Maschinelles Lernen ist der Zweig von Künstliche Intelligenz Der Schwerpunkt liegt auf der Entwicklung von Modellen und Algorithmen, die es Computern ermöglichen, aus Daten zu lernen und sich aus früheren Erfahrungen zu verbessern, ohne dass sie für jede Aufgabe explizit programmiert werden müssen. Vereinfacht ausgedrückt bringt ML den Systemen bei, wie Menschen zu denken und zu verstehen, indem sie aus den Daten lernen.
In diesem Artikel werden wir die verschiedenen untersuchen Arten von Algorithmen für maschinelles Lernen die für zukünftige Anforderungen wichtig sind. Maschinelles Lernen ist im Allgemeinen ein Trainingssystem, um aus vergangenen Erfahrungen zu lernen und die Leistung im Laufe der Zeit zu verbessern. Maschinelles Lernen hilft, riesige Datenmengen vorherzusagen. Es hilft, schnelle und genaue Ergebnisse zu liefern, um profitable Chancen zu nutzen.
Arten des maschinellen Lernens
Es gibt verschiedene Arten des maschinellen Lernens, jede mit besonderen Eigenschaften und Anwendungen. Einige der Haupttypen von Algorithmen für maschinelles Lernen sind wie folgt:
- Überwachtes maschinelles Lernen
- Unüberwachtes maschinelles Lernen
- Halbüberwachtes maschinelles Lernen
- Verstärkungslernen
Arten des maschinellen Lernens
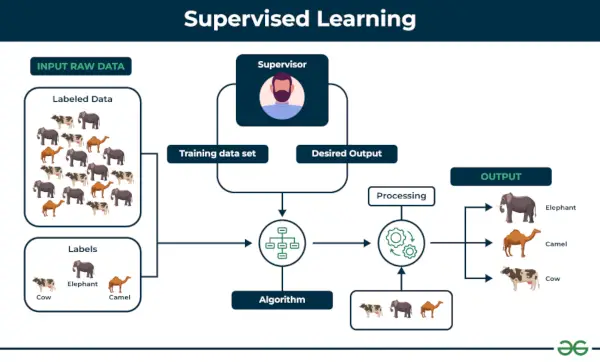
1. Überwachtes maschinelles Lernen
Überwachtes Lernen ist definiert als wenn ein Modell auf a trainiert wird Beschrifteter Datensatz . Beschriftete Datensätze verfügen sowohl über Eingabe- als auch Ausgabeparameter. In Überwachtes Lernen Algorithmen lernen, Punkte zwischen Eingaben und korrekten Ausgaben abzubilden. Es sind sowohl Trainings- als auch Validierungsdatensätze gekennzeichnet.
Überwachtes Lernen
Lassen Sie es uns anhand eines Beispiels verstehen.
Beispiel: Stellen Sie sich ein Szenario vor, in dem Sie einen Bildklassifizierer erstellen müssen, um zwischen Katzen und Hunden zu unterscheiden. Wenn Sie die Datensätze von mit Hunden und Katzen gekennzeichneten Bildern in den Algorithmus einspeisen, lernt die Maschine, anhand dieser gekennzeichneten Bilder zwischen einem Hund und einer Katze zu unterscheiden. Wenn wir neue Hunde- oder Katzenbilder eingeben, die es noch nie zuvor gesehen hat, verwendet es die erlernten Algorithmen und sagt voraus, ob es sich um einen Hund oder eine Katze handelt. Das ist wie überwachtes Lernen Funktioniert, und dabei handelt es sich insbesondere um eine Bildklassifizierung.
Es gibt zwei Hauptkategorien des überwachten Lernens, die im Folgenden erwähnt werden:
- Einstufung
- Rückschritt
Einstufung
Einstufung befasst sich mit Vorhersagen kategorisch Zielvariablen, die diskrete Klassen oder Labels darstellen. Zum Beispiel die Klassifizierung von E-Mails als Spam oder Nicht-Spam oder die Vorhersage, ob bei einem Patienten ein hohes Risiko für Herzerkrankungen besteht. Klassifizierungsalgorithmen lernen, die Eingabemerkmale einer der vordefinierten Klassen zuzuordnen.
Hier sind einige Klassifizierungsalgorithmen:
- Logistische Regression
- Unterstützt Vektormaschine
- Zufälliger Wald
- Entscheidungsbaum
- K-Nächste Nachbarn (KNN)
- Naiver Bayes
Rückschritt
Rückschritt hingegen befasst sich mit Vorhersagen kontinuierlich Zielvariablen, die numerische Werte darstellen. Beispielsweise können Sie den Preis eines Hauses anhand seiner Größe, Lage und Ausstattung vorhersagen oder den Verkauf eines Produkts vorhersagen. Regressionsalgorithmen lernen, die Eingabemerkmale einem kontinuierlichen numerischen Wert zuzuordnen.
Hier sind einige Regressionsalgorithmen:
- Lineare Regression
- Polynomielle Regression
- Ridge-Regression
- Lasso-Regression
- Entscheidungsbaum
- Zufälliger Wald
Vorteile des überwachten maschinellen Lernens
- Überwachtes Lernen Modelle können beim Training eine hohe Genauigkeit aufweisen beschriftete Daten .
- Der Entscheidungsprozess in überwachten Lernmodellen ist oft interpretierbar.
- Es kann oft in vorab trainierten Modellen verwendet werden, was bei der Entwicklung neuer Modelle von Grund auf Zeit und Ressourcen spart.
Nachteile des überwachten maschinellen Lernens
- Das Erkennen von Mustern ist eingeschränkt und es kann zu Problemen mit unsichtbaren oder unerwarteten Mustern kommen, die in den Trainingsdaten nicht vorhanden sind.
- Es kann zeitaufwändig und kostspielig sein, je nachdem, worauf es ankommt beschriftet Nur Daten.
- Dies kann zu schlechten Verallgemeinerungen auf der Grundlage neuer Daten führen.
Anwendungen des überwachten Lernens
Überwachtes Lernen wird in einer Vielzahl von Anwendungen eingesetzt, darunter:
- Bildklassifizierung : Identifizieren Sie Objekte, Gesichter und andere Merkmale in Bildern.
- Verarbeitung natürlicher Sprache: Extrahieren Sie Informationen aus Texten, z. B. Stimmung, Entitäten und Beziehungen.
- Spracherkennung : Gesprochene Sprache in Text umwandeln.
- Empfehlungssysteme : Geben Sie Benutzern personalisierte Empfehlungen.
- Prädiktive Analysen : Prognostizieren Sie Ergebnisse wie Verkäufe, Kundenabwanderung und Aktienkurse.
- Medizinische Diagnose : Erkennen Sie Krankheiten und andere medizinische Beschwerden.
- Entdeckung eines Betruges : Identifizieren Sie betrügerische Transaktionen.
- Autonome Fahrzeuge : Objekte in der Umgebung erkennen und darauf reagieren.
- E-Mail-Spam-Erkennung : E-Mails als Spam oder Nicht-Spam klassifizieren.
- Qualitätskontrolle in der Fertigung : Produkte auf Mängel prüfen.
- Kreditwürdigkeit : Bewerten Sie das Risiko eines Kreditausfalls eines Kreditnehmers.
- Spielen : Charaktere erkennen, Spielerverhalten analysieren und NPCs erstellen.
- Kundendienst : Kundensupportaufgaben automatisieren.
- Wettervorhersage : Machen Sie Vorhersagen für Temperatur, Niederschlag und andere meteorologische Parameter.
- Sportanalyse : Spielerleistung analysieren, Spielvorhersagen treffen und Strategien optimieren.
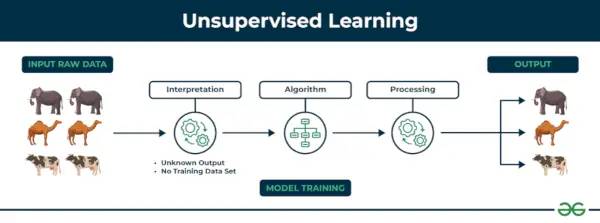
2. Unüberwachtes maschinelles Lernen
Unbeaufsichtigtes Lernen Unüberwachtes Lernen ist eine Art maschinelles Lernen, bei dem ein Algorithmus anhand unbeschrifteter Daten Muster und Beziehungen entdeckt. Im Gegensatz zum überwachten Lernen geht es beim unüberwachten Lernen nicht darum, dem Algorithmus beschriftete Zielausgaben bereitzustellen. Das Hauptziel des unbeaufsichtigten Lernens besteht häufig darin, versteckte Muster, Ähnlichkeiten oder Cluster in den Daten zu entdecken, die dann für verschiedene Zwecke verwendet werden können, beispielsweise zur Datenexploration, Visualisierung, Dimensionsreduzierung und mehr.
Unbeaufsichtigtes Lernen
Lassen Sie es uns anhand eines Beispiels verstehen.
Schalten Sie den Entwicklermodus aus
Beispiel: Bedenken Sie, dass Sie über einen Datensatz verfügen, der Informationen über die Einkäufe enthält, die Sie im Shop getätigt haben. Durch Clustering kann der Algorithmus das gleiche Kaufverhalten bei Ihnen und anderen Kunden gruppieren, wodurch potenzielle Kunden ohne vordefinierte Labels sichtbar werden. Diese Art von Informationen kann Unternehmen dabei helfen, Zielkunden zu gewinnen und Ausreißer zu identifizieren.
Es gibt zwei Hauptkategorien des unbeaufsichtigten Lernens, die im Folgenden erwähnt werden:
- Clustering
- Verband
Clustering
Clustering ist der Prozess der Gruppierung von Datenpunkten in Clustern basierend auf ihrer Ähnlichkeit. Diese Technik ist nützlich, um Muster und Beziehungen in Daten zu identifizieren, ohne dass beschriftete Beispiele erforderlich sind.
Hier sind einige Clustering-Algorithmen:
- K-Means-Clustering-Algorithmus
- Mean-Shift-Algorithmus
- DBSCAN-Algorithmus
- Hauptkomponentenanalyse
- Unabhängige Komponentenanalyse
Verband
Assoziationsregel lernen ing ist eine Technik zum Entdecken von Beziehungen zwischen Elementen in einem Datensatz. Es identifiziert Regeln, die angeben, dass das Vorhandensein eines Elements mit einer bestimmten Wahrscheinlichkeit das Vorhandensein eines anderen Elements impliziert.
Hier sind einige Lernalgorithmen für Assoziationsregeln:
- Apriori-Algorithmus
- Glühen
- FP-Wachstumsalgorithmus
Vorteile des unbeaufsichtigten maschinellen Lernens
- Es hilft, verborgene Muster und verschiedene Beziehungen zwischen den Daten zu entdecken.
- Wird für Aufgaben verwendet wie z Kundensegmentierung, Anomalieerkennung, Und Datenexploration .
- Es erfordert keine gekennzeichneten Daten und reduziert den Aufwand für die Datenkennzeichnung.
Nachteile des unbeaufsichtigten maschinellen Lernens
- Ohne die Verwendung von Labels kann es schwierig sein, die Qualität der Modellausgabe vorherzusagen.
- Die Cluster-Interpretierbarkeit ist möglicherweise nicht klar und bietet möglicherweise keine sinnvollen Interpretationen.
- Es verfügt über Techniken wie Autoencoder Und Dimensionsreduktion die verwendet werden können, um aussagekräftige Merkmale aus Rohdaten zu extrahieren.
Anwendungen des unbeaufsichtigten Lernens
Hier sind einige häufige Anwendungen des unbeaufsichtigten Lernens:
- Clustering : Gruppieren Sie ähnliche Datenpunkte in Clustern.
- Anomalieerkennung : Identifizieren Sie Ausreißer oder Anomalien in Daten.
- Dimensionsreduktion : Reduzieren Sie die Dimensionalität von Daten und bewahren Sie gleichzeitig ihre wesentlichen Informationen.
- Empfehlungssysteme : Schlagen Sie Benutzern Produkte, Filme oder Inhalte basierend auf ihrem bisherigen Verhalten oder ihren Vorlieben vor.
- Themenmodellierung : Entdecken Sie latente Themen in einer Dokumentensammlung.
- Dichteschätzung : Schätzen Sie die Wahrscheinlichkeitsdichtefunktion von Daten.
- Bild- und Videokomprimierung : Reduzieren Sie den für Multimedia-Inhalte erforderlichen Speicherplatz.
- Datenvorverarbeitung : Hilfe bei Datenvorverarbeitungsaufgaben wie Datenbereinigung, Imputation fehlender Werte und Datenskalierung.
- Warenkorbanalyse : Entdecken Sie Assoziationen zwischen Produkten.
- Analyse genomischer Daten : Identifizieren Sie Muster oder gruppieren Sie Gene mit ähnlichen Expressionsprofilen.
- Bildsegmentierung : Bilder in sinnvolle Bereiche segmentieren.
- Community-Erkennung in sozialen Netzwerken : Identifizieren Sie Gemeinschaften oder Gruppen von Einzelpersonen mit ähnlichen Interessen oder Verbindungen.
- Analyse des Kundenverhaltens : Entdecken Sie Muster und Erkenntnisse für bessere Marketing- und Produktempfehlungen.
- Inhaltsempfehlung : Inhalte klassifizieren und mit Tags versehen, um Benutzern die Empfehlung ähnlicher Artikel zu erleichtern.
- Explorative Datenanalyse (EDA) : Erkunden Sie Daten und gewinnen Sie Erkenntnisse, bevor Sie spezifische Aufgaben definieren.
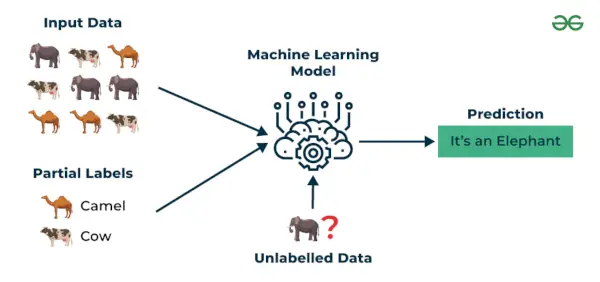
3. Halbüberwachtes Lernen
Halbüberwachtes Lernen ist ein maschineller Lernalgorithmus, der zwischen den arbeitet beaufsichtigt und unbeaufsichtigt Lernen, sodass beides genutzt wird beschriftet und unbeschriftet Daten. Dies ist besonders nützlich, wenn die Beschaffung gekennzeichneter Daten kostspielig, zeitaufwändig oder ressourcenintensiv ist. Dieser Ansatz ist nützlich, wenn der Datensatz teuer und zeitaufwändig ist. Halbüberwachtes Lernen wird gewählt, wenn für gekennzeichnete Daten Fähigkeiten und relevante Ressourcen erforderlich sind, um sie zu trainieren oder daraus zu lernen.
Wir verwenden diese Techniken, wenn wir es mit Daten zu tun haben, die nur wenig beschriftet sind und der Rest davon unbeschriftet ist. Wir können die unbeaufsichtigten Techniken verwenden, um Etiketten vorherzusagen und diese Etiketten dann überwachten Techniken zuzuführen. Diese Technik ist vor allem bei Bilddatensätzen anwendbar, bei denen normalerweise nicht alle Bilder beschriftet sind.
Halbüberwachtes Lernen
Lassen Sie es uns anhand eines Beispiels verstehen.
Beispiel : Bedenken Sie, dass wir ein Sprachübersetzungsmodell erstellen und beschriftete Übersetzungen für jedes Satzpaar ressourcenintensiv sein können. Es ermöglicht den Modellen, aus beschrifteten und unbeschrifteten Satzpaaren zu lernen, wodurch sie genauer werden. Diese Technik hat zu erheblichen Verbesserungen der Qualität maschineller Übersetzungsdienste geführt.
Arten von halbüberwachten Lernmethoden
Es gibt eine Reihe verschiedener halbüberwachter Lernmethoden, jede mit ihren eigenen Merkmalen. Zu den häufigsten gehören:
- Graphbasiertes halbüberwachtes Lernen: Bei diesem Ansatz wird ein Diagramm verwendet, um die Beziehungen zwischen den Datenpunkten darzustellen. Das Diagramm wird dann verwendet, um Beschriftungen von den beschrifteten Datenpunkten an die unbeschrifteten Datenpunkte weiterzugeben.
- Etikettenweitergabe: Dieser Ansatz überträgt Beschriftungen iterativ von den beschrifteten Datenpunkten auf die unbeschrifteten Datenpunkte, basierend auf den Ähnlichkeiten zwischen den Datenpunkten.
- Co-Training: Dieser Ansatz trainiert zwei verschiedene Modelle für maschinelles Lernen auf verschiedenen Teilmengen der unbeschrifteten Daten. Die beiden Modelle werden dann verwendet, um die Vorhersagen des anderen zu kennzeichnen.
- Selbsttraining: Dieser Ansatz trainiert ein maschinelles Lernmodell anhand der gekennzeichneten Daten und verwendet das Modell dann, um Bezeichnungen für die unbeschrifteten Daten vorherzusagen. Das Modell wird dann anhand der beschrifteten Daten und der vorhergesagten Beschriftungen für die unbeschrifteten Daten neu trainiert.
- Generative gegnerische Netzwerke (GANs) : GANs sind eine Art Deep-Learning-Algorithmus, mit dem synthetische Daten generiert werden können. GANs können verwendet werden, um unbeschriftete Daten für halbüberwachtes Lernen zu generieren, indem zwei neuronale Netze, ein Generator und ein Diskriminator, trainiert werden.
Vorteile des halbüberwachten maschinellen Lernens
- Dies führt zu einer besseren Verallgemeinerung im Vergleich zu überwachtes Lernen, da es sowohl beschriftete als auch unbeschriftete Daten akzeptiert.
- Kann auf eine Vielzahl von Daten angewendet werden.
Nachteile des halbüberwachten maschinellen Lernens
- Halbbeaufsichtigt Die Implementierung dieser Methoden kann im Vergleich zu anderen Ansätzen komplexer sein.
- Es braucht noch einiges beschriftete Daten die möglicherweise nicht immer verfügbar oder leicht zu bekommen sind.
- Die unbeschrifteten Daten können sich entsprechend auf die Modellleistung auswirken.
Anwendungen des halbüberwachten Lernens
Hier sind einige häufige Anwendungen des halbüberwachten Lernens:
- Bildklassifizierung und Objekterkennung : Verbessern Sie die Genauigkeit von Modellen, indem Sie einen kleinen Satz beschrifteter Bilder mit einem größeren Satz unbeschrifteter Bilder kombinieren.
- Verarbeitung natürlicher Sprache (NLP) : Verbessern Sie die Leistung von Sprachmodellen und Klassifizierern, indem Sie einen kleinen Satz beschrifteter Textdaten mit einer großen Menge unbeschriftetem Text kombinieren.
- Spracherkennung: Verbessern Sie die Genauigkeit der Spracherkennung, indem Sie eine begrenzte Menge transkribierter Sprachdaten und einen umfangreicheren Satz unbeschrifteter Audiodaten nutzen.
- Empfehlungssysteme : Verbessern Sie die Genauigkeit personalisierter Empfehlungen, indem Sie einen spärlichen Satz von Benutzer-Element-Interaktionen (gekennzeichnete Daten) durch eine Fülle unbeschrifteter Benutzerverhaltensdaten ergänzen.
- Gesundheitswesen und medizinische Bildgebung : Verbessern Sie die medizinische Bildanalyse, indem Sie einen kleinen Satz beschrifteter medizinischer Bilder neben einem größeren Satz unbeschrifteter Bilder verwenden.
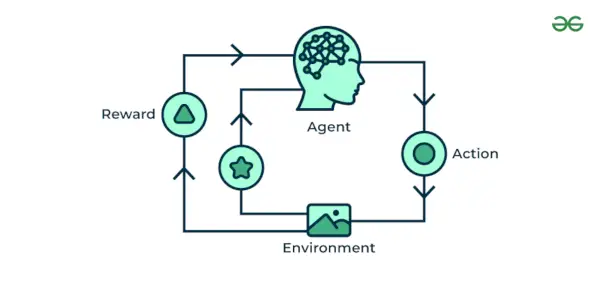
4. Verstärkung des maschinellen Lernens
Verstärkung des maschinellen Lernens Algorithmus ist eine Lernmethode, die mit der Umgebung interagiert, indem sie Aktionen ausführt und Fehler entdeckt. Versuch, Irrtum und Verzögerung sind die wichtigsten Merkmale des verstärkenden Lernens. Bei dieser Technik steigert das Modell seine Leistung kontinuierlich, indem es Belohnungsfeedback verwendet, um das Verhalten oder Muster zu lernen. Diese Algorithmen sind spezifisch für ein bestimmtes Problem, z. Google Self Driving Car, AlphaGo, bei dem ein Bot mit Menschen und sogar sich selbst konkurriert, um im Go Game immer bessere Leistungen zu erbringen. Jedes Mal, wenn wir Daten einspeisen, lernen sie und fügen die Daten zu ihrem Wissen hinzu, das Trainingsdaten sind. Je mehr es also lernt, desto besser wird es trainiert und damit erfahrener.
Hier sind einige der gängigsten Reinforcement-Learning-Algorithmen:
- Q-Learning: Q-Learning ist ein modellfreier RL-Algorithmus, der eine Q-Funktion lernt, die Zustände Aktionen zuordnet. Die Q-Funktion schätzt die erwartete Belohnung für die Durchführung einer bestimmten Aktion in einem bestimmten Zustand.
- SARSA (State-Action-Reward-State-Action): SARSA ist ein weiterer modellfreier RL-Algorithmus, der eine Q-Funktion lernt. Im Gegensatz zum Q-Learning aktualisiert SARSA jedoch die Q-Funktion für die tatsächlich durchgeführte Aktion und nicht für die optimale Aktion.
- Tiefes Q-Learning : Deep Q-Learning ist eine Kombination aus Q-Learning und Deep Learning. Deep Q-Learning nutzt ein neuronales Netzwerk zur Darstellung der Q-Funktion und ermöglicht so das Erlernen komplexer Zusammenhänge zwischen Zuständen und Aktionen.
Verstärkung des maschinellen Lernens
Lassen Sie es uns anhand von Beispielen verstehen.
Beispiel: Bedenken Sie, dass Sie eine Ausbildung absolvieren KI Agent, der ein Spiel wie Schach spielt. Der Agent prüft verschiedene Schritte und erhält je nach Ergebnis positives oder negatives Feedback. Reinforcement Learning findet auch Anwendungen, bei denen sie lernen, Aufgaben durch Interaktion mit ihrer Umgebung auszuführen.
Arten des verstärkenden maschinellen Lernens
Es gibt zwei Haupttypen des verstärkenden Lernens:
Positive Verstärkung
- Belohnt den Agenten für die Durchführung einer gewünschten Aktion.
- Ermutigt den Agenten, das Verhalten zu wiederholen.
- Beispiele: Einem Hund ein Leckerli zum Sitzen geben, in einem Spiel einen Punkt für eine richtige Antwort vergeben.
Negative Verstärkung
- Entfernt einen unerwünschten Reiz, um ein gewünschtes Verhalten zu fördern.
- Hält den Agenten davon ab, das Verhalten zu wiederholen.
- Beispiele: Einen lauten Summer ausschalten, wenn ein Hebel gedrückt wird, eine Strafe vermeiden, indem man eine Aufgabe erledigt.
Vorteile des verstärkenden maschinellen Lernens
- Es verfügt über eine autonome Entscheidungsfindung, die gut für Aufgaben geeignet ist und lernen kann, eine Abfolge von Entscheidungen zu treffen, wie Robotik und Spielen.
- Diese Technik wird bevorzugt, um langfristige Ergebnisse zu erzielen, die nur sehr schwer zu erreichen sind.
- Es wird verwendet, um komplexe Probleme zu lösen, die mit herkömmlichen Techniken nicht gelöst werden können.
Nachteile des verstärkenden maschinellen Lernens
- Das Training von Reinforcement Learning-Agenten kann rechenintensiv und zeitaufwändig sein.
- Reinforcement Learning ist der Lösung einfacher Probleme nicht vorzuziehen.
- Es erfordert viele Daten und einen hohen Rechenaufwand, was es unpraktisch und kostspielig macht.
Anwendungen des verstärkenden maschinellen Lernens
Hier sind einige Anwendungen des Reinforcement Learning:
- Spiele spielen : RL kann Agenten beibringen, Spiele zu spielen, auch komplexe.
- Robotik : RL kann Robotern beibringen, Aufgaben autonom auszuführen.
- Autonome Fahrzeuge : RL kann selbstfahrenden Autos helfen, sich zurechtzufinden und Entscheidungen zu treffen.
- Empfehlungssysteme : RL kann Empfehlungsalgorithmen verbessern, indem es Benutzerpräferenzen lernt.
- Gesundheitspflege : RL kann zur Optimierung von Behandlungsplänen und der Arzneimittelentwicklung eingesetzt werden.
- Verarbeitung natürlicher Sprache (NLP) : RL kann in Dialogsystemen und Chatbots eingesetzt werden.
- Finanzen und Handel : RL kann für den algorithmischen Handel verwendet werden.
- Lieferketten- und Bestandsmanagement : RL kann zur Optimierung von Lieferkettenabläufen eingesetzt werden.
- Energiemanagement : RL kann zur Optimierung des Energieverbrauchs eingesetzt werden.
- KI-Spiele : RL kann verwendet werden, um intelligentere und anpassungsfähigere NPCs in Videospielen zu erstellen.
- Adaptive persönliche Assistenten : RL kann zur Verbesserung persönlicher Assistenten verwendet werden.
- Virtuelle Realität (VR) und Augmented Reality (AR): Mit RL können immersive und interaktive Erlebnisse geschaffen werden.
- Industrielle Steuerung : RL kann zur Optimierung industrieller Prozesse eingesetzt werden.
- Ausbildung : RL kann zur Erstellung adaptiver Lernsysteme verwendet werden.
- Landwirtschaft : RL kann zur Optimierung landwirtschaftlicher Abläufe eingesetzt werden.
Unbedingt überprüfen, unser ausführlicher Artikel über : Algorithmen für maschinelles Lernen
Abschluss
Zusammenfassend lässt sich sagen, dass jede Art des maschinellen Lernens ihren eigenen Zweck erfüllt und zur allgemeinen Rolle bei der Entwicklung verbesserter Datenvorhersagefunktionen beiträgt und das Potenzial hat, verschiedene Branchen zu verändern Datenwissenschaft . Es hilft bei der Bewältigung der massiven Datenproduktion und Verwaltung der Datensätze.
1nf 2nf 3nf
Arten des maschinellen Lernens – FAQs
1. Vor welchen Herausforderungen steht das überwachte Lernen?
Zu den Herausforderungen beim überwachten Lernen gehören vor allem die Beseitigung von Klassenungleichgewichten, qualitativ hochwertige gekennzeichnete Daten und die Vermeidung einer Überanpassung, wenn Modelle bei Echtzeitdaten schlecht abschneiden.
2. Wo können wir überwachtes Lernen anwenden?
Überwachtes Lernen wird häufig für Aufgaben wie die Analyse von Spam-E-Mails, die Bilderkennung und die Stimmungsanalyse eingesetzt.
3. Wie sieht die Zukunft des maschinellen Lernens aus?
Maschinelles Lernen als Zukunftsaussicht könnte in Bereichen wie Wetter- oder Klimaanalyse, Gesundheitssystemen und autonomer Modellierung funktionieren.
4. Welche verschiedenen Arten des maschinellen Lernens gibt es?
Es gibt drei Haupttypen des maschinellen Lernens:
- Überwachtes Lernen
- Unbeaufsichtigtes Lernen
- Verstärkungslernen
5. Was sind die gängigsten Algorithmen für maschinelles Lernen?
Zu den gängigsten Algorithmen für maschinelles Lernen gehören:
- Lineare Regression
- Logistische Regression
- Support-Vektor-Maschinen (SVMs)
- K-nächste Nachbarn (KNN)
- Entscheidungsbäume
- Zufällige Wälder
- Künstliche neurale Netzwerke