Wir lesen die linearen Datenstrukturen wie ein Array, eine verknüpfte Liste, einen Stapel und eine Warteschlange, in denen alle Elemente nacheinander angeordnet sind. Die unterschiedlichen Datenstrukturen werden für unterschiedliche Arten von Daten verwendet.
Bei der Auswahl der Datenstruktur werden einige Faktoren berücksichtigt:
Ein Baum ist auch eine der Datenstrukturen, die hierarchische Daten darstellen. Angenommen, wir möchten die Mitarbeiter und ihre Positionen in hierarchischer Form anzeigen, dann kann dies wie folgt dargestellt werden:
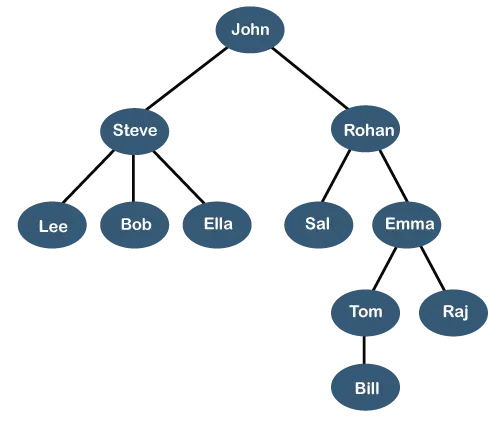
Der obige Baum zeigt die Organisationshierarchie einer Firma. In der obigen Struktur gilt John ist der CEO des Unternehmens, und John hat zwei direkt unterstellte Mitarbeiter mit dem Namen Steve Und Rohan . Steve hat drei direkt unterstellte Mitarbeiter benannt Lee, Bob, Ella Wo Steve ist Manager. Bob hat zwei direkt unterstellte Mitarbeiter benannt Soll Und Emma . Emma hat zwei direkt unterstellte Mitarbeiter benannt Tom Und Raj . Tom hat einen direkten Bericht namens Rechnung . Diese besondere logische Struktur ist als a bekannt Baum . Seine Struktur ähnelt dem echten Baum, daher wird er a genannt Baum . In dieser Struktur ist die Wurzel ist oben und seine Äste bewegen sich nach unten. Daher können wir sagen, dass die Baumdatenstruktur eine effiziente Möglichkeit ist, Daten hierarchisch zu speichern.
Lassen Sie uns einige wichtige Punkte der Baumdatenstruktur verstehen.
- Eine Baumdatenstruktur ist als eine Sammlung von Objekten oder Entitäten definiert, die als Knoten bezeichnet werden und miteinander verknüpft sind, um eine Hierarchie darzustellen oder zu simulieren.
- Eine Baumdatenstruktur ist eine nichtlineare Datenstruktur, da sie nicht sequentiell gespeichert wird. Es handelt sich um eine hierarchische Struktur, da die Elemente in einem Baum auf mehreren Ebenen angeordnet sind.
- In der Baumdatenstruktur wird der oberste Knoten als Wurzelknoten bezeichnet. Jeder Knoten enthält einige Daten, und die Daten können von beliebigem Typ sein. In der obigen Baumstruktur enthält der Knoten den Namen des Mitarbeiters, der Datentyp wäre also eine Zeichenfolge.
- Jeder Knoten enthält einige Daten und den Link oder die Referenz anderer Knoten, die als Kinder bezeichnet werden können.
Einige grundlegende Begriffe, die in der Baumdatenstruktur verwendet werden.
Betrachten wir die Baumstruktur, die unten dargestellt ist:
Govinda-Schauspieler

In der obigen Struktur ist jeder Knoten mit einer Nummer gekennzeichnet. Jeder in der obigen Abbildung gezeigte Pfeil wird als a bezeichnet Verknüpfung zwischen den beiden Knoten.
Eigenschaften der Baumdatenstruktur

Basierend auf den Eigenschaften der Baumdatenstruktur werden Bäume in verschiedene Kategorien eingeteilt.
Implementierung von Tree
Die Baumdatenstruktur kann erstellt werden, indem die Knoten mithilfe der Zeiger dynamisch erstellt werden. Der Baum im Speicher kann wie folgt dargestellt werden:

Die obige Abbildung zeigt die Darstellung der Baumdatenstruktur im Speicher. In der obigen Struktur enthält der Knoten drei Felder. Das zweite Feld speichert die Daten; Das erste Feld speichert die Adresse des linken Kindes und das dritte Feld speichert die Adresse des rechten Kindes.
In der Programmierung kann die Struktur eines Knotens wie folgt definiert werden:
struct node { int data; struct node *left; struct node *right; } Die obige Struktur kann nur für die Binärbäume definiert werden, da der Binärbaum höchstens zwei Kinder haben kann und generische Bäume mehr als zwei Kinder haben können. Die Struktur des Knotens für generische Bäume würde sich von der des Binärbaums unterscheiden.
Anwendungen von Bäumen
Das Folgende sind die Anwendungen von Bäumen:
Arten der Baumdatenstruktur
Im Folgenden sind die Typen einer Baumdatenstruktur aufgeführt:

Es kann geben N Anzahl der Teilbäume in einem allgemeinen Baum. Im allgemeinen Baum sind die Teilbäume ungeordnet, da die Knoten im Teilbaum nicht geordnet werden können.
Jeder nicht leere Baum hat eine nach unten gerichtete Kante, und diese Kanten sind mit den Knoten verbunden, die als bekannt sind untergeordnete Knoten . Der Wurzelknoten ist mit der Ebene 0 gekennzeichnet. Die Knoten, die denselben übergeordneten Knoten haben, werden als bezeichnet geschwister .

Um mehr über den Binärbaum zu erfahren, klicken Sie auf den unten angegebenen Link:
https://www.javatpoint.com/binary-tree
Jeder Knoten im linken Teilbaum muss einen Wert enthalten, der kleiner ist als der Wert des Wurzelknotens, und der Wert jedes Knotens im rechten Teilbaum muss größer sein als der Wert des Wurzelknotens.
Ein Knoten kann mit Hilfe eines benutzerdefinierten Datentyps namens erstellt werden Struktur, Wie nachfolgend dargestellt:
list.sort Java
struct node { int data; struct node *left; struct node *right; } Das Obige ist die Knotenstruktur mit drei Feldern: Datenfeld, das zweite Feld ist der linke Zeiger des Knotentyps und das dritte Feld ist der rechte Zeiger des Knotentyps.
Um mehr über den binären Suchbaum zu erfahren, klicken Sie auf den unten angegebenen Link:
https://www.javatpoint.com/binary-search-tree
Es ist einer der Typen des Binärbaums, oder wir können sagen, dass es sich um eine Variante des binären Suchbaums handelt. Der AVL-Baum erfüllt die Eigenschaft des Binärbaum sowie des binärer Suchbaum . Es handelt sich um einen selbstausgleichenden binären Suchbaum, der von erfunden wurde Adelson Velsky Lindas . Selbstausgleich bedeutet hier, dass die Höhen des linken Teilbaums und des rechten Teilbaums ausgeglichen werden. Dieser Ausgleich wird anhand der gemessen ausgleichender Faktor .
Wir können einen Baum als AVL-Baum betrachten, wenn der Baum sowohl dem binären Suchbaum als auch einem Ausgleichsfaktor entspricht. Der Ausgleichsfaktor kann definiert werden als Differenz zwischen der Höhe des linken Teilbaums und der Höhe des rechten Teilbaums . Der Wert des Ausgleichsfaktors muss entweder 0, -1 oder 1 sein; Daher sollte jeder Knoten im AVL-Baum den Wert des Ausgleichsfaktors entweder 0, -1 oder 1 haben.
Java-Beispielprogramme
Um mehr über den AVL-Baum zu erfahren, klicken Sie auf den unten angegebenen Link:
https://www.javatpoint.com/avl-tree
Der rot-schwarze Baum ist der binäre Suchbaum. Voraussetzung für den Rot-Schwarz-Baum ist, dass wir den binären Suchbaum kennen. In einem binären Suchbaum sollte der Wert des linken Teilbaums kleiner sein als der Wert dieses Knotens und der Wert des rechten Teilbaums sollte größer als der Wert dieses Knotens sein. Wie wir wissen, beträgt die zeitliche Komplexität der binären Suche im Durchschnitt Log2n, der beste Fall ist O(1) und der schlechteste Fall ist O(n).
Wenn eine Operation am Baum ausgeführt wird, möchten wir, dass unser Baum ausgeglichen ist, sodass alle Operationen wie Suchen, Einfügen, Löschen usw. weniger Zeit in Anspruch nehmen und alle diese Operationen die zeitliche Komplexität von haben Protokoll2N.
Der rotschwarze Baum ist ein selbstausgleichender binärer Suchbaum. Der AVL-Baum ist dann auch ein höhenausgleichender binärer Suchbaum Warum brauchen wir einen rot-schwarzen Baum? . Im AVL-Baum wissen wir nicht, wie viele Drehungen erforderlich wären, um den Baum auszugleichen, aber im Rot-Schwarz-Baum sind maximal 2 Drehungen erforderlich, um den Baum auszugleichen. Es enthält ein zusätzliches Bit, das entweder die rote oder die schwarze Farbe eines Knotens darstellt, um den Ausgleich des Baums sicherzustellen.
Die Splay-Tree-Datenstruktur ist auch ein binärer Suchbaum, in dem das zuletzt aufgerufene Element durch Ausführen einiger Rotationsoperationen an der Stammposition des Baums platziert wird. Hier, spreizen bedeutet den Knoten, auf den zuletzt zugegriffen wurde. es ist ein selbstausgleichend binärer Suchbaum ohne explizite Gleichgewichtsbedingung wie AVL Baum.
Möglicherweise ist die Höhe des Spreizbaums nicht ausgeglichen, d. h. die Höhe des linken und des rechten Teilbaums kann unterschiedlich sein, aber die Operationen im Spreizbaum haben die Reihenfolge ruhig Zeit wo N ist die Anzahl der Knoten.
tostring-Methode in Java
Der Spreizbaum ist ein ausgeglichener Baum, kann aber nicht als höhenausgeglichener Baum betrachtet werden, da nach jeder Operation eine Drehung durchgeführt wird, die zu einem ausgeglichenen Baum führt.
Die Treap-Datenstruktur stammt aus der Tree- und Heap-Datenstruktur. Es umfasst also die Eigenschaften von Baum- und Heap-Datenstrukturen. Im binären Suchbaum muss jeder Knoten im linken Teilbaum gleich oder kleiner als der Wert des Wurzelknotens sein und jeder Knoten im rechten Teilbaum muss gleich oder größer als der Wert des Wurzelknotens sein. In der Heap-Datenstruktur enthalten sowohl der rechte als auch der linke Teilbaum größere Schlüssel als der Stamm; Daher können wir sagen, dass der Wurzelknoten den niedrigsten Wert enthält.
In der Treap-Datenstruktur verfügt jeder Knoten über beides Schlüssel Und Priorität Dabei wird der Schlüssel aus dem binären Suchbaum und die Priorität aus der Heap-Datenstruktur abgeleitet.
Der Treap Die Datenstruktur folgt zwei Eigenschaften, die unten angegeben sind:
- Rechtes Kind eines Knotens>=aktueller Knoten und linkes Kind eines Knotens<=current node (binary tree)< li>
- Untergeordnete Elemente eines Teilbaums müssen größer als der Knoten (Heap) sein.
B-Baum ist ein ausgewogener m-Weg Baum wo M definiert die Reihenfolge des Baums. Bisher haben wir gelesen, dass der Knoten nur einen Schlüssel enthält, der B-Baum jedoch mehr als einen Schlüssel und mehr als zwei untergeordnete Elemente haben kann. Es behält immer die sortierten Daten bei. Im Binärbaum ist es möglich, dass sich Blattknoten auf unterschiedlichen Ebenen befinden können, im B-Baum müssen sich jedoch alle Blattknoten auf derselben Ebene befinden.
Wenn die Reihenfolge m ist, hat der Knoten die folgenden Eigenschaften:
- Jeder Knoten in einem B-Baum kann ein Maximum haben M Kinder
- Für minimale untergeordnete Elemente hat ein Blattknoten 0 untergeordnete Elemente, ein Wurzelknoten hat mindestens 2 untergeordnete Elemente und ein interner Knoten hat eine Mindestobergrenze von m/2 untergeordneten Elementen. Der Wert von m ist beispielsweise 5, was bedeutet, dass ein Knoten 5 untergeordnete Knoten haben kann und interne Knoten maximal 3 untergeordnete Knoten enthalten können.
- Jeder Knoten verfügt über maximal (m-1) Schlüssel.
Der Wurzelknoten muss mindestens 1 Schlüssel enthalten und alle anderen Knoten müssen mindestens einen Schlüssel enthalten Decke von m/2 minus 1 Schlüssel.