Ein kurzer Überblick über die derzeitige Notwendigkeit, riesige Datenmengen zu speichern, die für mehrere verwandte oder nicht verwandte Kategorien relevant sind, zeigt, dass Datenbanken bei dem, wofür sie konzipiert sind, äußerst effektiv sein müssen.
Das liegt nicht nur daran, dass wir es mit der Datenmenge zu tun haben, die ständig überarbeitet oder verändert wird, sondern auch deren Dynamik nicht mehr von alleinigem Interesse ist. Das liegt an dem sozialen Wert, den jeder Einzelne ihnen beimisst: Datenbanken sind im wahrsten Sinne des Wortes das Rückgrat des Lebensstils eines Kunden oder des Unternehmenswertes.
Das Entwerfen verschiedener Datenbanktypen bildet den Kern der Funktionalität, die sie den Benutzern bieten. Da es sich bei Daten um eine dynamische Einheit handelt, ist die Art und Weise, wie sie gespeichert werden, sehr unterschiedlich. Dies ist auch der Grund dafür, dass Unternehmen ihre eigenen Datenbanktypen entwerfen, die ihren Anforderungen entsprechen. In diesem Artikel werden wir die Arten von Datenbanken im Detail besprechen.
Arten von Datenbanken
Es gibt verschiedene Arten von Datenbanken, die im Folgenden kurz erläutert werden.
Word-Symbolleiste für den Schnellzugriff
- Hierarchische Datenbanken
- Netzwerkdatenbanken
- Objektorientierte Datenbanken
- Relationale Datenbanken
- Cloud-Datenbank
- Zentralisierte Datenbank
- Betriebsdatenbank
- NoSQL-Datenbanken
Hierarchische Datenbanken
Wie in jeder Hierarchie auch hier Datenbank folgt dem Fortschritt der Kategorisierung von Daten in Rängen oder Ebenen, wobei die Daten auf der Grundlage eines gemeinsamen Verknüpfungspunkts kategorisiert werden. Dies hat zur Folge, dass zwei Dateneinheiten einen niedrigeren Rang haben und die Gemeinsamkeit einen höheren Rang einnehmen würde. Sehen Sie sich das Diagramm unten an:
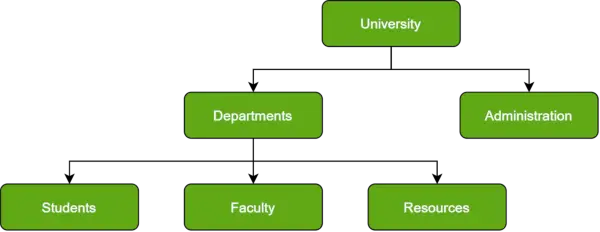
Beispiel für eine hierarchische Datenbank
Beachten Sie, dass sich die Abteilungen und die Verwaltung völlig voneinander unterscheiden und dennoch in den Bereich einer Universität fallen. Sie sind Elemente, die diese Hierarchie bilden.
Eine andere Perspektive empfiehlt die Visualisierung der Organisation der Daten in einer Eltern-Kind-Beziehung, die bei Hinzufügung mehrerer Datenelemente einem Baum ähneln würde. Die untergeordneten Datensätze werden über ein Feld mit dem übergeordneten Datensatz verknüpft, sodass für den übergeordneten Datensatz mehrere untergeordnete Datensätze zulässig sind. Umgekehrt ist dies jedoch nicht möglich.
Beachten Sie, dass hierarchische Datenbanken aufgrund einer solchen Struktur nicht leicht zu verkaufen sind; Das Hinzufügen von Datenelementen erfordert einen langwierigen Durchlauf durch die Datenbank.
Netzwerkdatenbanken
Laienhaft ausgedrückt ist eine Netzwerkdatenbank eine hierarchische Datenbank, allerdings mit einer wesentlichen Änderung. Den untergeordneten Datensätzen wird die Freiheit gegeben, sie mit mehreren übergeordneten Datensätzen zu verknüpfen. Als Ergebnis wird ein Netzwerk oder Netz von Datenbankdateien beobachtet, die mit mehreren Threads verknüpft sind. Beachten Sie, dass die Elemente „Student“, „Fakultät“ und „Ressourcen“ jeweils über zwei übergeordnete Datensätze verfügen, nämlich Abteilungen und Clubs.
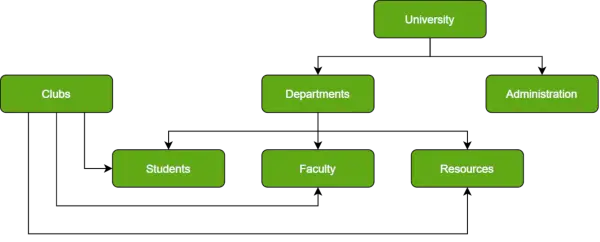
Beispiel einer Netzwerkdatenbank
Was ist die Desktop.ini?
Als komplexes Framework sind Netzwerkdatenbanken sicherlich besser in der Lage, bidirektionale Beziehungen darzustellen. Außerdem begünstigt die konzeptionelle Einfachheit die Verwendung einer einfacheren Datenbankverwaltungssprache.
Der Nachteil besteht darin, dass die Struktur aufgrund ihrer Komplexität nicht verändert werden kann und zudem stark strukturabhängig ist.
Objektorientierte Datenbanken
Wer mit dem Paradigma der objektorientierten Programmierung vertraut ist, kann sich leicht mit diesem Datenbankmodell identifizieren. In einer Datenbank gespeicherte Informationen können als Objekt dargestellt werden, das als Instanz des Datenbankmodells reagiert. Daher kann das Objekt problemlos referenziert und aufgerufen werden. Dadurch wird die Belastung der Datenbank erheblich reduziert.
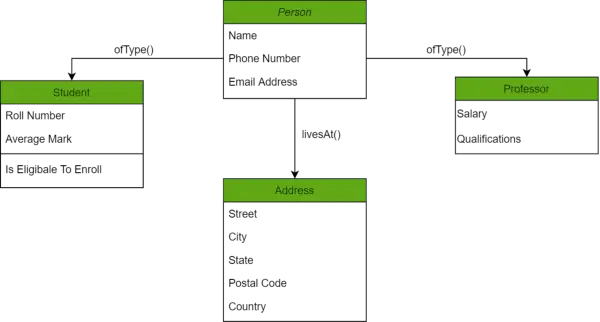
Objektorientiertes Beispiel
Im obigen Diagramm haben wir verschiedene Objekte, die mithilfe von Methoden miteinander verknüpft sind. Man kann die Adresse der Person (dargestellt durch das Person-Objekt) mithilfe der Methode „livesAt()“ ermitteln. Darüber hinaus verfügen diese Objekte über Attribute, bei denen es sich tatsächlich um Datenelemente handelt, die in der Datenbank definiert werden müssen.
Ein Beispiel für ein solches Modell ist die Berkeley DB-Softwarebibliothek, die denselben konzeptionellen Hintergrund verwendet, um schnelle und hocheffiziente Antworten auf Datenbankabfragen aus der eingebetteten Datenbank zu liefern.
Relationale Datenbanken
Diese Datenbanken gelten als die ausgereiftesten aller Datenbanken und sind zusammen mit ihren Verwaltungssystemen führend in der Produktionslinie. In dieser Datenbank steht jede Information in Beziehung zu jeder anderen Information. Dies liegt daran, dass jeder Datenwert in der Datenbank eine eindeutige Identität in Form eines Datensatzes hat.
Beachten Sie, dass in diesem Modell alle Daten tabellarisch aufgeführt sind. Daher ist jede Datenzeile in der Datenbank über einen Primärschlüssel mit einer anderen Zeile verknüpft. Ebenso ist jede Tabelle über einen Fremdschlüssel mit einer anderen Tabelle verknüpft.
Sehen Sie sich das Diagramm unten an und sehen Sie, wie das Konzept der „Schlüssel“ zum Verknüpfen zweier Tabellen verwendet wird.
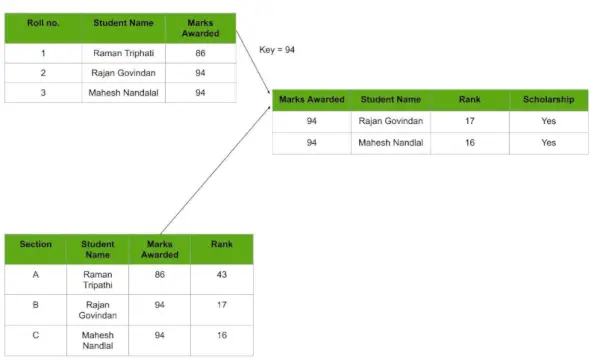
Beispiel für eine relationale Datenbank
Aufgrund dieser Einführung von Tabellen zum Organisieren von Daten ist es äußerst beliebt geworden. Infolgedessen sind sie weithin in Web-Ap-Schnittstellen integriert und dienen als ideale Repositories für Benutzerdaten. Was es noch interessanter macht, ist die einfache Beherrschung, da die für die Interaktion mit der Datenbank verwendete Sprache einfach (in diesem Fall SQL) und leicht zu verstehen ist.
Es lohnt sich auch, sich der Tatsache bewusst zu sein, dass in relationalen Datenbanken das Skalieren und Durchlaufen von Daten im Vergleich zu hierarchischen Datenbanken eine recht leichte Aufgabe ist.
Cloud-Datenbanken
Eine Cloud-Datenbank wird verwendet, wenn Daten eine virtuelle Umgebung zum Speichern und Ausführen über die Cloud-Plattformen erfordern und es viele Cloud-Computing-Dienste für den Zugriff auf die Daten aus den Datenbanken gibt (wie SaaS, Paas usw.).
Es gibt einige Namen für Cloud-Plattformen:
- Amazon Web Services (AWS)
- Google Cloud Platform (GCP)
- Microsoft Azure
- ScienceSoft usw.
Zentralisierte Datenbanken
Eine zentralisierte Datenbank ist im Grunde eine Art Datenbank, die an einem einzigen Ort gespeichert, gespeichert und verwaltet wird. Sie ist sicherer, wenn der Benutzer die Daten aus der zentralisierten Datenbank abrufen möchte.
Vorteile
- Datensicherheit
- Reduzierte Redundanz
- Konsistenz
Nachteile
- Die Größe der zentralisierten Datenbank ist groß, was die Antwort- und Abrufzeit erhöht.
- Es ist nicht einfach, es zu ändern, zu löschen und zu aktualisieren.
Persönliche Datenbanken
Das Sammeln und Speichern der Daten auf einem eigenen System und diese Art von Datenbanken ist grundsätzlich für den einzelnen Benutzer konzipiert.
Python-Pfadeinstellung
Vorteile
- Es ist einfach zu handhaben
- Es nimmt weniger Platz ein
Betriebsdatenbanken
Es wird zum Erstellen, Aktualisieren und Löschen der Datenbank in Echtzeit verwendet und ist im Wesentlichen für die Ausführung und Handhabung des täglichen Datenbetriebs in Organisationen und Unternehmen konzipiert.
Vorteile
- leicht zu holen.
- Strukturierte Daten
- Echtzeitverarbeitung
NoSQL-Datenbanken
Ein NoSQL, das sich ursprünglich auf Nicht-SQL oder nicht-relationale Datenbank bezieht, ist eine Datenbank, die einen Mechanismus zum Speichern und Abrufen von Daten bereitstellt. Diese Daten werden auf andere Weise modelliert als durch die tabellarischen Beziehungen, die in relationalen Datenbanken verwendet werden.
Eine NoSQL-Datenbank zeichnet sich durch ein einfaches Design, eine einfachere horizontale Skalierung auf Maschinencluster und eine genauere Kontrolle der Verfügbarkeit aus. Die von NoSQL-Datenbanken verwendeten Datenstrukturen unterscheiden sich von denen, die standardmäßig in relationalen Datenbanken verwendet werden, wodurch einige Vorgänge in NoSQL schneller werden. Die Eignung einer bestimmten NoSQL-Datenbank hängt von dem Problem ab, das sie lösen soll. Von NoSQL-Datenbanken verwendete Datenstrukturen werden manchmal auch als flexibler angesehen als relationale Datenbanktabellen.
MongoDB fällt in die Kategorie der dokumentbasierten NoSQL-Datenbanken.
Vorteile von NoSQL
Die Arbeit mit NoSQL-Datenbanken wie MongoDB und Cassandra bietet viele Vorteile. Die Hauptvorteile sind hohe Skalierbarkeit und hohe Verfügbarkeit.
Nachteile von NoSQL
NoSQL hat die folgenden Nachteile.
- NoSQL ist eine Open-Source-Datenbank.
- GUI ist nicht verfügbar
- Backup ist eine Schwachstelle für einige NoSQL-Datenbanken wie MongoDB.
- Große Dokumentgröße.
Dies sind nur einige Arten von Datenbankstrukturen, die die in der Branche weit verbreiteten Grundkonzepte darstellen. Allerdings konzentrieren sich Kunden, wie bereits erwähnt, in der Regel auf die Erstellung von Datenbanken, die ihren eigenen Anforderungen entsprechen. um Daten in einem Schema zu speichern, das eine variable Funktionalität basierend auf seinem Bauplan darstellt. Daher ist der Entwicklungsspielraum in Bezug auf Datenbanken und Datenbankverwaltungssysteme groß.
Häufig gestellte Fragen
F.1: Was sind die gängigsten SQL-Datenbanktypen?
Antwort:
Relationale Datenbanken und nicht-relationale Datenbanken sind die beiden grundlegenden Kategorien von Datenbanken in SQL.
F.2: Welche NewSQL-Datenbanken werden am häufigsten verwendet?
Antwort:
Die beliebtesten NewSQL-Datenbanken sind CockroachDB und NuoDB, Spanner usw.
F.3: Was ist in SQL eine Datenbank?
Antwort:
C++-Prototypfunktion
Eine Datenbank in SQL ist eine organisierte Sammlung strukturierter Daten. Datenbanken helfen uns bei der effizienten Speicherung, dem Zugriff und der Bearbeitung von Daten, die auf einem Computersystem oder Server gespeichert sind.