Wie wir wissen, kann der Algorithmus des überwachten maschinellen Lernens grob in Regressions- und Klassifizierungsalgorithmen eingeteilt werden. In Regressionsalgorithmen haben wir die Ausgabe für kontinuierliche Werte vorhergesagt, aber um die kategorialen Werte vorherzusagen, benötigen wir Klassifizierungsalgorithmen.
Was ist der Klassifizierungsalgorithmus?
Der Klassifizierungsalgorithmus ist eine Technik des überwachten Lernens, mit der die Kategorie neuer Beobachtungen auf der Grundlage von Trainingsdaten identifiziert wird. Bei der Klassifizierung lernt ein Programm aus dem gegebenen Datensatz oder den Beobachtungen und klassifiziert dann neue Beobachtungen in eine Reihe von Klassen oder Gruppen. Wie zum Beispiel, Ja oder Nein, 0 oder 1, Spam oder Nicht Spam, Katze oder Hund, usw. Klassen können als Ziele/Labels oder Kategorien bezeichnet werden.
Neena Gupta
Im Gegensatz zur Regression ist die Ausgabevariable der Klassifizierung eine Kategorie und kein Wert wie „Grün oder Blau“, „Obst oder Tier“ usw. Da es sich beim Klassifizierungsalgorithmus um eine Technik des überwachten Lernens handelt, werden beschriftete Eingabedaten verwendet bedeutet, dass es eine Eingabe mit der entsprechenden Ausgabe enthält.
Im Klassifizierungsalgorithmus wird eine diskrete Ausgabefunktion (y) auf die Eingabevariable (x) abgebildet.
y=f(x), where y = categorical output
Das beste Beispiel für einen ML-Klassifizierungsalgorithmus ist E-Mail-Spam-Detektor .
Das Hauptziel des Klassifizierungsalgorithmus besteht darin, die Kategorie eines bestimmten Datensatzes zu identifizieren. Diese Algorithmen werden hauptsächlich zur Vorhersage der Ausgabe der kategorialen Daten verwendet.
Klassifizierungsalgorithmen können anhand des folgenden Diagramms besser verstanden werden. Im folgenden Diagramm gibt es zwei Klassen, Klasse A und Klasse B. Diese Klassen weisen Merkmale auf, die einander ähnlich und von anderen Klassen unterschiedlich sind.
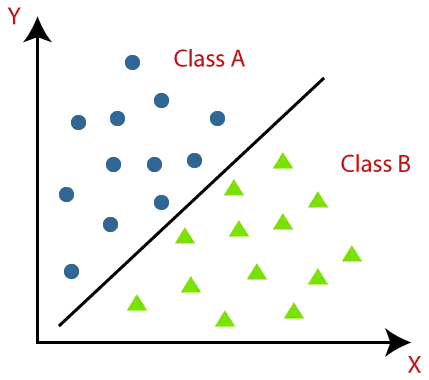
Der Algorithmus, der die Klassifizierung eines Datensatzes implementiert, wird als Klassifikator bezeichnet. Es gibt zwei Arten von Klassifizierungen:
Beispiele: JA oder NEIN, MÄNNLICH oder WEIBLICH, SPAM oder NICHT SPAM, KATZE oder HUND usw.
Beispiel: Klassifikationen von Kulturpflanzenarten, Klassifikation von Musikarten.
Lernende bei Klassifikationsproblemen:
Bei den Klassifikationsproblemen gibt es zwei Arten von Lernenden:
Beispiel: K-NN-Algorithmus, fallbasiertes Denken
Arten von ML-Klassifizierungsalgorithmen:
Klassifizierungsalgorithmen können weiter in die hauptsächlich zwei Kategorien unterteilt werden:
- Logistische Regression
- Support-Vektor-Maschinen
- K-Nächste Nachbarn
- Kernel-SVM
- Naive Bayes
- Entscheidungsbaumklassifizierung
- Zufällige Waldklassifizierung
Hinweis: Wir werden die oben genannten Algorithmen in späteren Kapiteln lernen.
Bewertung eines Klassifizierungsmodells:
Sobald unser Modell fertiggestellt ist, ist es notwendig, seine Leistung zu bewerten; Entweder handelt es sich um ein Klassifizierungs- oder ein Regressionsmodell. Für die Bewertung eines Klassifizierungsmodells haben wir also die folgenden Möglichkeiten:
1. Protokollverlust oder Kreuzentropieverlust:
- Es wird zur Bewertung der Leistung eines Klassifikators verwendet, dessen Ausgabe ein Wahrscheinlichkeitswert zwischen 0 und 1 ist.
- Für ein gutes binäres Klassifizierungsmodell sollte der Wert des Protokollverlusts nahe bei 0 liegen.
- Der Wert des Protokollverlusts erhöht sich, wenn der vorhergesagte Wert vom tatsächlichen Wert abweicht.
- Der geringere Protokollverlust stellt die höhere Genauigkeit des Modells dar.
- Für die binäre Klassifizierung kann die Kreuzentropie wie folgt berechnet werden:
?(ylog(p)+(1?y)log(1?p))
Wobei y = tatsächliche Ausgabe, p = vorhergesagte Ausgabe.
Java-Auswahlsortierung
2. Verwirrungsmatrix:
- Die Verwirrungsmatrix liefert uns eine Matrix/Tabelle als Ausgabe und beschreibt die Leistung des Modells.
- Sie wird auch als Fehlermatrix bezeichnet.
- Die Matrix besteht aus Vorhersageergebnissen in zusammengefasster Form, die eine Gesamtzahl richtiger und falscher Vorhersagen enthält. Die Matrix sieht wie folgt aus:
| Tatsächlich positiv | Tatsächlich negativ | |
|---|---|---|
| Positiv vorhergesagt | Wirklich positiv | Falsch positiv |
| Negativ vorhergesagt | Falsch negativ | Echt negativ |

3. AUC-ROC-Kurve:
- ROC-Kurve steht für Betriebskennlinie des Empfängers und AUC steht für Fläche unter der Kurve .
- Es handelt sich um ein Diagramm, das die Leistung des Klassifizierungsmodells bei verschiedenen Schwellenwerten zeigt.
- Um die Leistung des Mehrklassen-Klassifizierungsmodells zu visualisieren, verwenden wir die AUC-ROC-Kurve.
- Die ROC-Kurve wird mit TPR und FPR dargestellt, wobei TPR (True Positive Rate) auf der Y-Achse und FPR (False Positive Rate) auf der X-Achse aufgetragen ist.
Anwendungsfälle von Klassifizierungsalgorithmen
Klassifizierungsalgorithmen können an verschiedenen Stellen eingesetzt werden. Nachfolgend sind einige beliebte Anwendungsfälle von Klassifizierungsalgorithmen aufgeführt:
- E-Mail-Spam-Erkennung
- Spracherkennung
- Identifizierung von Krebstumorzellen.
- Drogenklassifizierung
- Biometrische Identifizierung usw.