Driver zur Verfügung.
- Hive-Treiber – Er empfängt Abfragen von verschiedenen Quellen wie Web-UI, CLI, Thrift und JDBC/ODBC-Treiber. Es übergibt die Abfragen an den Compiler.
- Hive-Compiler – Der Zweck des Compilers besteht darin, die Abfrage zu analysieren und eine semantische Analyse der verschiedenen Abfrageblöcke und Ausdrücke durchzuführen. Es wandelt HiveQL-Anweisungen in MapReduce-Jobs um.
- Hive Execution Engine – Optimizer generiert den logischen Plan in Form von DAG von Map-Reduction-Aufgaben und HDFS-Aufgaben. Am Ende führt die Ausführungs-Engine die eingehenden Aufgaben in der Reihenfolge ihrer Abhängigkeiten aus.