Bevor wir uns die Unterschiede zwischen BFS und DFS ansehen, sollten wir zunächst BFS und DFS getrennt kennen.
Was ist BFS?
BFS steht für Breitensuche . Es ist auch bekannt als Level-Reihenfolge-Durchquerung . Die Warteschlangendatenstruktur wird für die Breitensuche-Durchquerung verwendet. Wenn wir den BFS-Algorithmus für die Durchquerung eines Diagramms verwenden, können wir jeden Knoten als Wurzelknoten betrachten.
Betrachten wir das folgende Diagramm für den Breitensuchdurchlauf.
Programmierung in C-Arrays
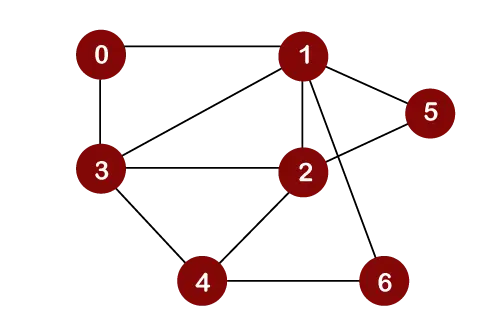
Angenommen, wir betrachten Knoten 0 als Wurzelknoten. Daher würde die Traversierung vom Knoten 0 aus gestartet werden.

Sobald Knoten 0 aus der Warteschlange entfernt wird, wird er gedruckt und als markiert besuchter Knoten.
Sobald Knoten 0 aus der Warteschlange entfernt wird, werden die benachbarten Knoten von Knoten 0 wie unten gezeigt in eine Warteschlange eingefügt:

Jetzt wird der Knoten 1 aus der Warteschlange entfernt; Es wird gedruckt und als besuchter Knoten markiert
Sobald Knoten 1 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 1 zu einer Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 1 sind 0, 3, 2, 6 und 5. Wir müssen jedoch nur nicht besuchte Knoten in eine Warteschlange einfügen. Da die Knoten 3, 2, 6 und 5 nicht besucht werden; Daher werden diese Knoten wie unten gezeigt in eine Warteschlange eingefügt:

Der nächste Knoten ist 3 in einer Warteschlange. Daher wird Knoten 3 aus der Warteschlange entfernt, gedruckt und wie unten gezeigt als besucht markiert:

Sobald Knoten 3 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 3 mit Ausnahme der besuchten Knoten zu einer Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 3 sind 0, 1, 2 und 4. Da die Knoten 0, 1 bereits besucht sind und Knoten 2 in einer Warteschlange vorhanden ist; Daher müssen wir nur Knoten 4 in eine Warteschlange einfügen.
Datei in Java öffnen

Der nächste Knoten in der Warteschlange ist nun 2. Daher würde 2 aus der Warteschlange gelöscht. Es wird gedruckt und wie unten gezeigt als besucht markiert:

Sobald Knoten 2 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 2 mit Ausnahme der besuchten Knoten zu einer Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 2 sind 1, 3, 5, 6 und 4. Da die Knoten 1 und 3 bereits besucht wurden und 4, 5, 6 bereits zur Warteschlange hinzugefügt wurden; Daher müssen wir keinen Knoten in die Warteschlange einfügen.
Das nächste Element ist 5. Somit würde 5 aus der Warteschlange gelöscht. Es wird gedruckt und wie unten gezeigt als besucht markiert:

Sobald Knoten 5 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 5 mit Ausnahme der besuchten Knoten zur Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 5 sind 1 und 2. Da beide Knoten bereits besucht wurden; Daher gibt es keinen Scheitelpunkt, der in eine Warteschlange eingefügt werden kann.
Der nächste Knoten ist 6. Somit würde 6 aus der Warteschlange gelöscht. Es wird gedruckt und wie unten gezeigt als besucht markiert:

Sobald der Knoten 6 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 6 mit Ausnahme der besuchten Knoten zur Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 6 sind 1 und 4. Da Knoten 1 bereits besucht wurde und Knoten 4 bereits zur Warteschlange hinzugefügt wurde; Daher gibt es keinen Scheitelpunkt, der in die Warteschlange eingefügt werden kann.
sonniges Deol-Zeitalter
Das nächste Element in der Warteschlange ist 4. Daher würde 4 aus der Warteschlange gelöscht. Es wird ausgedruckt und als besucht markiert.
Sobald der Knoten 4 aus der Warteschlange entfernt wird, werden alle benachbarten Knoten von Knoten 4 mit Ausnahme der besuchten Knoten zur Warteschlange hinzugefügt. Die benachbarten Knoten von Knoten 4 sind 3, 2 und 6. Da alle benachbarten Knoten bereits besucht wurden; Es gibt also keinen Scheitelpunkt, der in die Warteschlange eingefügt werden kann.
Was ist DFS?
DFS steht für Depth First Search. Beim DFS-Traversal wird die Stack-Datenstruktur verwendet, die nach dem LIFO-Prinzip (Last In First Out) funktioniert. In DFS kann die Traversierung von jedem Knoten aus gestartet werden, oder wir können sagen, dass jeder Knoten als Wurzelknoten betrachtet werden kann, bis der Wurzelknoten im Problem nicht erwähnt wird.
Im Fall von BFS wird das Element, das aus der Warteschlange gelöscht wird, die benachbarten Knoten des gelöschten Knotens zur Warteschlange hinzugefügt. Im Gegensatz dazu wird in DFS das Element, das aus dem Stapel entfernt wird, nur ein benachbarter Knoten eines gelöschten Knotens zum Stapel hinzugefügt.
Betrachten wir das folgende Diagramm für die Durchquerung der Tiefensuche.

Betrachten Sie Knoten 0 als Wurzelknoten.
Zuerst fügen wir das Element 0 wie unten gezeigt in den Stapel ein:

Der Knoten 0 hat zwei benachbarte Knoten, nämlich 1 und 3. Jetzt können wir nur einen benachbarten Knoten, entweder 1 oder 3, zum Durchlaufen nehmen. Angenommen, wir betrachten Knoten 1; Daher wird 1 in einen Stapel eingefügt und wie unten gezeigt gedruckt:

Jetzt schauen wir uns die benachbarten Eckpunkte von Knoten 1 an. Die nicht besuchten benachbarten Eckpunkte von Knoten 1 sind 3, 2, 5 und 6. Wir können jeden dieser vier Eckpunkte betrachten. Angenommen, wir nehmen Knoten 3 und fügen ihn wie unten gezeigt in den Stapel ein:

Betrachten Sie die nicht besuchten benachbarten Scheitelpunkte von Knoten 3. Die nicht besuchten benachbarten Scheitelpunkte von Knoten 3 sind 2 und 4. Wir können einen der Scheitelpunkte nehmen, d. h. 2 oder 4. Angenommen, wir nehmen Scheitelpunkt 2 und fügen ihn wie unten gezeigt in den Stapel ein:
inurl:.git/head

Die nicht besuchten benachbarten Scheitelpunkte von Knoten 2 sind 5 und 4. Wir können einen der Scheitelpunkte wählen, also 5 oder 4. Angenommen, wir nehmen Scheitelpunkt 4 und fügen ihn wie unten gezeigt in den Stapel ein:

Nun betrachten wir die nicht besuchten benachbarten Scheitelpunkte von Knoten 4. Der nicht besuchte benachbarte Scheitelpunkt von Knoten 4 ist Knoten 6. Daher wird Element 6 wie unten gezeigt in den Stapel eingefügt:

Nachdem wir Element 6 in den Stapel eingefügt haben, werden wir uns die nicht besuchten benachbarten Scheitelpunkte von Knoten 6 ansehen. Da es keine nicht besuchten benachbarten Scheitelpunkte von Knoten 6 gibt, können wir nicht über Knoten 6 hinausgehen. In diesem Fall führen wir aus Zurückverfolgen . Das oberste Element, d. h. 6, würde wie unten gezeigt aus dem Stapel herausspringen:


Das oberste Element im Stapel ist 4. Da es keine unbesuchten benachbarten Scheitelpunkte mehr von Knoten 4 gibt; Daher wird Knoten 4 wie unten gezeigt aus dem Stapel entfernt:


Das nächstoberste Element im Stapel ist 2. Nun schauen wir uns die nicht besuchten benachbarten Scheitelpunkte von Knoten 2 an. Da nur noch ein nicht besuchter Knoten, d. h. 5, übrig ist, würde Knoten 5 in den Stapel über 2 verschoben und gedruckt Wie nachfolgend dargestellt:

Jetzt überprüfen wir die benachbarten Eckpunkte von Knoten 5, die noch nicht besucht sind. Da es keinen zu besuchenden Scheitelpunkt mehr gibt, entfernen wir das Element 5 wie unten gezeigt vom Stapel:

Wir können uns nicht weiter um 5 bewegen, also müssen wir eine Rückverfolgung durchführen. Beim Backtracking würde das oberste Element aus dem Stapel herausspringen. Das oberste Element ist 5, das aus dem Stapel herausspringen würde, und wir gehen zurück zu Knoten 2, wie unten gezeigt:

Jetzt überprüfen wir die nicht besuchten benachbarten Scheitelpunkte von Knoten 2. Da es keinen benachbarten Scheitelpunkt mehr gibt, der besucht werden könnte, führen wir ein Backtracking durch. Beim Backtracking würde das oberste Element, d. h. 2, aus dem Stapel herausspringen, und wir gehen zurück zum Knoten 3, wie unten gezeigt:


Jetzt überprüfen wir die nicht besuchten benachbarten Scheitelpunkte von Knoten 3. Da es keinen benachbarten Scheitelpunkt mehr gibt, der besucht werden könnte, führen wir ein Backtracking durch. Beim Backtracking würde das oberste Element, d. h. 3, aus dem Stapel herausspringen und wir kehren zu Knoten 1 zurück, wie unten gezeigt:
Was ist Ymail?


Nach dem Herausspringen von Element 3 überprüfen wir die nicht besuchten benachbarten Scheitelpunkte von Knoten 1. Da es keinen zu besuchenden Scheitelpunkt mehr gibt; Daher wird das Backtracking durchgeführt. Beim Backtracking würde das oberste Element, d. h. 1, aus dem Stapel herausspringen und wir kehren zu Knoten 0 zurück, wie unten gezeigt:


Wir werden die benachbarten Eckpunkte von Knoten 0 überprüfen, die noch nicht besucht sind. Da es keinen benachbarten Scheitelpunkt mehr gibt, der besucht werden könnte, führen wir ein Backtracking durch. In diesem Fall würde nur ein Element, d. h. 0 im Stapel, wie unten gezeigt aus dem Stapel herausgenommen:

Wie wir in der obigen Abbildung sehen können, ist der Stapel leer. Daher müssen wir den DFS-Durchlauf hier stoppen, und die gedruckten Elemente sind das Ergebnis des DFS-Durchlaufs.
Unterschiede zwischen BFS und DFS
Im Folgenden sind die Unterschiede zwischen BFS und DFS aufgeführt:
| BFS | DFS | |
|---|---|---|
| Vollständige Form | BFS steht für „Breadth First Search“. | DFS steht für Depth First Search. |
| Technik | Es handelt sich um eine scheitelpunktbasierte Technik, um den kürzesten Pfad in einem Diagramm zu finden. | Es handelt sich um eine kantenbasierte Technik, da zunächst die Scheitelpunkte entlang der Kante vom Start- bis zum Endknoten untersucht werden. |
| Definition | BFS ist eine Traversierungstechnik, bei der zuerst alle Knoten derselben Ebene untersucht werden und dann zur nächsten Ebene übergegangen wird. | DFS ist auch eine Traversierungstechnik, bei der die Traversierung vom Wurzelknoten aus gestartet wird und die Knoten so weit wie möglich erkundet werden, bis wir den Knoten erreichen, der keine unbesuchten Nachbarknoten mehr hat. |
| Datenstruktur | Für den BFS-Durchlauf wird die Warteschlangendatenstruktur verwendet. | Für die BFS-Durchquerung wird die Stapeldatenstruktur verwendet. |
| Zurückverfolgen | BFS verwendet nicht das Backtracking-Konzept. | DFS verwendet Backtracking, um alle nicht besuchten Knoten zu durchlaufen. |
| Anzahl der Kanten | BFS findet den kürzesten Pfad mit einer Mindestanzahl an Kanten, die vom Quell- zum Zielscheitelpunkt überquert werden müssen. | In DFS ist eine größere Anzahl von Kanten erforderlich, um vom Quellscheitelpunkt zum Zielscheitelpunkt zu gelangen. |
| Optimalität | Die BFS-Durchquerung ist optimal für die Scheitelpunkte, die näher am Quellscheitelpunkt gesucht werden sollen. | Die DFS-Durchquerung ist optimal für Diagramme, in denen Lösungen vom Quellscheitelpunkt entfernt sind. |
| Geschwindigkeit | BFS ist langsamer als DFS. | DFS ist schneller als BFS. |
| Eignung für Entscheidungsbaum | Es ist nicht für den Entscheidungsbaum geeignet, da zunächst alle benachbarten Knoten untersucht werden müssen. | Es ist für den Entscheidungsbaum geeignet. Basierend auf der Entscheidung werden alle Wege erkundet. Wenn das Ziel gefunden ist, stoppt es seine Durchquerung. |
| Speichereffizient | Es ist nicht speichereffizient, da es mehr Speicher benötigt als DFS. | Es ist speichereffizient, da es weniger Speicher benötigt als BFS. |