Seit der Erfindung des Computers verwenden Menschen den Begriff „ Daten ', um sich auf Computerinformationen zu beziehen, die entweder übertragen oder gespeichert werden. Es gibt jedoch auch Daten, die in Auftragstypen vorhanden sind. Daten können auf ein Blatt Papier geschriebene Zahlen oder Texte sein, in Form von Bits und Bytes, die im Speicher elektronischer Geräte gespeichert sind, oder Fakten, die im Kopf einer Person gespeichert sind. Als sich die Welt zu modernisieren begann, wurden diese Daten zu einem wichtigen Aspekt des täglichen Lebens eines jeden Menschen, und verschiedene Implementierungen ermöglichten es ihnen, sie unterschiedlich zu speichern.
Daten ist eine Sammlung von Fakten und Zahlen oder eine Menge von Werten oder Werten eines bestimmten Formats, die sich auf eine einzelne Menge von Elementwerten bezieht. Die Datenelemente werden dann in Unterelemente klassifiziert. Dabei handelt es sich um die Gruppe von Elementen, die nicht als einfache Primärform des Elements bekannt sind.
Betrachten wir ein Beispiel, bei dem der Name eines Mitarbeiters in drei Unterelemente unterteilt werden kann: „Vorname“, „Mittelname“ und „Nachname“. Eine einem Mitarbeiter zugewiesene ID wird jedoch im Allgemeinen als ein einzelnes Element betrachtet.
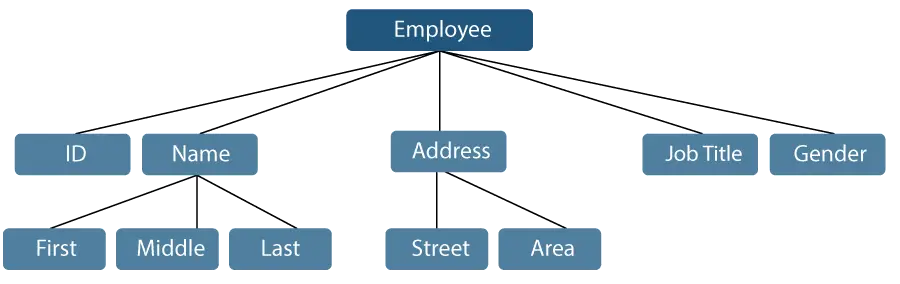
Abbildung 1: Darstellung von Datenelementen
Im oben genannten Beispiel sind die Elemente wie ID, Alter, Geschlecht, Vorname, Mitte, Nachname, Straße, Ort usw. elementare Datenelemente. Im Gegensatz dazu sind der Name und die Adresse Gruppendatenelemente.
Was ist Datenstruktur?
Datenstruktur ist ein Teilgebiet der Informatik. Das Studium der Datenstruktur ermöglicht es uns, die Organisation von Daten und die Verwaltung des Datenflusses zu verstehen, um die Effizienz jedes Prozesses oder Programms zu steigern. Datenstruktur ist eine besondere Methode zum Speichern und Organisieren von Daten im Speicher des Computers, sodass diese Daten bei Bedarf in Zukunft leicht abgerufen und effizient genutzt werden können. Die Daten können auf verschiedene Arten verwaltet werden, so wird das logische oder mathematische Modell für eine bestimmte Datenorganisation als Datenstruktur bezeichnet.
Der Umfang eines bestimmten Datenmodells hängt von zwei Faktoren ab:
- Erstens muss es ausreichend in die Struktur geladen werden, um die eindeutige Korrelation der Daten mit einem realen Objekt widerzuspiegeln.
- Zweitens sollte die Bildung so einfach sein, dass man sie bei Bedarf anpassen kann, um die Daten effizient zu verarbeiten.
Einige Beispiele für Datenstrukturen sind Arrays, verknüpfte Listen, Stapel, Warteschlangen, Bäume usw. Datenstrukturen werden in fast allen Aspekten der Informatik häufig verwendet, d. h. Compiler-Design, Betriebssysteme, Grafik, künstliche Intelligenz und viele mehr.
Datenstrukturen sind der Hauptbestandteil vieler Informatikalgorithmen, da sie es den Programmierern ermöglichen, die Daten effektiv zu verwalten. Es spielt eine entscheidende Rolle bei der Verbesserung der Leistung eines Programms oder einer Software, da das Hauptziel der Software darin besteht, die Daten des Benutzers so schnell wie möglich zu speichern und abzurufen.
Java Long zum Stringen
Grundlegende Terminologien im Zusammenhang mit Datenstrukturen
Datenstrukturen sind die Bausteine jeder Software oder jedes Programms. Die Auswahl der geeigneten Datenstruktur für ein Programm ist für einen Programmierer eine äußerst anspruchsvolle Aufgabe.
Im Folgenden sind einige grundlegende Terminologien aufgeführt, die verwendet werden, wenn es um Datenstrukturen geht:
| Attribute | AUSWEIS | Name | Geschlecht | Berufsbezeichnung |
|---|---|---|---|---|
| Werte | 1234 | Stacey M. Hill | Weiblich | Softwareentwickler |
Entitäten mit ähnlichen Attributen bilden eine Entitätssatz . Jedes Attribut einer Entitätsmenge verfügt über einen Wertebereich, die Menge aller möglichen Werte, die dem spezifischen Attribut zugewiesen werden könnten.
Der Begriff „Informationen“ wird manchmal für Daten mit bestimmten Attributen bedeutungsvoller oder verarbeiteter Daten verwendet.
Den Bedarf an Datenstrukturen verstehen
Da Anwendungen immer komplexer werden und die Datenmenge täglich zunimmt, kann dies zu Problemen bei der Datensuche, der Verarbeitungsgeschwindigkeit, der Bearbeitung mehrerer Anfragen und vielem mehr führen. Datenstrukturen unterstützen verschiedene Methoden zum effizienten Organisieren, Verwalten und Speichern von Daten. Mit Hilfe von Datenstrukturen können wir die Datenelemente einfach durchlaufen. Datenstrukturen bieten Effizienz, Wiederverwendbarkeit und Abstraktion.
Warum sollten wir Datenstrukturen lernen?
- Datenstrukturen und Algorithmen sind zwei der Schlüsselaspekte der Informatik.
- Datenstrukturen ermöglichen es uns, Daten zu organisieren und zu speichern, während Algorithmen es uns ermöglichen, diese Daten sinnvoll zu verarbeiten.
- Das Erlernen von Datenstrukturen und Algorithmen wird uns helfen, bessere Programmierer zu werden.
- Wir werden in der Lage sein, Code zu schreiben, der effektiver und zuverlässiger ist.
- Außerdem können wir Probleme schneller und effizienter lösen.
Die Ziele von Datenstrukturen verstehen
Datenstrukturen erfüllen zwei komplementäre Ziele:
Einige Hauptmerkmale von Datenstrukturen verstehen
Einige der wesentlichen Merkmale von Datenstrukturen sind:
Klassifizierung von Datenstrukturen
Eine Datenstruktur liefert einen strukturierten Satz von Variablen, die auf verschiedene Weise miteinander in Beziehung stehen. Es bildet die Grundlage eines Programmiertools, das die Beziehung zwischen den Datenelementen darstellt und es Programmierern ermöglicht, die Daten effizient zu verarbeiten.
Wir können Datenstrukturen in zwei Kategorien einteilen:
Hrithik Roshan Alter
- Primitive Datenstruktur
- Nicht-primitive Datenstruktur
Die folgende Abbildung zeigt die verschiedenen Klassifizierungen von Datenstrukturen.

Figur 2: Klassifikationen von Datenstrukturen
Primitive Datenstrukturen
- Diese Datenstrukturen können direkt durch Anweisungen auf Maschinenebene manipuliert oder betrieben werden.
- Grundlegende Datentypen wie Ganzzahl, Gleitkomma, Zeichen , Und Boolescher Wert fallen unter die primitiven Datenstrukturen.
- Diese Datentypen werden auch aufgerufen Einfache Datentypen , da sie Zeichen enthalten, die nicht weiter unterteilt werden können
Nicht-primitive Datenstrukturen
- Diese Datenstrukturen können nicht direkt durch Anweisungen auf Maschinenebene manipuliert oder bedient werden.
- Der Schwerpunkt dieser Datenstrukturen liegt auf der Bildung eines Satzes von Datenelementen, die beides sind homogen (gleicher Datentyp) oder heterogen (verschiedene Datentypen).
- Basierend auf der Struktur und Anordnung der Daten können wir diese Datenstrukturen in zwei Unterkategorien einteilen:
- Lineare Datenstrukturen
- Nichtlineare Datenstrukturen
Lineare Datenstrukturen
Eine Datenstruktur, die eine lineare Verbindung zwischen ihren Datenelementen beibehält, wird als lineare Datenstruktur bezeichnet. Die Anordnung der Daten erfolgt linear, wobei jedes Element bis auf das erste und das letzte Datenelement aus den Nachfolgern und Vorgängern besteht. Dies gilt jedoch nicht unbedingt für den Speicher, da die Anordnung möglicherweise nicht sequentiell ist.
Basierend auf der Speicherzuordnung werden die linearen Datenstrukturen weiter in zwei Typen eingeteilt:
Der Array ist das beste Beispiel für die statische Datenstruktur, da sie eine feste Größe haben und ihre Daten später geändert werden können.
Verknüpfte Listen, Stapel , Und Schwänze sind häufige Beispiele für dynamische Datenstrukturen
Arten linearer Datenstrukturen
Das Folgende ist die Liste der linearen Datenstrukturen, die wir im Allgemeinen verwenden:
1. Arrays
Ein Array ist eine Datenstruktur, die zum Sammeln mehrerer Datenelemente desselben Datentyps in einer Variablen verwendet wird. Anstatt mehrere Werte desselben Datentyps in separaten Variablennamen zu speichern, könnten wir sie alle zusammen in einer Variablen speichern. Diese Aussage bedeutet nicht, dass wir alle Werte desselben Datentyps in einem beliebigen Programm in einem Array dieses Datentyps vereinen müssen. Es kommt jedoch häufig vor, dass bestimmte Variablen desselben Datentyps in einer für ein Array geeigneten Weise miteinander in Beziehung stehen.
Ein Array ist eine Liste von Elementen, wobei jedes Element einen eindeutigen Platz in der Liste hat. Die Datenelemente des Arrays haben denselben Variablennamen; jedoch trägt jedes eine andere Indexnummer, die als Index bezeichnet wird. Wir können auf jedes Datenelement aus der Liste mithilfe seiner Position in der Liste zugreifen. Das wichtigste zu verstehende Merkmal der Arrays besteht also darin, dass die Daten an zusammenhängenden Speicherorten gespeichert werden, was es den Benutzern ermöglicht, die Datenelemente des Arrays mithilfe ihrer jeweiligen Indizes zu durchlaufen.

Figur 3. Eine Anordnung
Arrays können in verschiedene Typen eingeteilt werden:
Einige Anwendungen von Array:
- Wir können eine Liste von Datenelementen speichern, die zum gleichen Datentyp gehören.
- Array fungiert als Hilfsspeicher für andere Datenstrukturen.
- Das Array hilft auch beim Speichern von Datenelementen eines Binärbaums mit fester Anzahl.
- Array fungiert auch als Speicher für Matrizen.
2. Verknüpfte Listen
A Verlinkte Liste ist ein weiteres Beispiel für eine lineare Datenstruktur, die zum dynamischen Speichern einer Sammlung von Datenelementen verwendet wird. Datenelemente in dieser Datenstruktur werden durch die Knoten dargestellt, die über Links oder Zeiger verbunden sind. Jeder Knoten enthält zwei Felder, das Informationsfeld besteht aus den tatsächlichen Daten und das Zeigerfeld besteht aus der Adresse der nachfolgenden Knoten in der Liste. Der Zeiger des letzten Knotens der verknüpften Liste besteht aus einem Nullzeiger, da er auf nichts zeigt. Im Gegensatz zu Arrays kann der Benutzer die Größe einer verknüpften Liste dynamisch an die Anforderungen anpassen.
Windows-Befehl arp

Figur 4. Eine verknüpfte Liste
Verknüpfte Listen können in verschiedene Typen eingeteilt werden:
Einige Anwendungen verknüpfter Listen:
- Die verknüpften Listen helfen uns bei der Implementierung von Stapeln, Warteschlangen, Binärbäumen und Diagrammen vordefinierter Größe.
- Wir können auch die Funktion des Betriebssystems für die dynamische Speicherverwaltung implementieren.
- Verknüpfte Listen ermöglichen auch die Polynomimplementierung für mathematische Operationen.
- Wir können Circular Linked List verwenden, um Betriebssysteme oder Anwendungsfunktionen zu implementieren, die die Round-Robin-Ausführung von Aufgaben ermöglichen.
- Eine kreisförmige verknüpfte Liste ist auch in einer Diashow hilfreich, wenn ein Benutzer nach der Präsentation der letzten Folie zur ersten Folie zurückkehren muss.
- Eine doppelt verknüpfte Liste wird verwendet, um Vorwärts- und Rückwärtsschaltflächen in einem Browser zu implementieren, um auf den geöffneten Seiten einer Website vorwärts und rückwärts zu navigieren.
3. Stapel
A Stapel ist eine lineare Datenstruktur, die dem folgt LIFO (Last In, First Out)-Prinzip, das Vorgänge wie das Einfügen und Löschen an einem Ende des Stapels, d. h. oben, ermöglicht. Stapel können mit Hilfe von zusammenhängendem Speicher, einem Array, und nicht zusammenhängendem Speicher, einer verknüpften Liste, implementiert werden. Beispiele für Stacks aus dem wirklichen Leben sind Bücherstapel, ein Kartenspiel, Geldhaufen und vieles mehr.

Abbildung 5. Ein reales Beispiel für Stack
Die obige Abbildung stellt das reale Beispiel eines Stapels dar, bei dem die Vorgänge nur von einem Ende aus ausgeführt werden, z. B. das Einlegen und Entfernen neuer Bücher von der Oberseite des Stapels. Dies impliziert, dass das Einfügen und Löschen in den Stapel nur von der Oberseite des Stapels aus erfolgen kann. Wir können zu jedem Zeitpunkt nur auf die Spitzen des Stapels zugreifen.
Die primären Operationen im Stack sind wie folgt:

Abbildung 6. Ein Stapel
Einige Anwendungen von Stacks:
- Der Stack wird als temporäre Speicherstruktur für rekursive Operationen verwendet.
- Der Stapel wird auch als Hilfsspeicherstruktur für Funktionsaufrufe, verschachtelte Operationen und verzögerte/aufgeschobene Funktionen verwendet.
- Wir können Funktionsaufrufe mithilfe von Stacks verwalten.
- Stapel werden auch verwendet, um arithmetische Ausdrücke in verschiedenen Programmiersprachen auszuwerten.
- Stapel sind auch hilfreich bei der Konvertierung von Infix-Ausdrücken in Postfix-Ausdrücke.
- Mithilfe von Stacks können wir die Syntax des Ausdrucks in der Programmierumgebung überprüfen.
- Mit Stacks können wir Klammern zuordnen.
- Stapel können verwendet werden, um einen String umzukehren.
- Stacks sind hilfreich bei der Lösung von Problemen, die auf Backtracking basieren.
- Wir können Stacks für die Tiefensuche bei der Graph- und Baumdurchquerung verwenden.
- Stapel werden auch in Betriebssystemfunktionen verwendet.
- Stapel werden auch in den UNDO- und REDO-Funktionen einer Bearbeitung verwendet.
4. Schwänze
A Warteschlange ist eine lineare Datenstruktur ähnlich einem Stapel mit einigen Einschränkungen beim Einfügen und Löschen der Elemente. Das Einfügen eines Elements in eine Warteschlange erfolgt an einem Ende und das Entfernen an einem anderen oder gegenüberliegenden Ende. Daraus können wir schließen, dass die Warteschlangendatenstruktur dem FIFO-Prinzip (First In, First Out) folgt, um die Datenelemente zu manipulieren. Die Implementierung von Warteschlangen kann mithilfe von Arrays, verknüpften Listen oder Stapeln erfolgen. Einige Beispiele aus dem wirklichen Leben für Warteschlangen sind eine Schlange am Ticketschalter, eine Rolltreppe, eine Autowaschanlage und vieles mehr.

Abbildung 7. Ein reales Beispiel für eine Warteschlange
Das obige Bild ist eine reale Abbildung eines Kinokartenschalters, die uns helfen kann, die Warteschlange zu verstehen, in der der Kunde, der zuerst kommt, immer zuerst bedient wird. Der zuletzt ankommende Kunde wird zweifellos als Letzter bedient. Beide Enden der Warteschlange sind offen und können verschiedene Operationen ausführen. Ein weiteres Beispiel ist eine Food-Court-Linie, bei der der Kunde am hinteren Ende eingeführt wird, während er am vorderen Ende entfernt wird, nachdem er den gewünschten Service erbracht hat.
Im Folgenden sind die Hauptoperationen der Warteschlange aufgeführt:

Abbildung 8. Warteschlange
Einige Anwendungen von Warteschlangen:
- Warteschlangen werden im Allgemeinen bei der Breitensuchoperation in Diagrammen verwendet.
- Warteschlangen werden auch in Job Scheduler-Vorgängen von Betriebssystemen verwendet, z. B. eine Tastaturpufferwarteschlange zum Speichern der von Benutzern gedrückten Tasten und eine Druckpufferwarteschlange zum Speichern der vom Drucker gedruckten Dokumente.
- Warteschlangen sind für die CPU-Planung, Jobplanung und Festplattenplanung verantwortlich.
- Prioritätswarteschlangen werden beim Herunterladen von Dateien in einem Browser verwendet.
- Warteschlangen werden auch zum Übertragen von Daten zwischen Peripheriegeräten und der CPU verwendet.
- Warteschlangen sind auch für die Verarbeitung von Interrupts verantwortlich, die von den Benutzeranwendungen für die CPU generiert werden.
Nichtlineare Datenstrukturen
Nichtlineare Datenstrukturen sind Datenstrukturen, bei denen die Datenelemente nicht in sequentieller Reihenfolge angeordnet sind. Hier ist das Einfügen und Entfernen von Daten nicht linear möglich. Zwischen den einzelnen Datenelementen besteht eine hierarchische Beziehung.
Arten nichtlinearer Datenstrukturen
Das Folgende ist die Liste der nichtlinearen Datenstrukturen, die wir im Allgemeinen verwenden:
Teilzeichenfolge Java
1. Bäume
Ein Baum ist eine nichtlineare Datenstruktur und eine Hierarchie, die eine Sammlung von Knoten enthält, sodass jeder Knoten des Baums einen Wert und eine Liste von Verweisen auf andere Knoten (die „Kinder“) speichert.
Die Baumdatenstruktur ist eine spezielle Methode zum Ordnen und Sammeln von Daten im Computer, um sie effektiver nutzen zu können. Es enthält einen zentralen Knoten, Strukturknoten und über Kanten verbundene Unterknoten. Wir können auch sagen, dass die Baumdatenstruktur aus verbundenen Wurzeln, Zweigen und Blättern besteht.

Abbildung 9. Ein Baum
Bäume können in verschiedene Arten eingeteilt werden:
Einige Anwendungen von Bäumen:
- Bäume implementieren hierarchische Strukturen in Computersystemen wie Verzeichnissen und Dateisystemen.
- Bäume werden auch verwendet, um die Navigationsstruktur einer Website zu implementieren.
- Mit Trees können wir Code wie Huffmans Code generieren.
- Bäume sind auch bei der Entscheidungsfindung in Gaming-Anwendungen hilfreich.
- Bäume sind für die Implementierung von Prioritätswarteschlangen für prioritätsbasierte Betriebssystemplanungsfunktionen verantwortlich.
- Bäume sind auch für das Parsen von Ausdrücken und Anweisungen in den Compilern verschiedener Programmiersprachen verantwortlich.
- Wir können Bäume verwenden, um Datenschlüssel für die Indizierung für das Datenbankverwaltungssystem (DBMS) zu speichern.
- Spanning Trees ermöglicht es uns, Entscheidungen in Computer- und Kommunikationsnetzwerken weiterzuleiten.
- Bäume werden auch im Pfadfindungsalgorithmus verwendet, der in Anwendungen für künstliche Intelligenz (KI), Robotik und Videospiele implementiert ist.
2. Diagramme
Ein Graph ist ein weiteres Beispiel für eine nichtlineare Datenstruktur, die aus einer endlichen Anzahl von Knoten oder Eckpunkten und den sie verbindenden Kanten besteht. Die Diagramme werden verwendet, um Probleme der realen Welt anzugehen, indem sie den Problembereich als Netzwerk wie soziale Netzwerke, Leitungsnetzwerke und Telefonnetzwerke bezeichnen. Beispielsweise können die Knoten oder Eckpunkte eines Graphen einen einzelnen Benutzer in einem Telefonnetz darstellen, während die Kanten die Verbindung zwischen ihnen per Telefon darstellen.
Die Graph-Datenstruktur G wird als mathematische Struktur betrachtet, die aus einer Reihe von Eckpunkten V und einer Reihe von Kanten E besteht, wie unten gezeigt:
G = (V,E)

Abbildung 10. Ein Graph
Die obige Abbildung stellt einen Graphen mit sieben Eckpunkten A, B, C, D, E, F, G und zehn Kanten [A, B], [A, C], [B, C], [B, D] dar. [B, E], [C, D], [D, E], [D, F], [E, F] und [E, G].
Abhängig von der Position der Eckpunkte und Kanten können die Diagramme in verschiedene Typen eingeteilt werden:
Einige Anwendungen von Diagrammen:
- Mithilfe von Diagrammen können wir Routen und Netzwerke in Transport-, Reise- und Kommunikationsanwendungen darstellen.
- Diagramme dienen zur Darstellung von Routen im GPS.
- Diagramme helfen uns auch dabei, die Zusammenhänge in sozialen Netzwerken und anderen netzwerkbasierten Anwendungen darzustellen.
- Diagramme werden in Kartenanwendungen verwendet.
- Diagramme sind für die Darstellung der Benutzerpräferenzen in E-Commerce-Anwendungen verantwortlich.
- Diagramme werden auch in Versorgungsnetzen verwendet, um die Probleme zu identifizieren, mit denen lokale oder kommunale Unternehmen konfrontiert sind.
- Diagramme helfen auch dabei, die Nutzung und Verfügbarkeit von Ressourcen in einer Organisation zu verwalten.
- Diagramme werden auch verwendet, um Dokument-Link-Maps der Websites zu erstellen, um die Konnektivität zwischen den Seiten über Hyperlinks anzuzeigen.
- Graphen werden auch in Roboterbewegungen und neuronalen Netzen verwendet.
Grundlegende Operationen von Datenstrukturen
Im folgenden Abschnitt besprechen wir die verschiedenen Arten von Operationen, die wir durchführen können, um Daten in jeder Datenstruktur zu manipulieren:
- Kompilierzeit
- Laufzeit
Zum Beispiel die malloc() Die Funktion wird in der C-Sprache zum Erstellen einer Datenstruktur verwendet.
Den abstrakten Datentyp verstehen
Gemäß der Nationales Institut für Standards und Technologie (NIST) Eine Datenstruktur ist eine Anordnung von Informationen, im Allgemeinen im Speicher, zur Verbesserung der Algorithmuseffizienz. Zu den Datenstrukturen gehören verknüpfte Listen, Stapel, Warteschlangen, Bäume und Wörterbücher. Sie könnten auch eine theoretische Einheit sein, etwa der Name und die Adresse einer Person.
Aus der oben genannten Definition können wir schließen, dass die Operationen in der Datenstruktur Folgendes umfassen:
- Ein hohes Abstraktionsniveau wie das Hinzufügen oder Löschen eines Elements aus einer Liste.
- Suchen und Sortieren eines Elements in einer Liste.
- Zugriff auf das Element mit der höchsten Priorität in einer Liste.
Immer wenn die Datenstruktur solche Operationen ausführt, wird sie als bezeichnet Abstrakter Datentyp (ADT) .
Wir können es als eine Reihe von Datenelementen zusammen mit den Operationen an den Daten definieren. Der Begriff „abstrakt“ bezieht sich auf die Tatsache, dass die Daten und die darauf definierten grundlegenden Operationen unabhängig von ihrer Implementierung untersucht werden. Es geht darum, was wir mit den Daten machen können, nicht wie wir es machen können.
Pfad in Java festgelegt
Eine ADI-Implementierung enthält eine Speicherstruktur, um die Datenelemente und Algorithmen für den grundlegenden Betrieb zu speichern. Alle Datenstrukturen, wie ein Array, eine verknüpfte Liste, eine Warteschlange, ein Stapel usw., sind Beispiele für ADT.
Die Vorteile der Verwendung von ADTs verstehen
In der realen Welt entwickeln sich Programme aufgrund neuer Einschränkungen oder Anforderungen weiter. Daher erfordert die Änderung eines Programms im Allgemeinen eine Änderung einer oder mehrerer Datenstrukturen. Angenommen, wir möchten ein neues Feld in den Datensatz eines Mitarbeiters einfügen, um weitere Details zu jedem Mitarbeiter zu verfolgen. In diesem Fall können wir die Effizienz des Programms verbessern, indem wir ein Array durch eine Linked-Struktur ersetzen. In einer solchen Situation ist es ungeeignet, jede Prozedur neu zu schreiben, die die geänderte Struktur verwendet. Daher besteht eine bessere Alternative darin, eine Datenstruktur von ihren Implementierungsinformationen zu trennen. Dies ist das Prinzip hinter der Verwendung von Abstract Data Types (ADT).
Einige Anwendungen von Datenstrukturen
Im Folgenden sind einige Anwendungen von Datenstrukturen aufgeführt:
- Datenstrukturen helfen bei der Organisation von Daten im Speicher eines Computers.
- Datenstrukturen helfen auch bei der Darstellung der Informationen in Datenbanken.
- Datenstrukturen ermöglichen die Implementierung von Algorithmen zum Durchsuchen von Daten (z. B. einer Suchmaschine).
- Wir können die Datenstrukturen verwenden, um die Algorithmen zur Datenbearbeitung zu implementieren (z. B. Textverarbeitungsprogramme).
- Wir können die Algorithmen auch implementieren, um Daten mithilfe von Datenstrukturen zu analysieren (z. B. Data Miner).
- Datenstrukturen unterstützen Algorithmen zum Generieren der Daten (z. B. einen Zufallszahlengenerator).
- Datenstrukturen unterstützen auch Algorithmen zum Komprimieren und Dekomprimieren der Daten (z. B. ein Zip-Dienstprogramm).
- Wir können Datenstrukturen auch verwenden, um Algorithmen zum Ver- und Entschlüsseln der Daten zu implementieren (z. B. ein Sicherheitssystem).
- Mithilfe von Datenstrukturen können wir Software erstellen, die Dateien und Verzeichnisse verwalten kann (z. B. einen Dateimanager).
- Wir können auch Software entwickeln, die Grafiken mithilfe von Datenstrukturen rendern kann. (Zum Beispiel ein Webbrowser oder eine 3D-Rendering-Software).
Abgesehen davon gibt es, wie bereits erwähnt, viele andere Anwendungen von Datenstrukturen, die uns bei der Erstellung jeder gewünschten Software helfen können.