Neuronale Netze sind Rechenmodelle, die die komplexen Funktionen des menschlichen Gehirns nachahmen. Die neuronalen Netze bestehen aus miteinander verbundenen Knoten oder Neuronen, die Daten verarbeiten und daraus lernen und so Aufgaben wie Mustererkennung und Entscheidungsfindung beim maschinellen Lernen ermöglichen. Der Artikel erkundet mehr über neuronale Netze, ihre Funktionsweise, Architektur und mehr.
Inhaltsverzeichnis
- Entwicklung neuronaler Netze
- Was sind neuronale Netze?
- Wie funktionieren neuronale Netze?
- Lernen eines neuronalen Netzwerks
- Arten neuronaler Netze
- Einfache Implementierung eines neuronalen Netzwerks
Entwicklung neuronaler Netze
Seit den 1940er Jahren gab es eine Reihe bemerkenswerter Fortschritte auf dem Gebiet der neuronalen Netze:
- 1940er-1950er: Frühe Konzepte
Neuronale Netze begannen mit der Einführung des ersten mathematischen Modells künstlicher Neuronen durch McCulloch und Pitts. Aber rechnerische Einschränkungen erschwerten den Fortschritt.
- 1960er-1970er: Perzeptrone
Diese Ära wird durch die Arbeit von Rosenblatt über Perzeptrone definiert. Perzeptrone sind einschichtige Netzwerke, deren Anwendbarkeit auf Probleme beschränkt war, die linear separat gelöst werden konnten.
- 1980er Jahre: Backpropagation und Konnektionismus
Mehrschichtiges Netzwerk Das Training wurde durch die Erfindung der Backpropagation-Methode durch Rumelhart, Hinton und Williams ermöglicht. Mit seiner Betonung des Lernens durch miteinander verbundene Knoten gewann der Konnektionismus an Attraktivität.
- 1990er Jahre: Boom und Winter
Mit Anwendungen in der Bilderkennung, im Finanzwesen und in anderen Bereichen erlebten neuronale Netze einen Boom. Allerdings erlebte die Forschung zu neuronalen Netzen aufgrund exorbitanter Rechenkosten und überzogener Erwartungen einen Winter.
- 2000er: Wiederaufleben und Deep Learning
Größere Datensätze, innovative Strukturen und verbesserte Verarbeitungsmöglichkeiten führten zu einem Comeback. Tiefes Lernen hat in einer Reihe von Disziplinen durch die Verwendung zahlreicher Schichten eine erstaunliche Wirksamkeit gezeigt.
- 2010er Jahre bis heute: Dominanz des Deep Learning
Convolutional Neural Networks (CNNs) und Recurrent Neural Networks (RNNs), zwei Deep-Learning-Architekturen, dominierten das maschinelle Lernen. Ihre Leistungsfähigkeit wurde durch Innovationen in den Bereichen Spiele, Bilderkennung und Verarbeitung natürlicher Sprache unter Beweis gestellt.
Was sind neuronale Netze?
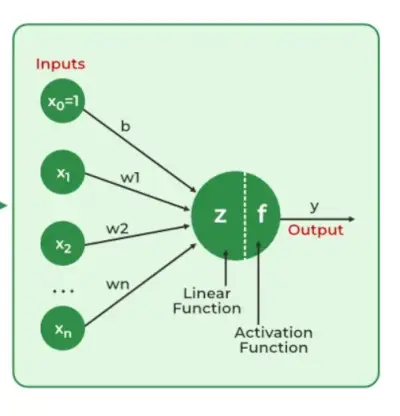
Neuronale Netze Extrahieren Sie identifizierende Merkmale aus Daten, ohne dass ein vorprogrammiertes Verständnis vorliegt. Zu den Netzwerkkomponenten gehören Neuronen, Verbindungen, Gewichte, Bias, Ausbreitungsfunktionen und eine Lernregel. Neuronen empfangen Eingaben, die durch Schwellenwerte und Aktivierungsfunktionen gesteuert werden. Verbindungen beinhalten Gewichtungen und Vorurteile, die die Informationsübertragung regulieren. Das Lernen, das Anpassen von Gewichtungen und Voreingenommenheiten, erfolgt in drei Phasen: Eingabeberechnung, Ausgabegenerierung und iterative Verfeinerung, wodurch die Kompetenz des Netzwerks bei verschiedenen Aufgaben verbessert wird.
Diese beinhalten:
- Das neuronale Netzwerk wird durch eine neue Umgebung simuliert.
- Durch diese Simulation werden dann die freien Parameter des neuronalen Netzes verändert.
- Das neuronale Netzwerk reagiert dann aufgrund der Änderungen seiner freien Parameter auf neue Weise auf die Umgebung.
Bedeutung neuronaler Netze
Die Fähigkeit neuronaler Netze, Muster zu erkennen, komplizierte Rätsel zu lösen und sich an veränderte Umgebungen anzupassen, ist von entscheidender Bedeutung. Ihre Fähigkeit, aus Daten zu lernen, hat weitreichende Auswirkungen und reicht von der Revolutionierung von Technologien wie Verarbeitung natürlicher Sprache und selbstfahrende Autos bis hin zur Automatisierung von Entscheidungsprozessen und der Steigerung der Effizienz in zahlreichen Branchen. Die Entwicklung künstlicher Intelligenz hängt maßgeblich von neuronalen Netzen ab, die auch Innovationen vorantreiben und die Richtung der Technologie beeinflussen.
wie viele null für eine million
Wie funktionieren neuronale Netze?
Lassen Sie uns anhand eines Beispiels verstehen, wie ein neuronales Netzwerk funktioniert:
Betrachten Sie ein neuronales Netzwerk zur E-Mail-Klassifizierung. Die Eingabeschicht übernimmt Funktionen wie E-Mail-Inhalt, Absenderinformationen und Betreff. Diese Eingaben, multipliziert mit angepassten Gewichtungen, durchlaufen verborgene Schichten. Durch Training lernt das Netzwerk, Muster zu erkennen, die anzeigen, ob es sich bei einer E-Mail um Spam handelt oder nicht. Die Ausgabeschicht sagt mit einer binären Aktivierungsfunktion voraus, ob es sich bei der E-Mail um Spam handelt (1) oder nicht (0). Da das Netzwerk seine Gewichtungen durch Backpropagation iterativ verfeinert, wird es in der Lage, zwischen Spam und legitimen E-Mails zu unterscheiden, was die Praktikabilität neuronaler Netzwerke in realen Anwendungen wie der E-Mail-Filterung demonstriert.
Funktionsweise eines neuronalen Netzwerks
Neuronale Netze sind komplexe Systeme, die einige Merkmale der Funktionsweise des menschlichen Gehirns nachahmen. Es besteht aus einer Eingabeschicht, einer oder mehreren verborgenen Schichten und einer Ausgabeschicht, die aus Schichten gekoppelter künstlicher Neuronen besteht. Die beiden Phasen des Grundprozesses werden Backpropagation und Backpropagation genannt Vorwärtsausbreitung .
Vorwärtsausbreitung
- Eingabeebene: Jedes Feature in der Eingabeschicht wird durch einen Knoten im Netzwerk dargestellt, der Eingabedaten empfängt.
- Gewichte und Anschlüsse: Das Gewicht jeder neuronalen Verbindung gibt an, wie stark die Verbindung ist. Im Laufe des Trainings werden diese Gewichte verändert.
- Versteckte Ebenen: Jedes Neuron der verborgenen Schicht verarbeitet Eingaben, indem es sie mit Gewichten multipliziert, addiert und sie dann durch eine Aktivierungsfunktion leitet. Dadurch wird Nichtlinearität eingeführt, die es dem Netzwerk ermöglicht, komplizierte Muster zu erkennen.
- Ausgabe: Das Endergebnis entsteht durch Wiederholen des Vorgangs, bis die Ausgabeschicht erreicht ist.
Backpropagation
- Verlustberechnung: Die Ausgabe des Netzwerks wird mit den tatsächlichen Zielwerten verglichen und eine Verlustfunktion wird verwendet, um die Differenz zu berechnen. Für ein Regressionsproblem ist das Mittlere quadratische Fehler (MSE) wird üblicherweise als Kostenfunktion verwendet.
Verlustfunktion:
- Gradientenabstieg: Anschließend nutzt das Netzwerk den Gradientenabstieg, um den Verlust zu reduzieren. Um die Ungenauigkeit zu verringern, werden die Gewichte basierend auf der Ableitung des Verlusts in Bezug auf jedes Gewicht geändert.
- Gewichte anpassen: Die Gewichte werden bei jeder Verbindung durch Anwendung dieses iterativen Prozesses angepasst, oder Rückausbreitung , rückwärts über das Netzwerk.
- Ausbildung: Während des Trainings mit verschiedenen Datenproben wird der gesamte Prozess der Vorwärtsausbreitung, Verlustberechnung und Rückausbreitung iterativ durchgeführt, sodass das Netzwerk sich anpassen und Muster aus den Daten lernen kann.
- Aktivierungsfunktionen: Die Nichtlinearität des Modells wird durch Aktivierungsfunktionen wie die eingeführt gleichgerichtete Lineareinheit (ReLU) Std Sigmoid . Ihre Entscheidung, ob ein Neuron ausgelöst wird, basiert auf der gesamten gewichteten Eingabe.

Lernen eines neuronalen Netzwerks
1. Lernen mit überwachtem Lernen
In überwachtes Lernen Das neuronale Netzwerk wird von einem Lehrer geleitet, der Zugriff auf beide Eingabe-Ausgabe-Paare hat. Das Netzwerk erstellt Ausgaben basierend auf Eingaben, ohne die Umgebung zu berücksichtigen. Durch den Vergleich dieser Ausgaben mit den vom Lehrer bekannten gewünschten Ausgaben wird ein Fehlersignal generiert. Um Fehler zu reduzieren, werden die Parameter des Netzwerks iterativ geändert und gestoppt, wenn die Leistung ein akzeptables Niveau erreicht.
list.sort Java
2. Lernen mit unbeaufsichtigtem Lernen
Äquivalente Ausgabevariablen fehlen in unbeaufsichtigtes Lernen . Sein Hauptziel besteht darin, die zugrunde liegende Struktur der eingehenden Daten (X) zu verstehen. Es ist kein Lehrer anwesend, der Ratschläge gibt. Stattdessen ist die Modellierung von Datenmustern und Beziehungen das angestrebte Ergebnis. Wörter wie Regression und Klassifizierung beziehen sich auf überwachtes Lernen, während unüberwachtes Lernen mit Clustering und Assoziation verbunden ist.
3. Lernen mit Reinforcement Learning
Durch Interaktion mit der Umwelt und Feedback in Form von Belohnungen oder Strafen gewinnt das Netzwerk Wissen. Das Ziel des Netzwerks besteht darin, eine Richtlinie oder Strategie zu finden, die die kumulativen Belohnungen im Laufe der Zeit optimiert. Diese Art wird häufig in Spiele- und Entscheidungsanwendungen eingesetzt.
Arten neuronaler Netze
Es gibt Sieben Arten von neuronalen Netzen, die verwendet werden können.
- Feedforward-Netzwerke: A Feedforward-Neuronales Netzwerk ist eine einfache Architektur eines künstlichen neuronalen Netzwerks, bei der sich Daten in einer einzigen Richtung von der Eingabe zur Ausgabe bewegen. Es verfügt über Eingabe-, versteckte und Ausgabeebenen. Rückkopplungsschleifen fehlen. Aufgrund seiner unkomplizierten Architektur eignet es sich für eine Reihe von Anwendungen, beispielsweise für Regression und Mustererkennung.
- Mehrschichtiges Perzeptron (MLP): MLP ist eine Art Feedforward-Neuronales Netzwerk mit drei oder mehr Schichten, einschließlich einer Eingabeschicht, einer oder mehreren verborgenen Schichten und einer Ausgabeschicht. Es verwendet nichtlineare Aktivierungsfunktionen.
- Faltungs-Neuronales Netzwerk (CNN): A Faltungs-Neuronales Netzwerk (CNN) ist ein spezialisiertes künstliches neuronales Netzwerk zur Bildverarbeitung. Es verwendet Faltungsschichten, um automatisch hierarchische Merkmale aus Eingabebildern zu lernen und so eine effektive Bilderkennung und -klassifizierung zu ermöglichen. CNNs haben das Computersehen revolutioniert und sind von zentraler Bedeutung für Aufgaben wie Objekterkennung und Bildanalyse.
- Wiederkehrendes neuronales Netzwerk (RNN): Ein künstlicher neuronaler Netzwerktyp, der für die sequentielle Datenverarbeitung vorgesehen ist, wird als a bezeichnet Wiederkehrendes neuronales Netzwerk (RNN). Es eignet sich für Anwendungen, bei denen kontextabhängige Abhängigkeiten von entscheidender Bedeutung sind, wie z. B. die Vorhersage von Zeitreihen und die Verarbeitung natürlicher Sprache, da es Rückkopplungsschleifen nutzt, die es Informationen ermöglichen, innerhalb des Netzwerks zu überleben.
- Langes Kurzzeitgedächtnis (LSTM): LSTM ist ein RNN-Typ, der das Problem des verschwindenden Gradienten beim Training von RNNs überwinden soll. Es verwendet Speicherzellen und Gates, um Informationen selektiv zu lesen, zu schreiben und zu löschen.
Einfache Implementierung eines neuronalen Netzwerks
Python3
import> numpy as np> # array of any amount of numbers. n = m> X>=> np.array([[>1>,>2>,>3>],> >[>3>,>4>,>1>],> >[>2>,>5>,>3>]])> # multiplication> y>=> np.array([[.>5>, .>3>, .>2>]])> # transpose of y> y>=> y.T> # sigma value> sigm>=> 2> # find the delta> delt>=> np.random.random((>3>,>3>))>-> 1> for> j>in> range>(>100>):> > ># find matrix 1. 100 layers.> >m1>=> (y>-> (>1>/>(>1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt))))))>*>((>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))>*>(>1>->(>1>/>(> >1> +> np.exp(>->(np.dot((>1>/>(>1> +> np.exp(> >->(np.dot(X, sigm))))), delt)))))))> ># find matrix 2> >m2>=> m1.dot(delt.T)>*> ((>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> >*> (>1>->(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))))> ># find delta> >delt>=> delt>+> (>1>/>(>1> +> np.exp(>->(np.dot(X, sigm))))).T.dot(m1)> ># find sigma> >sigm>=> sigm>+> (X.T.dot(m2))> # print output from the matrix> print>(>1>/>(>1> +> np.exp(>->(np.dot(X, sigm)))))> |
>
>
Ausgabe:
[[0.99999325 0.99999375 0.99999352] [0.99999988 0.99999989 0.99999988] [1. 1. 1. ]]>
Vorteile neuronaler Netze
Aufgrund ihrer zahlreichen Vorteile werden neuronale Netze in vielen verschiedenen Anwendungen eingesetzt:
- Anpassungsfähigkeit: Neuronale Netze sind für Aktivitäten nützlich, bei denen die Verbindung zwischen Eingaben und Ausgaben komplex oder nicht genau definiert ist, da sie sich an neue Situationen anpassen und aus Daten lernen können.
- Mustererkennung: Ihre Kenntnisse in der Mustererkennung machen sie bei Aufgaben wie der Audio- und Bilderkennung, der Verarbeitung natürlicher Sprache und anderen komplexen Datenmustern effizient.
- Parallelverarbeitung: Da neuronale Netze von Natur aus zur Parallelverarbeitung fähig sind, können sie zahlreiche Aufgaben gleichzeitig verarbeiten, was die Berechnungen beschleunigt und effizienter macht.
- Nichtlinearität: Neuronale Netze sind aufgrund der nichtlinearen Aktivierungsfunktionen in Neuronen in der Lage, komplizierte Zusammenhänge in Daten zu modellieren und zu verstehen, wodurch die Nachteile linearer Modelle überwunden werden.
Nachteile neuronaler Netze
Neuronale Netze sind zwar leistungsstark, aber nicht ohne Nachteile und Schwierigkeiten:
- Rechenintensität: Das Training großer neuronaler Netze kann ein mühsamer und rechenintensiver Prozess sein, der viel Rechenleistung erfordert.
- Blackbox Natur: Als Black-Box-Modelle stellen neuronale Netze in wichtigen Anwendungen ein Problem dar, da es schwierig ist, zu verstehen, wie sie Entscheidungen treffen.
- Überanpassung: Überanpassung ist ein Phänomen, bei dem neuronale Netze Trainingsmaterial im Gedächtnis speichern, anstatt Muster in den Daten zu identifizieren. Obwohl Regularisierungsansätze Abhilfe schaffen, besteht das Problem weiterhin.
- Bedarf an großen Datensätzen: Für ein effizientes Training benötigen neuronale Netze häufig umfangreiche, gekennzeichnete Datensätze; andernfalls kann ihre Leistung durch unvollständige oder verzerrte Daten beeinträchtigt werden.
Häufig gestellte Fragen (FAQs)
1. Was ist ein neuronales Netzwerk?
Ein neuronales Netzwerk ist ein künstliches System aus miteinander verbundenen Knoten (Neuronen), die Informationen verarbeiten und der Struktur des menschlichen Gehirns nachempfunden sind. Es wird in maschinellen Lernaufgaben eingesetzt, bei denen Muster aus Daten extrahiert werden.
2. Wie funktioniert ein neuronales Netzwerk?
Schichten verbundener Neuronen verarbeiten Daten in neuronalen Netzen. Das Netzwerk verarbeitet Eingabedaten, ändert Gewichte während des Trainings und erzeugt abhängig von den erkannten Mustern eine Ausgabe.
3. Was sind die häufigsten Arten neuronaler Netzwerkarchitekturen?
Feedforward-Neuronale Netze, Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs) und Long Short-Term Memory Networks (LSTMs) sind Beispiele für gängige Architekturen, die jeweils für eine bestimmte Aufgabe konzipiert sind.
4. Was ist der Unterschied zwischen überwachtem und unüberwachtem Lernen in neuronalen Netzen?
Beim überwachten Lernen werden gekennzeichnete Daten verwendet, um ein neuronales Netzwerk zu trainieren, damit es lernen kann, Eingaben passenden Ausgaben zuzuordnen. Unüberwachtes Lernen arbeitet mit unbeschrifteten Daten und sucht nach Strukturen oder Mustern in den Daten .
5. Wie gehen neuronale Netze mit sequentiellen Daten um?
Die Rückkopplungsschleifen, die rekurrente neuronale Netze (RNNs) beinhalten, ermöglichen es ihnen, sequentielle Daten zu verarbeiten und im Laufe der Zeit Abhängigkeiten und Kontext zu erfassen.