Die uninformierte Suche ist eine Klasse von Allzweck-Suchalgorithmen, die auf Brute-Force-Art arbeiten. Uninformierte Suchalgorithmen verfügen über keine weiteren Informationen über den Zustand oder den Suchraum, außer darüber, wie der Baum durchquert werden soll, daher wird dies auch als blinde Suche bezeichnet.
Im Folgenden sind die verschiedenen Arten uninformierter Suchalgorithmen aufgeführt:
1. Breitensuche:
- Die Breitensuche ist die gebräuchlichste Suchstrategie zum Durchsuchen eines Baums oder Diagramms. Dieser Algorithmus durchsucht einen Baum oder ein Diagramm in der Breite und wird daher als Breitensuche bezeichnet.
- Der BFS-Algorithmus beginnt mit der Suche am Wurzelknoten des Baums und erweitert alle Folgeknoten auf der aktuellen Ebene, bevor er zu den Knoten der nächsten Ebene übergeht.
- Der Breitensuchalgorithmus ist ein Beispiel für einen Suchalgorithmus für allgemeine Graphen.
- Breitensuche mithilfe der FIFO-Warteschlangendatenstruktur implementiert.
Vorteile:
- BFS wird eine Lösung bereitstellen, sofern es eine Lösung gibt.
- Wenn es für ein bestimmtes Problem mehr als eine Lösung gibt, stellt BFS die minimale Lösung bereit, die die geringste Anzahl an Schritten erfordert.
Nachteile:
- Es erfordert viel Speicher, da jede Ebene des Baums im Speicher gespeichert werden muss, um die nächste Ebene zu erweitern.
- BFS benötigt viel Zeit, wenn die Lösung weit vom Wurzelknoten entfernt ist.
Beispiel:
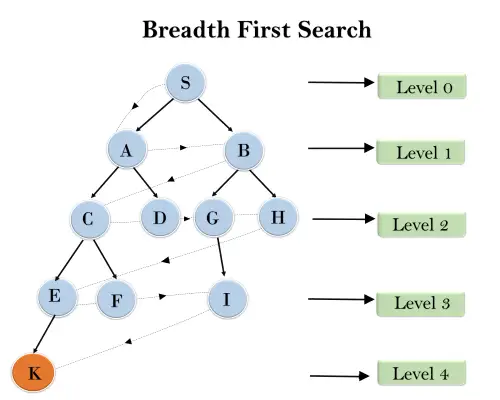
In der folgenden Baumstruktur haben wir die Durchquerung des Baums mithilfe des BFS-Algorithmus vom Wurzelknoten S zum Zielknoten K gezeigt. Der BFS-Suchalgorithmus durchläuft die Durchquerung in Schichten, sodass er dem durch den gepunkteten Pfeil angezeigten Pfad folgt Der zurückgelegte Weg wird sein:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
Zeitkomplexität: Die Zeitkomplexität des BFS-Algorithmus kann durch die Anzahl der Knoten ermittelt werden, die im BFS bis zum flachsten Knoten durchlaufen werden. Dabei ist d = Tiefe der flachsten Lösung und b ein Knoten in jedem Zustand.
T (b) = 1+b2+b3+.......+ bD= O (gebD)
Raumkomplexität: Die räumliche Komplexität des BFS-Algorithmus wird durch die Speichergröße der Grenze angegeben, die O(b) beträgtD).
Vollständigkeit: BFS ist vollständig, was bedeutet, dass BFS eine Lösung findet, wenn sich der flachste Zielknoten in einer endlichen Tiefe befindet.
Optimalität: BFS ist optimal, wenn die Pfadkosten eine nicht abnehmende Funktion der Knotentiefe sind.
2. Tiefensuche
- Die Tiefensuche ist ein rekursiver Algorithmus zum Durchsuchen einer Baum- oder Diagrammdatenstruktur.
- Sie wird als Tiefensuche bezeichnet, da sie vom Wurzelknoten ausgeht und jedem Pfad bis zum Knoten mit der größten Tiefe folgt, bevor zum nächsten Pfad übergegangen wird.
- DFS verwendet für seine Implementierung eine Stapeldatenstruktur.
- Der Prozess des DFS-Algorithmus ähnelt dem BFS-Algorithmus.
Hinweis: Backtracking ist eine Algorithmustechnik zum Finden aller möglichen Lösungen mithilfe von Rekursion.
Vorteil:
Netzwerkbetriebssystem
- DFS benötigt sehr wenig Speicher, da es nur einen Stapel der Knoten auf dem Pfad vom Stammknoten zum aktuellen Knoten speichern muss.
- Das Erreichen des Zielknotens dauert weniger lange als der BFS-Algorithmus (wenn er auf dem richtigen Pfad verläuft).
Nachteil:
- Es besteht die Möglichkeit, dass viele Probleme immer wieder auftreten, und es gibt keine Garantie dafür, dass eine Lösung gefunden wird.
- Der DFS-Algorithmus führt eine Tiefensuche durch und gelangt manchmal in die Endlosschleife.
Beispiel:
Im folgenden Suchbaum haben wir den Ablauf der Tiefensuche dargestellt. Die Reihenfolge ist wie folgt:
Wurzelknoten ---> Linker Knoten ----> rechter Knoten.
Die Suche beginnt am Wurzelknoten S und durchläuft A, dann B, dann D und E. Nach dem Durchqueren von E wird der Baum zurückverfolgt, da E keinen anderen Nachfolger hat und der Zielknoten immer noch nicht gefunden wird. Nach dem Zurückverfolgen durchquert es Knoten C und dann G und endet hier, da es den Zielknoten gefunden hat.

Vollständigkeit: Der DFS-Suchalgorithmus ist im endlichen Zustandsraum vollständig, da er jeden Knoten innerhalb eines begrenzten Suchbaums erweitert.
Zeitkomplexität: Die zeitliche Komplexität von DFS entspricht dem vom Algorithmus durchlaufenen Knoten. Es ist gegeben durch:
T(n)= 1+ n2+ n3+.........+ nM=O(nM)
Wobei m = maximale Tiefe eines beliebigen Knotens und diese kann viel größer als d (flachste Lösungstiefe) sein.
Raumkomplexität: Der DFS-Algorithmus muss nur einen einzelnen Pfad vom Wurzelknoten speichern, daher entspricht die Platzkomplexität von DFS der Größe des Randsatzes Um .
Optimal: Der DFS-Suchalgorithmus ist nicht optimal, da er eine große Anzahl von Schritten oder hohe Kosten für das Erreichen des Zielknotens generieren kann.
3. Tiefenbegrenzter Suchalgorithmus:
Ein tiefenbegrenzter Suchalgorithmus ähnelt der Tiefensuche mit einer vorgegebenen Grenze. Die tiefenbeschränkte Suche kann den Nachteil des unendlichen Pfads bei der Tiefensuche lösen. In diesem Algorithmus wird der Knoten an der Tiefengrenze so behandelt, als hätte er keine weiteren Nachfolgeknoten mehr.
Die tiefenbegrenzte Suche kann mit zwei Fehlerbedingungen beendet werden:
- Standardfehlerwert: Zeigt an, dass es für das Problem keine Lösung gibt.
- Cutoff-Fehlerwert: Er definiert keine Lösung für das Problem innerhalb einer bestimmten Tiefengrenze.
Vorteile:
Die tiefenbeschränkte Suche ist speichereffizient.
Java-equals-Methode
Nachteile:
- Die auf die Tiefe beschränkte Suche hat auch den Nachteil, dass sie unvollständig ist.
- Es ist möglicherweise nicht optimal, wenn das Problem mehr als eine Lösung hat.
Beispiel:

Vollständigkeit: Der DLS-Suchalgorithmus ist abgeschlossen, wenn die Lösung über der Tiefengrenze liegt.
Zeitkomplexität: Die zeitliche Komplexität des DLS-Algorithmus beträgt O(gebℓ) .
Raumkomplexität: Die räumliche Komplexität des DLS-Algorithmus beträgt O (b�ℓ) .
Optimal: Die tiefenbeschränkte Suche kann als Sonderfall von DFS angesehen werden und ist auch dann nicht optimal, wenn ℓ>d.
4. Algorithmus zur Suche nach einheitlichen Kosten:
Die Suche nach einheitlichen Kosten ist ein Suchalgorithmus, der zum Durchlaufen eines gewichteten Baums oder Diagramms verwendet wird. Dieser Algorithmus kommt ins Spiel, wenn für jede Kante unterschiedliche Kosten verfügbar sind. Das Hauptziel der Suche nach einheitlichen Kosten besteht darin, einen Pfad zum Zielknoten zu finden, der die niedrigsten kumulierten Kosten aufweist. Bei der Suche nach einheitlichen Kosten werden Knoten entsprechend ihren Pfadkosten vom Wurzelknoten aus erweitert. Es kann verwendet werden, um jeden Graphen/Baum zu lösen, bei dem die optimalen Kosten gefragt sind. Ein Suchalgorithmus mit einheitlichen Kosten wird von der Prioritätswarteschlange implementiert. Den niedrigsten kumulierten Kosten wird höchste Priorität eingeräumt. Die Suche nach einheitlichen Kosten entspricht dem BFS-Algorithmus, wenn die Pfadkosten aller Kanten gleich sind.
Vorteile:
- Die einheitliche Kostensuche ist optimal, da in jedem Zustand der Weg mit den geringsten Kosten gewählt wird.
Nachteile:
- Dabei kommt es nicht auf die Anzahl der Suchschritte an, sondern nur auf die Pfadkosten. Aus diesem Grund kann dieser Algorithmus in einer Endlosschleife stecken bleiben.
Beispiel:

Vollständigkeit:
Array im String
Die Suche nach einheitlichen Kosten ist abgeschlossen. Wenn es beispielsweise eine Lösung gibt, wird UCS sie finden.
Zeitkomplexität:
Sei C* sind die Kosten der optimalen Lösung , Und e ist jeder Schritt, um dem Zielknoten näher zu kommen. Dann beträgt die Anzahl der Schritte = C*/ε+1. Hier haben wir +1 genommen, da wir bei Zustand 0 beginnen und bei C*/ε enden.
Daher beträgt die Zeitkomplexität im ungünstigsten Fall der Suche nach einheitlichen Kosten O(geb1 + [C*/e])/ .
Raumkomplexität:
Die gleiche Logik gilt für die Raumkomplexität, sodass die Raumkomplexität im schlimmsten Fall der Suche nach einheitlichen Kosten beträgt O(geb1 + [C*/e]) .
Optimal:
Die Suche nach einheitlichen Kosten ist immer optimal, da sie nur einen Pfad mit den niedrigsten Pfadkosten auswählt.
5. Iterative VertiefungTiefensuche:
Der iterative Vertiefungsalgorithmus ist eine Kombination aus DFS- und BFS-Algorithmen. Dieser Suchalgorithmus ermittelt die beste Tiefengrenze und erhöht die Grenze schrittweise, bis ein Ziel gefunden ist.
Dieser Algorithmus führt eine Tiefensuche bis zu einer bestimmten „Tiefengrenze“ durch und erhöht die Tiefengrenze nach jeder Iteration weiter, bis der Zielknoten gefunden ist.
Dieser Suchalgorithmus kombiniert die Vorteile der schnellen Suche der Breitensuche und der Speichereffizienz der Tiefensuche.
Der iterative Suchalgorithmus ist eine nützliche uninformierte Suche, wenn der Suchraum groß ist und die Tiefe des Zielknotens unbekannt ist.
Vorteile:
Verzeichnis Linux umbenennen
- Es kombiniert die Vorteile des BFS- und des DFS-Suchalgorithmus im Hinblick auf schnelle Suche und Speichereffizienz.
Nachteile:
- Der Hauptnachteil von IDDFS besteht darin, dass die gesamte Arbeit der vorherigen Phase wiederholt wird.
Beispiel:
Die folgende Baumstruktur zeigt die iterative vertiefende Tiefensuche. Der IDDFS-Algorithmus führt verschiedene Iterationen durch, bis er den Zielknoten nicht mehr findet. Die vom Algorithmus durchgeführte Iteration wird wie folgt angegeben:

1. Iteration -----> A
2. Iteration ----> A, B, C
3. Iteration------>A, B, D, E, C, F, G
4. Iteration------>A, B, D, H, I, E, C, F, K, G
In der vierten Iteration findet der Algorithmus den Zielknoten.
Vollständigkeit:
Dieser Algorithmus ist vollständig, wenn der Verzweigungsfaktor endlich ist.
Zeitkomplexität:
Nehmen wir an, b ist der Verzweigungsfaktor und die Tiefe ist d, dann ist die Zeitkomplexität im ungünstigsten Fall O(gebD) .
Raumkomplexität:
Die räumliche Komplexität von IDDFS wird sein O(bd) .
char zu int Java
Optimal:
Der IDDFS-Algorithmus ist optimal, wenn die Pfadkosten eine nicht abnehmende Funktion der Knotentiefe sind.
6. Bidirektionaler Suchalgorithmus:
Der bidirektionale Suchalgorithmus führt zwei gleichzeitige Suchvorgänge durch, einen vom Anfangszustand aus, der als Vorwärtssuche bezeichnet wird, und einen anderen vom Zielknoten aus, der als Rückwärtssuche bezeichnet wird, um den Zielknoten zu finden. Die bidirektionale Suche ersetzt einen einzelnen Suchgraphen durch zwei kleine Untergraphen, in denen einer die Suche an einem Anfangsscheitelpunkt und der andere am Zielscheitelpunkt beginnt. Die Suche stoppt, wenn diese beiden Diagramme einander schneiden.
Bei der bidirektionalen Suche können Suchtechniken wie BFS, DFS, DLS usw. verwendet werden.
Vorteile:
- Die bidirektionale Suche ist schnell.
- Die bidirektionale Suche benötigt weniger Speicher
Nachteile:
- Die Implementierung des bidirektionalen Suchbaums ist schwierig.
Beispiel:
Im folgenden Suchbaum wird ein bidirektionaler Suchalgorithmus angewendet. Dieser Algorithmus unterteilt einen Graphen/Baum in zwei Untergraphen. Die Durchquerung beginnt am Knoten 1 in Vorwärtsrichtung und beginnt am Zielknoten 16 in Rückwärtsrichtung.
Der Algorithmus endet am Knoten 9, wo sich zwei Suchvorgänge treffen.

Vollständigkeit: Die bidirektionale Suche ist abgeschlossen, wenn wir in beiden Suchvorgängen BFS verwenden.
Zeitkomplexität: Die zeitliche Komplexität der bidirektionalen Suche mit BFS beträgt O(gebD) .
Raumkomplexität: Die räumliche Komplexität der bidirektionalen Suche beträgt O(gebD) .
Optimal: Die bidirektionale Suche ist optimal.