A Faltungs-Neuronales Netzwerk (CNN) ist eine Art Deep-Learning-Architektur für neuronale Netzwerke, die häufig in der Computer Vision verwendet wird. Computer Vision ist ein Bereich der künstlichen Intelligenz, der es einem Computer ermöglicht, Bilder oder visuelle Daten zu verstehen und zu interpretieren.
Wenn es um maschinelles Lernen geht, Künstliche neurale Netzwerke wirklich gut abschneiden. Neuronale Netze werden in verschiedenen Datensätzen wie Bildern, Audio und Text verwendet. Verschiedene Arten neuronaler Netze werden für unterschiedliche Zwecke verwendet, beispielsweise zur Vorhersage der Reihenfolge der von uns verwendeten Wörter Wiederkehrende neuronale Netze genauer gesagt ein LSTM Ebenso verwenden wir für die Bildklassifizierung Convolution Neural Networks. In diesem Blog werden wir einen Grundbaustein für CNN erstellen.
In einem regulären neuronalen Netzwerk gibt es drei Arten von Schichten:
Java-Programm
- Eingabeebenen: Es ist die Ebene, auf der wir unserem Modell Input geben. Die Anzahl der Neuronen in dieser Schicht entspricht der Gesamtzahl der Merkmale in unseren Daten (Anzahl der Pixel im Fall eines Bildes).
- Versteckte Ebene: Die Eingaben aus der Eingabeebene werden dann in die verborgene Ebene eingespeist. Abhängig von unserem Modell und der Datengröße können viele verborgene Ebenen vorhanden sein. Jede verborgene Schicht kann eine unterschiedliche Anzahl von Neuronen haben, die im Allgemeinen größer ist als die Anzahl der Merkmale. Die Ausgabe jeder Schicht wird durch Matrixmultiplikation der Ausgabe der vorherigen Schicht mit lernbaren Gewichtungen dieser Schicht und dann durch Addition lernbarer Vorspannungen und anschließender Aktivierungsfunktion berechnet, die das Netzwerk nichtlinear macht.
- Ausgabeschicht: Die Ausgabe der verborgenen Schicht wird dann in eine Logistikfunktion wie Sigmoid oder Softmax eingespeist, die die Ausgabe jeder Klasse in den Wahrscheinlichkeitswert jeder Klasse umwandelt.
Die Daten werden in das Modell eingespeist und die Ausgabe jeder Schicht wird aus dem oben genannten Schritt aufgerufen Feedforward Anschließend berechnen wir den Fehler mithilfe einer Fehlerfunktion. Einige häufige Fehlerfunktionen sind Kreuzentropie, quadratischer Verlustfehler usw. Die Fehlerfunktion misst, wie gut das Netzwerk funktioniert. Danach führen wir eine Rückübertragung in das Modell durch, indem wir die Ableitungen berechnen. Dieser Schritt wird aufgerufen Convolutional Neural Network (CNN) ist die erweiterte Version von Künstliche neuronale Netze (ANN) Dies wird hauptsächlich zum Extrahieren des Features aus dem gitterartigen Matrixdatensatz verwendet. Zum Beispiel visuelle Datensätze wie Bilder oder Videos, bei denen Datenmuster eine große Rolle spielen.
CNN-Architektur
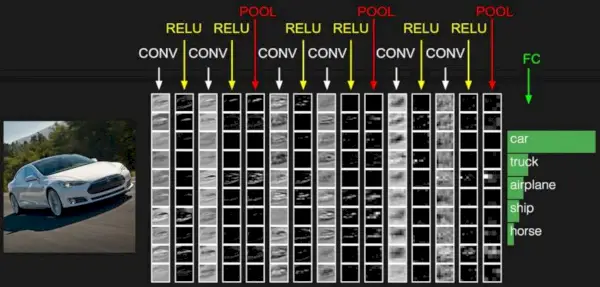
Das Faltungs-Neuronale Netzwerk besteht aus mehreren Schichten wie der Eingabeschicht, der Faltungsschicht, der Pooling-Schicht und vollständig verbundenen Schichten.

Einfache CNN-Architektur
Die Faltungsschicht wendet Filter auf das Eingabebild an, um Merkmale zu extrahieren, die Pooling-Schicht führt ein Downsampling des Bildes durch, um den Rechenaufwand zu reduzieren, und die vollständig verbundene Schicht trifft die endgültige Vorhersage. Das Netzwerk lernt die optimalen Filter durch Backpropagation und Gradientenabstieg.
So funktionieren Faltungsschichten
Faltungs-Neuronale Netzwerke oder Covnets sind neuronale Netzwerke, die ihre Parameter teilen. Stellen Sie sich vor, Sie haben ein Bild. Es kann als Quader mit seiner Länge, Breite (Abmessung des Bildes) und Höhe dargestellt werden (d. h. der Kanal, da Bilder im Allgemeinen rote, grüne und blaue Kanäle haben).
Stellen Sie sich nun vor, Sie nehmen einen kleinen Ausschnitt dieses Bildes und lassen darauf ein kleines neuronales Netzwerk, einen sogenannten Filter oder Kernel, mit beispielsweise K Ausgängen laufen und stellen diese vertikal dar. Schieben Sie nun dieses neuronale Netzwerk über das gesamte Bild. Als Ergebnis erhalten wir ein weiteres Bild mit unterschiedlichen Breiten, Höhen und Tiefen. Statt nur R-, G- und B-Kanälen haben wir jetzt mehr Kanäle, aber weniger Breite und Höhe. Diese Operation wird aufgerufen Faltung . Wenn die Patchgröße mit der des Bildes übereinstimmt, handelt es sich um ein reguläres neuronales Netzwerk. Aufgrund dieses kleinen Patches haben wir weniger Gewichte.
Bildquelle: Deep Learning Udacity
Lassen Sie uns nun über ein wenig Mathematik sprechen, die am gesamten Faltungsprozess beteiligt ist.
- Faltungsschichten bestehen aus einer Reihe lernbarer Filter (oder Kernel) mit geringer Breite und Höhe und derselben Tiefe wie das Eingabevolumen (3, wenn es sich bei der Eingabeschicht um eine Bildeingabe handelt).
- Wenn wir zum Beispiel eine Faltung für ein Bild mit den Abmessungen 34x34x3 durchführen müssen. Die mögliche Größe von Filtern kann axax3 sein, wobei „a“ etwa 3, 5 oder 7 sein kann, aber im Vergleich zur Bildgröße kleiner ist.
- Während des Vorwärtsdurchlaufs schieben wir jeden Filter Schritt für Schritt über das gesamte Eingangsvolumen, wo jeder Schritt aufgerufen wird schreiten (der für hochdimensionale Bilder einen Wert von 2, 3 oder sogar 4 haben kann) und berechnen Sie das Skalarprodukt zwischen den Kerngewichten und dem Patch aus dem Eingabevolumen.
- Wenn wir unsere Filter verschieben, erhalten wir für jeden Filter eine 2D-Ausgabe und stapeln sie. Als Ergebnis erhalten wir ein Ausgabevolumen mit einer Tiefe, die der Anzahl der Filter entspricht. Das Netzwerk lernt alle Filter.
Schichten, die zum Aufbau von ConvNets verwendet werden
Eine vollständige Convolution Neural Networks-Architektur wird auch als Covenets bezeichnet. Ein Covenet ist eine Folge von Schichten, und jede Schicht wandelt ein Volumen durch eine differenzierbare Funktion in ein anderes um.
Arten von Schichten: Datensätze
Nehmen wir ein Beispiel, indem wir ein Covenets-on-Bild mit der Abmessung 32 x 32 x 3 ausführen.
- Eingabeebenen: Es ist die Ebene, auf der wir unserem Modell Input geben. Bei CNN handelt es sich bei der Eingabe im Allgemeinen um ein Bild oder eine Bildfolge. Diese Ebene enthält die Roheingabe des Bildes mit einer Breite von 32, einer Höhe von 32 und einer Tiefe von 3.
- Faltungsschichten: Dies ist der Layer, der zum Extrahieren des Features aus dem Eingabedatensatz verwendet wird. Es wendet eine Reihe lernbarer Filter, die sogenannten Kernel, auf die Eingabebilder an. Die Filter/Kernel sind kleinere Matrizen, normalerweise in der Form 2×2, 3×3 oder 5×5. Es gleitet über die Eingabebilddaten und berechnet das Skalarprodukt zwischen Kernelgewicht und dem entsprechenden Eingabebild-Patch. Die Ausgabe dieser Ebene wird als Feature-Maps bezeichnet. Angenommen, wir verwenden insgesamt 12 Filter für diese Ebene, erhalten wir ein Ausgabevolumen der Dimension 32 x 32 x 12.
- Aktivierungsschicht: Durch das Hinzufügen einer Aktivierungsfunktion zur Ausgabe der vorherigen Schicht fügen Aktivierungsschichten dem Netzwerk Nichtlinearität hinzu. Es wendet eine elementweise Aktivierungsfunktion auf die Ausgabe der Faltungsschicht an. Einige gängige Aktivierungsfunktionen sind wieder aufnehmen : max(0, x), Fischig , Undichtes RELU usw. Das Volumen bleibt unverändert, daher hat das Ausgabevolumen die Abmessungen 32 x 32 x 12.
- Pooling-Schicht: Diese Schicht wird regelmäßig in die Covenets eingefügt und ihre Hauptfunktion besteht darin, die Größe des Volumens zu reduzieren, was die Berechnung beschleunigt, den Speicher reduziert und außerdem eine Überanpassung verhindert. Zwei gängige Arten von Pooling-Schichten sind maximales Pooling Und durchschnittliches Pooling . Wenn wir einen Max-Pool mit 2 x 2 Filtern und Schrittweite 2 verwenden, hat das resultierende Volumen die Dimension 16 x 16 x 12.
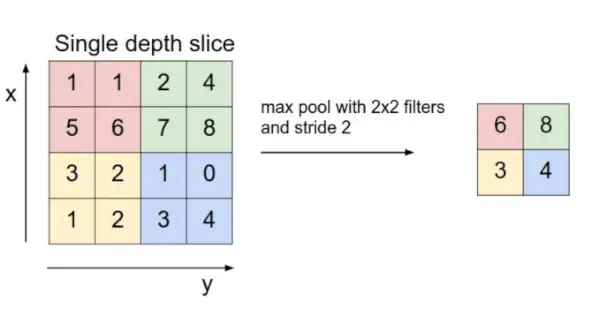
Bildquelle: cs231n.stanford.edu
- Abflachung: Die resultierenden Feature-Maps werden nach der Faltungs- und Pooling-Ebene zu einem eindimensionalen Vektor zusammengefasst, sodass sie zur Kategorisierung oder Regression an eine vollständig verknüpfte Ebene übergeben werden können.
- Vollständig verbundene Schichten: Es übernimmt die Eingabe der vorherigen Ebene und berechnet die endgültige Klassifizierungs- oder Regressionsaufgabe.
Bildquelle: cs231n.stanford.edu
- Ausgabeebene: Die Ausgabe der vollständig verbundenen Schichten wird dann in eine Logistikfunktion für Klassifizierungsaufgaben wie Sigmoid oder Softmax eingespeist, die die Ausgabe jeder Klasse in den Wahrscheinlichkeitswert jeder Klasse umwandelt.
Beispiel:
Betrachten wir ein Bild und wenden wir die Faltungsschicht-, Aktivierungsschicht- und Poolingschicht-Operation an, um das innere Merkmal zu extrahieren.
Eingabebild:
Eingabebild
Schritt:
- Importieren Sie die erforderlichen Bibliotheken
- Stellen Sie den Parameter ein
- Definieren Sie den Kernel
- Laden Sie das Bild und plotten Sie es.
- Formatieren Sie das Bild neu
- Wenden Sie die Faltungsschichtoperation an und zeichnen Sie das Ausgabebild.
- Wenden Sie die Aktivierungsschichtoperation an und zeichnen Sie das Ausgabebild.
- Wenden Sie die Pooling-Layer-Operation an und zeichnen Sie das Ausgabebild.
Python3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
>
Ausgabe :

Originales Graustufenbild
Ausgabe
Vorteile von Convolutional Neural Networks (CNNs):
- Gut geeignet, Muster und Merkmale in Bildern, Videos und Audiosignalen zu erkennen.
- Robust gegenüber Translations-, Rotations- und Skalierungsinvarianz.
- Durchgängige Schulung, keine manuelle Merkmalsextraktion erforderlich.
- Kann große Datenmengen verarbeiten und eine hohe Genauigkeit erzielen.
Nachteile von Convolutional Neural Networks (CNNs):
- Das Training ist rechenintensiv und erfordert viel Speicher.
- Kann anfällig für eine Überanpassung sein, wenn nicht genügend Daten vorhanden sind oder nicht die richtige Regularisierung verwendet wird.
- Erfordert große Mengen beschrifteter Daten.
- Die Interpretierbarkeit ist begrenzt, es ist schwer zu verstehen, was das Netzwerk gelernt hat.
Häufig gestellte Fragen (FAQs)
1: Was ist ein Convolutional Neural Network (CNN)?
Ein Convolutional Neural Network (CNN) ist eine Art Deep-Learning-Neuronales Netzwerk, das sich gut für die Bild- und Videoanalyse eignet. CNNs verwenden eine Reihe von Faltungs- und Pooling-Schichten, um Merkmale aus Bildern und Videos zu extrahieren und diese Merkmale dann zum Klassifizieren oder Erkennen von Objekten oder Szenen zu verwenden.
2: Wie funktionieren CNNs?
CNNs funktionieren, indem sie eine Reihe von Faltungs- und Pooling-Schichten auf ein Eingabebild oder -video anwenden. Faltungsschichten extrahieren Merkmale aus der Eingabe, indem sie einen kleinen Filter oder Kernel über das Bild oder Video gleiten lassen und das Skalarprodukt zwischen dem Filter und der Eingabe berechnen. Pooling-Schichten führen dann ein Downsampling der Ausgabe der Faltungsschichten durch, um die Dimensionalität der Daten zu reduzieren und sie recheneffizienter zu machen.
3: Welche häufigen Aktivierungsfunktionen werden in CNNs verwendet?
Zu den in CNNs häufig verwendeten Aktivierungsfunktionen gehören:
- Rectified Linear Unit (ReLU): ReLU ist eine nicht sättigende Aktivierungsfunktion, die recheneffizient und einfach zu trainieren ist.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU ist eine Variante von ReLU, die den Fluss eines kleinen negativen Gradienten durch das Netzwerk ermöglicht. Dies kann dazu beitragen, zu verhindern, dass das Netzwerk während des Trainings abstürzt.
- Parametric Rectified Linear Unit (PReLU): PReLU ist eine Verallgemeinerung von Leaky ReLU, die es ermöglicht, die Steigung des negativen Gradienten zu lernen.
4: Was ist der Zweck der Verwendung mehrerer Faltungsschichten in einem CNN?
Durch die Verwendung mehrerer Faltungsschichten in einem CNN kann das Netzwerk immer komplexere Merkmale aus dem Eingabebild oder -video lernen. Die ersten Faltungsschichten lernen einfache Merkmale wie Kanten und Ecken. Die tieferen Faltungsschichten lernen komplexere Merkmale wie Formen und Objekte.
5: Welche gängigen Regularisierungstechniken werden in CNNs verwendet?
Mithilfe von Regularisierungstechniken wird verhindert, dass CNNs die Trainingsdaten überanpassen. Zu den gängigen Regularisierungstechniken, die in CNNs verwendet werden, gehören:
- Dropout: Dropout lässt während des Trainings zufällig Neuronen aus dem Netzwerk fallen. Dies zwingt das Netzwerk dazu, robustere Funktionen zu lernen, die nicht von einem einzelnen Neuron abhängig sind.
- L1-Regularisierung: Die L1-Regularisierung reguliert der absolute Wert der Gewichte im Netzwerk. Dies kann dazu beitragen, die Anzahl der Gewichte zu reduzieren und das Netzwerk effizienter zu machen.
- L2-Regularisierung: L2-Regularisierung reguliert das Quadrat der Gewichte im Netzwerk. Dies kann auch dazu beitragen, die Anzahl der Gewichte zu reduzieren und das Netzwerk effizienter zu machen.
6: Was ist der Unterschied zwischen einer Faltungsschicht und einer Pooling-Schicht?
Eine Faltungsschicht extrahiert Merkmale aus einem Eingabebild oder -video, während eine Pooling-Schicht die Ausgabe der Faltungsschichten heruntersampelt. Faltungsschichten verwenden eine Reihe von Filtern, um Merkmale zu extrahieren, während Pooling-Schichten verschiedene Techniken zum Downsampling der Daten verwenden, wie z. B. Max-Pooling und Average-Pooling.