Divide and Conquer ist ein algorithmisches Muster. Bei algorithmischen Methoden besteht das Design darin, einen Streit über eine große Eingabe zu nehmen, die Eingabe in kleinere Teile zu zerlegen, das Problem für jedes der kleinen Teile zu entscheiden und dann die stückweisen Lösungen zu einer globalen Lösung zusammenzuführen. Dieser Mechanismus zur Lösung des Problems wird Divide & Conquer-Strategie genannt.
Der Divide and Conquer-Algorithmus besteht aus einem Streit mit den folgenden drei Schritten.
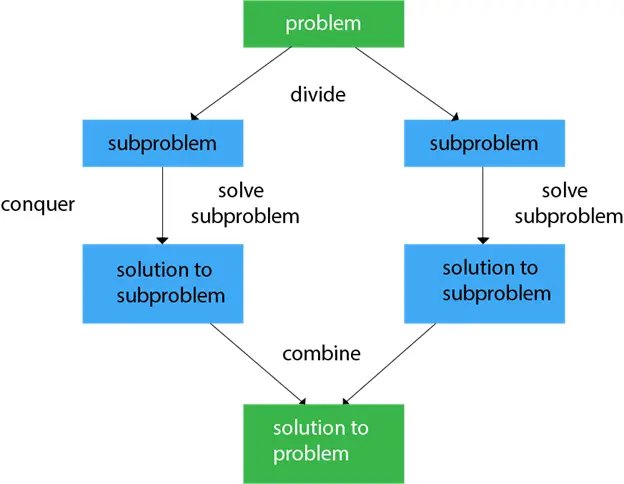
Im Allgemeinen können wir dem folgen Teile und herrsche Vorgehensweise in einem dreistufigen Prozess.
Beispiele: Die spezifischen Computeralgorithmen basieren auf dem Divide & Conquer-Ansatz:
- Maximales und minimales Problem
- Binäre Suche
- Sortieren (Zusammenführungssortierung, Schnellsortierung)
- Turm von Hanoi.
Grundlagen der Divide & Conquer-Strategie:
Es gibt zwei grundlegende Aspekte der Divide & Conquer-Strategie:
- Beziehungsformel
- Stoppbedingung
1. Beziehungsformel: Es ist die Formel, die wir aus der gegebenen Technik generieren. Nach der Generierung der Formel wenden wir die D&C-Strategie an, d. h. wir brechen das Problem rekursiv auf und lösen die kaputten Teilprobleme.
2. Stoppbedingung: Wenn wir das Problem mithilfe der Divide & Conquer-Strategie lösen, müssen wir wissen, wie lange wir Divide & Conquer anwenden müssen. Daher wird die Bedingung, bei der unsere Rekursionsschritte von D&C gestoppt werden müssen, als Stoppbedingung bezeichnet.
Anwendungen des Divide and Conquer-Ansatzes:
Die folgenden Algorithmen basieren auf dem Konzept der Divide and Conquer-Technik:
Vorteile von Divide and Conquer
- „Teile und herrsche“ tendiert dazu, eines der größten Probleme erfolgreich zu lösen, beispielsweise den Turm von Hanoi, ein mathematisches Rätsel. Es ist eine Herausforderung, komplizierte Probleme zu lösen, von denen man keine Grundidee hat, aber mit Hilfe des Divide-and-Conquer-Ansatzes hat es den Aufwand verringert, da es darum geht, das Hauptproblem in zwei Hälften zu teilen und diese dann rekursiv zu lösen. Dieser Algorithmus ist viel schneller als andere Algorithmen.
- Es nutzt den Cache-Speicher effizient, ohne viel Platz zu beanspruchen, da es einfache Teilprobleme im Cache-Speicher löst, anstatt auf den langsameren Hauptspeicher zuzugreifen.
- Sie ist leistungsfähiger als die entsprechende Brute-Force-Technik.
- Da diese Algorithmen die Parallelität verhindern, sind keine Änderungen erforderlich und die Verarbeitung erfolgt durch Systeme mit Parallelverarbeitung.
Nachteile von Divide and Conquer
- Da die meisten seiner Algorithmen auf Rekursion basieren, ist eine hohe Speicherverwaltung erforderlich.
- Ein expliziter Stapel kann den Speicherplatz überbeanspruchen.
- Es kann sogar zum Absturz des Systems kommen, wenn die Rekursion deutlich größer ist als der in der CPU vorhandene Stapel.