Tierpfleger ist ein verteilter Open-Source-Koordinierungsdienst für verteilte Anwendungen. Es stellt einen einfachen Satz von Grundelementen bereit, um Dienste auf höherer Ebene für die Synchronisierung, Konfigurationswartung sowie Gruppierung und Benennung zu implementieren.
In einem verteilten System gibt es mehrere Knoten oder Maschinen, die miteinander kommunizieren und ihre Aktionen koordinieren müssen. ZooKeeper bietet eine Möglichkeit sicherzustellen, dass diese Knoten einander kennen und ihre Aktionen koordinieren können. Dies geschieht durch die Verwaltung eines hierarchischen Baums von Datenknoten namens Znodes , das zum Speichern und Abrufen von Daten sowie zum Verwalten von Statusinformationen verwendet werden kann. ZooKeeper stellt eine Reihe von Grundelementen wie Sperren, Barrieren und Warteschlangen bereit, mit denen die Aktionen von Knoten in einem verteilten System koordiniert werden können. Es bietet außerdem Funktionen wie Leader-Wahl, Failover und Wiederherstellung, die dazu beitragen können, dass das System ausfallsicher ist. ZooKeeper wird häufig in verteilten Systemen wie Hadoop, Kafka und HBase verwendet und ist zu einem wesentlichen Bestandteil vieler verteilter Anwendungen geworden.
Warum brauchen wir es?
- Koordinierungsdienste : Die Integration/Kommunikation von Diensten in einer verteilten Umgebung.
- Es ist komplex, Koordinierungsdienste richtig zu gestalten. Sie sind besonders anfällig für Fehler wie Race Conditions und Deadlocks.
- Rennbedingung -Zwei oder mehr Systeme versuchen, eine Aufgabe auszuführen.
- Deadlocks – Zwei oder mehr Vorgänge warten aufeinander.
- Um die Koordination zwischen verteilten Umgebungen zu vereinfachen, haben sich Entwickler eine Idee namens zookeeper ausgedacht, damit sie verteilte Anwendungen nicht von der Verantwortung entbinden müssen, Koordinationsdienste von Grund auf zu implementieren.
Was ist ein verteiltes System?
- Mehrere Computersysteme arbeiten an einem einzigen Problem.
- Dabei handelt es sich um ein Netzwerk, das aus autonomen Computern besteht, die über verteilte Middleware miteinander verbunden sind.
- Hauptmerkmale : Gleichzeitig, gemeinsame Nutzung von Ressourcen, unabhängig, global, größere Fehlertoleranz und Preis-Leistungs-Verhältnis sind viel besser.
- Hauptziel s: Transparenz, Zuverlässigkeit, Leistung, Skalierbarkeit.
- Herausforderungen : Sicherheit, Fehler, Koordination und Ressourcenfreigabe.
Koordinationsherausforderung
- Warum ist die Koordination in einem verteilten System das schwierige Problem?
- Koordinations- oder Konfigurationsmanagement für eine verteilte Anwendung mit vielen Systemen.
- Masterknoten, auf dem die Clusterdaten gespeichert werden.
- Worker-Knoten oder Slave-Knoten erhalten die Daten von diesem Master-Knoten.
- der Punkt des Versagens.
- Die Synchronisierung ist nicht einfach.
- Eine sorgfältige Konzeption und Umsetzung sind erforderlich.
Apache Zookeeper
Apache Zookeeper ist ein verteilter Open-Source-Koordinationsdienst für verteilte Systeme. Es bietet verteilten Anwendungen einen zentralen Ort zum Speichern von Daten, zur Kommunikation untereinander und zur Koordinierung von Aktivitäten. Zookeeper wird in verteilten Systemen verwendet, um verteilte Prozesse und Dienste zu koordinieren. Es bietet ein einfaches, baumstrukturiertes Datenmodell, eine einfache API und ein verteiltes Protokoll, um Datenkonsistenz und -verfügbarkeit sicherzustellen. Zookeeper ist äußerst zuverlässig und fehlertolerant und kann einen hohen Lese- und Schreibdurchsatz verarbeiten.
Zookeeper ist in Java implementiert und wird häufig in verteilten Systemen verwendet, insbesondere im Hadoop-Ökosystem. Es ist ein Projekt der Apache Software Foundation und wird unter der Apache-Lizenz 2.0 veröffentlicht.
Architektur von Zookeeper
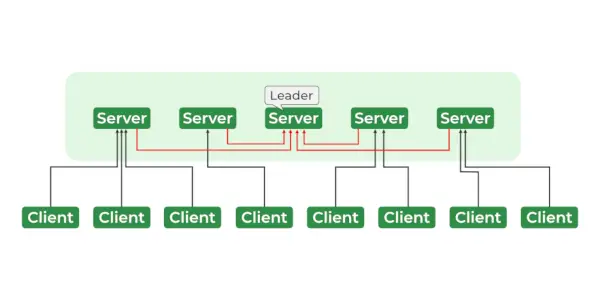
Zookeeper-Dienste
Die ZooKeeper-Architektur besteht aus einer Hierarchie von Knoten, sogenannten Znodes, die in einer baumartigen Struktur organisiert sind. Jeder Znode kann Daten speichern und verfügt über eine Reihe von Berechtigungen, die den Zugriff auf den Znode steuern. Die Znodes sind in einem hierarchischen Namespace organisiert, ähnlich einem Dateisystem. An der Wurzel der Hierarchie befindet sich der Root-Znode, und alle anderen Znodes sind untergeordnete Elemente des Root-Znodes. Die Hierarchie ähnelt einer Dateisystemhierarchie, in der jeder Knoten untergeordnete und untergeordnete Knoten usw. haben kann.
Wichtige Komponenten in Zookeeper
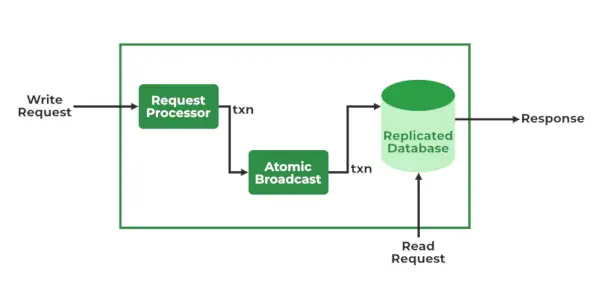
ZooKeeper-Dienste
- Anführer und Anhänger
- Auftragsverarbeiter – Aktiv im Leader Node und ist für die Verarbeitung von Schreibanfragen verantwortlich. Nach der Verarbeitung sendet es Änderungen an die Follower-Knoten
- Atomsendung – Sowohl im Leader-Knoten als auch im Follower-Knoten vorhanden. Es ist dafür verantwortlich, die Änderungen an andere Knoten zu senden.
- In-Memory-Datenbanken (Replizierte Datenbanken) – Sie sind für die Speicherung der Daten im Zookeeper verantwortlich. Jeder Knoten enthält seine eigenen Datenbanken. Die Daten werden auch in das Dateisystem geschrieben, um bei Problemen mit dem Cluster eine Wiederherstellung zu ermöglichen.
Andere Komponenten
- Klient – Einer der Knoten in unserem verteilten Anwendungscluster. Zugriff auf Informationen vom Server. Jeder Client sendet eine Nachricht an den Server, um ihm mitzuteilen, dass der Client aktiv ist.
- Server – Bietet dem Kunden alle Dienstleistungen. Gibt dem Kunden eine Bestätigung.
- Ensemble – Gruppe von Zookeeper-Servern. Die Mindestanzahl an Knoten, die zur Bildung eines Ensembles erforderlich sind, beträgt 3.
Zookeeper-Datenmodell
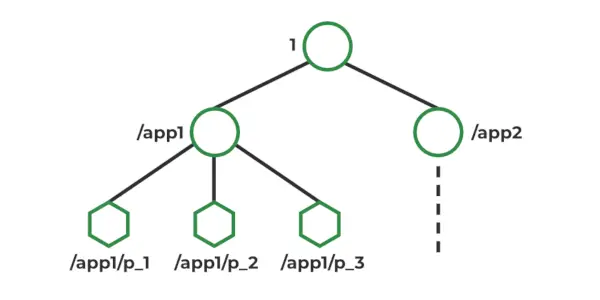
ZooKeeper-Datenmodell
In Zookeeper werden Daten in einem hierarchischen Namespace gespeichert, ähnlich einem Dateisystem. Jeder Knoten im Namespace wird als Znode bezeichnet und kann Daten speichern und untergeordnete Knoten haben. Znodes ähneln Dateien und Verzeichnissen in einem Dateisystem. Zookeeper bietet eine einfache API zum Erstellen, Lesen, Schreiben und Löschen von Znodes. Es bietet auch Mechanismen zum Erkennen von Änderungen an den in Znodes gespeicherten Daten, wie z. B. Uhren und Trigger. Znodes pflegen eine Statistikstruktur, die Folgendes umfasst: Versionsnummer, ACL, Zeitstempel, Datenlänge
Arten von Znodes :
- Beharrlichkeit : Lebendig, bis sie explizit gelöscht werden.
- Flüchtig : Aktiv, bis die Clientverbindung aktiv ist.
- Sequentiell : Entweder dauerhaft oder vergänglich.
Warum brauchen wir ZooKeeper im Hadoop?
Zookeeper wird zum Verwalten und Koordinieren der Knoten in einem Hadoop-Cluster verwendet, einschließlich NameNode, DataNode und ResourceManager. In einem Hadoop-Cluster hilft Zookeeper dabei:
- Konfigurationsinformationen verwalten: Zookeeper speichert die Konfigurationsinformationen für den Hadoop-Cluster, einschließlich des Speicherorts von NameNode, DataNode und ResourceManager.
- Verwalten Sie den Status des Clusters: Zookeeper verfolgt den Status der Knoten im Hadoop-Cluster und kann verwendet werden, um zu erkennen, wenn ein Knoten ausgefallen ist oder nicht mehr verfügbar ist.
- Koordinieren Sie verteilte Prozesse: Zookeeper kann verwendet werden, um verteilte Prozesse wie Jobplanung und Ressourcenzuweisung über die Knoten in einem Hadoop-Cluster hinweg zu koordinieren.
Zookeeper trägt dazu bei, die Verfügbarkeit und Zuverlässigkeit eines Hadoop-Clusters sicherzustellen, indem es einen zentralen Koordinationsdienst für die Knoten im Cluster bereitstellt.
Wie funktioniert ZooKeeper in Hadoop?
ZooKeeper arbeitet als verteiltes Dateisystem und stellt einen einfachen Satz von APIs zur Verfügung, die es Clients ermöglichen, Daten im Dateisystem zu lesen und zu schreiben. Es speichert seine Daten in einer baumartigen Struktur namens Znode, die man sich als Datei oder Verzeichnis in einem herkömmlichen Dateisystem vorstellen kann. ZooKeeper verwendet einen Konsensalgorithmus, um sicherzustellen, dass alle seine Server eine konsistente Ansicht der in den Znodes gespeicherten Daten haben. Das bedeutet, dass, wenn ein Client Daten auf einen Znode schreibt, diese Daten auf alle anderen Server im ZooKeeper-Ensemble repliziert werden.
Ein wichtiges Merkmal von ZooKeeper ist seine Fähigkeit, die Vorstellung einer Uhr zu unterstützen. Eine Überwachung ermöglicht es einem Client, sich für Benachrichtigungen zu registrieren, wenn sich die in einem Znode gespeicherten Daten ändern. Dies kann nützlich sein, um Änderungen an den in ZooKeeper gespeicherten Daten zu überwachen und auf diese Änderungen in einem verteilten System zu reagieren.
In Hadoop wird ZooKeeper für verschiedene Zwecke verwendet, darunter:
- Speichern von Konfigurationsinformationen: ZooKeeper wird zum Speichern von Konfigurationsinformationen verwendet, die von mehreren Hadoop-Komponenten gemeinsam genutzt werden. Beispielsweise könnte es verwendet werden, um die Standorte von NameNodes in einem Hadoop-Cluster oder die Adressen von JobTracker-Knoten zu speichern.
- Bereitstellung verteilter Synchronisierung: ZooKeeper wird verwendet, um die Aktivitäten verschiedener Hadoop-Komponenten zu koordinieren und sicherzustellen, dass sie konsistent zusammenarbeiten. Beispielsweise kann damit sichergestellt werden, dass in einem Hadoop-Cluster jeweils nur ein NameNode aktiv ist.
- Benennung beibehalten: ZooKeeper wird verwendet, um einen zentralen Benennungsdienst für Hadoop-Komponenten zu verwalten. Dies kann nützlich sein, um Ressourcen in einem verteilten System zu identifizieren und zu lokalisieren.
ZooKeeper ist eine wesentliche Komponente von Hadoop und spielt eine entscheidende Rolle bei der Koordinierung der Aktivitäten seiner verschiedenen Unterkomponenten.
Lesen und Schreiben in Apache Zookeeper
ZooKeeper bietet eine einfache und zuverlässige Schnittstelle zum Lesen und Schreiben von Daten. Die Daten werden in einem hierarchischen Namespace, ähnlich einem Dateisystem, mit Knoten namens Znodes gespeichert. Jeder Knoten kann Daten speichern und untergeordnete Knoten haben. ZooKeeper-Clients können mithilfe der Methoden getData() bzw. setData() Daten auf diese Znodes lesen und schreiben. Hier ist ein Beispiel für das Lesen und Schreiben von Daten mithilfe der ZooKeeper Java API:
Java
// Connect to the ZooKeeper ensemble> ZooKeeper zk =>new> ZooKeeper(>'localhost:2181'>,>3000>,>null>);> // Write data to the znode '/myZnode'> String path =>'/myZnode'>;> String data =>'hello world'>;> zk.create(path, data.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);> // Read data from the znode '/myZnode'> byte>[] bytes = zk.getData(path,>false>,>null>);> String readData =>new> String(bytes);> // Prints 'hello world'> System.out.println(readData);> // Closing the connection> // to the ZooKeeper ensemble> zk.close();> |
>
>
Python3
from> kazoo.client>import> KazooClient> # Connect to ZooKeeper> zk>=> KazooClient(hosts>=>'localhost:2181'>)> zk.start()> # Create a node with some data> zk.ensure_path(>'/gfg_node'>)> zk.>set>(>'/gfg_node'>, b>'some_data'>)> # Read the data from the node> data, stat>=> zk.get(>'/gfg_node'>)> print>(data)> # Stop the connection to ZooKeeper> zk.stop()> |
>
Array-Liste sortieren
>
Sitzung und Uhren
Sitzung
- Anforderungen in einer Sitzung werden in FIFO-Reihenfolge ausgeführt.
- Sobald die Sitzung eingerichtet ist, wird die Session-ID wird dem Kunden zugewiesen.
- Kunde sendet Herzschläge um die Sitzung gültig zu halten
- Das Sitzungszeitlimit wird normalerweise in Millisekunden angegeben
Uhren
- Uhren sind Mechanismen für Clients, um Benachrichtigungen über Änderungen im Zookeeper zu erhalten
- Der Client kann beim Lesen eines bestimmten Knotens zusehen.
- Znodes-Änderungen sind Modifikationen von Daten, die mit den Znodes verknüpft sind, oder Änderungen an den untergeordneten Znodes.
- Uhren werden nur einmal ausgelöst.
- Wenn die Sitzung abgelaufen ist, werden auch die Überwachungen entfernt.