- Der Distanzvektoralgorithmus ist ein dynamischer Algorithmus.
- Es wird hauptsächlich in ARPANET und RIP verwendet.
- Jeder Router verwaltet eine Abstandstabelle, die als bekannt ist Vektor .
Drei Schlüssel zum Verständnis der Funktionsweise des Distanzvektor-Routing-Algorithmus:
Distanzvektor-Routing-Algorithmus
Lass dX(y) seien die Kosten des kostengünstigsten Pfades vom Knoten x zum Knoten y. Die geringsten Kosten werden durch die Bellman-Ford-Gleichung in Beziehung gesetzt.
d<sub>x</sub>(y) = min<sub>v</sub>{c(x,v) + d<sub>v</sub>(y)} Wo Die Minv ist die Gleichung, die für alle x Nachbarn verwendet wird. Wenn wir nach der Reise von x nach v den kostengünstigsten Weg von v nach y betrachten, betragen die Wegkosten c(x,v)+dIn(y). Die geringsten Kosten von x nach y sind das Minimum von c(x,v)+dIn(y) alle Nachbarn übernommen.
Beim Distance Vector Routing-Algorithmus enthält der Knoten x die folgenden Routing-Informationen:
- Für jeden Nachbarn v sind die Kosten c(x,v) die Pfadkosten von x zum direkt angeschlossenen Nachbarn v.
- Der Distanzvektor x, also DX= [ DX(y): y in N ], enthält die Kosten für alle Ziele, y, in N.
- Der Distanzvektor jedes seiner Nachbarn, d. h. DIn= [ DIn(y): y in N ] für jeden Nachbarn v von x.
Distanzvektor-Routing ist ein asynchroner Algorithmus, bei dem Knoten x die Kopie seines Distanzvektors an alle seine Nachbarn sendet. Wenn Knoten x den neuen Distanzvektor von einem seiner Nachbarvektoren v empfängt, speichert er den Distanzvektor von v und verwendet die Bellman-Ford-Gleichung, um seinen eigenen Distanzvektor zu aktualisieren. Die Gleichung ist unten angegeben:
Linux-Betriebssystem
d<sub>x</sub>(y) = min<sub>v</sub>{ c(x,v) + d<sub>v</sub>(y)} for each node y in N Der Knoten x hat seine eigene Distanzvektortabelle mithilfe der obigen Gleichung aktualisiert und sendet seine aktualisierte Tabelle an alle seine Nachbarn, damit diese ihre eigenen Distanzvektoren aktualisieren können.
Algorithmus
At each node x, <p> <strong>Initialization</strong> </p> for all destinations y in N: D<sub>x</sub>(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞ for each neighbor w D<sub>w</sub>(y) = ? for all destination y in N. for each neighbor w send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to w <strong>loop</strong> <strong>wait</strong> (until I receive any distance vector from some neighbor w) for each y in N: D<sub>x</sub>(y) = minv{c(x,v)+D<sub>v</sub>(y)} If D<sub>x</sub>(y) is changed for any destination y Send distance vector D<sub>x</sub> = [ D<sub>x</sub>(y) : y in N ] to all neighbors <strong>forever</strong> Hinweis: Im Distanzvektoralgorithmus aktualisiert Knoten x seine Tabelle, wenn er entweder eine Kostenänderung in einem direkt verbundenen Knoten feststellt oder eine Vektoraktualisierung von einem Nachbarn erhält.
Lassen Sie uns anhand eines Beispiels verstehen:
Informationen teilen
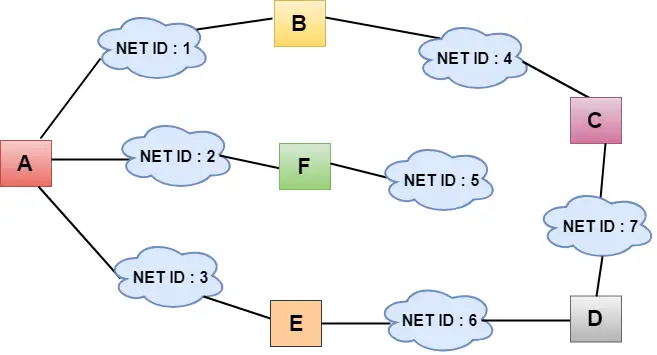
- In der obigen Abbildung stellt jede Wolke das Netzwerk dar und die Zahl innerhalb der Wolke stellt die Netzwerk-ID dar.
- Alle LANs sind durch Router verbunden und werden in Kästchen mit der Bezeichnung A, B, C, D, E, F dargestellt.
- Der Distanzvektor-Routing-Algorithmus vereinfacht den Routing-Prozess, indem er davon ausgeht, dass die Kosten für jede Verbindung eine Einheit betragen. Daher kann die Effizienz der Übertragung anhand der Anzahl der Verbindungen zum Ziel gemessen werden.
- Beim Distanzvektor-Routing basieren die Kosten auf der Hop-Anzahl.

In der obigen Abbildung sehen wir, dass der Router das Wissen an die unmittelbaren Nachbarn sendet. Die Nachbarn ergänzen dieses Wissen zu ihrem eigenen Wissen und senden die aktualisierte Tabelle an ihre eigenen Nachbarn. Auf diese Weise erhalten Router ihre eigenen Informationen sowie die neuen Informationen über die Nachbarn.
Routing-Tabelle
Es finden zwei Prozesse statt:
- Erstellen der Tabelle
- Aktualisieren der Tabelle
Erstellen der Tabelle
Zunächst wird für jeden Router eine Routing-Tabelle erstellt, die mindestens drei Arten von Informationen enthält, z. B. die Netzwerk-ID, die Kosten und den nächsten Hop.


- In der obigen Abbildung sind die Original-Routing-Tabellen aller Router dargestellt. In einer Routing-Tabelle stellt die erste Spalte die Netzwerk-ID dar, die zweite Spalte stellt die Kosten der Verbindung dar und die dritte Spalte ist leer.
- Diese Routing-Tabellen werden an alle Nachbarn gesendet.
Zum Beispiel:
A sends its routing table to B, F & E. B sends its routing table to A & C. C sends its routing table to B & D. D sends its routing table to E & C. E sends its routing table to A & D. F sends its routing table to A.
Aktualisieren der Tabelle
- Wenn A eine Routing-Tabelle von B erhält, verwendet er deren Informationen, um die Tabelle zu aktualisieren.
- Die Routing-Tabelle von B zeigt, wie sich die Pakete zu den Netzwerken 1 und 4 bewegen können.
- Der B ist ein Nachbar des A-Routers, die Pakete von A nach B können in einem Hop erreicht werden. Also wird 1 zu allen in der B-Tabelle angegebenen Kosten addiert und die Summe ergibt die Kosten für die Erreichung eines bestimmten Netzwerks.

- Nach der Anpassung kombiniert A diese Tabelle dann mit seiner eigenen Tabelle, um eine kombinierte Tabelle zu erstellen.

- Die kombinierte Tabelle kann einige doppelte Daten enthalten. In der obigen Abbildung enthält die kombinierte Tabelle von Router A die doppelten Daten, sodass nur die Daten gespeichert werden, die die niedrigsten Kosten verursachen. Beispielsweise kann A die Daten auf zwei Arten an Netzwerk 1 senden. Der erste, der keinen Next-Router verwendet, kostet also einen Hop. Der zweite erfordert zwei Hops (A nach B, dann B nach Netzwerk 1). Die erste Option hat die geringsten Kosten, daher wird sie beibehalten und die zweite Option verworfen.

- Der Prozess der Erstellung der Routing-Tabelle wird für alle Router fortgesetzt. Jeder Router erhält die Informationen von den Nachbarn und aktualisiert die Routing-Tabelle.
Die endgültigen Routing-Tabellen aller Router sind unten aufgeführt:
