BERT, ein Akronym für bidirektionale Encoderdarstellungen von Transformatoren , steht als Open Source Framework für maschinelles Lernen entworfen für den Bereich von Verarbeitung natürlicher Sprache (NLP) . Dieses im Jahr 2018 entstandene Framework wurde von Forschern von Google AI Language entwickelt. Der Artikel zielt darauf ab, das zu untersuchen Architektur, Funktionsweise und Anwendungen von BERT .
Was ist BERT?
BERT (Bidirektionale Encoder-Darstellungen von Transformatoren) nutzt ein transformatorbasiertes neuronales Netzwerk, um menschenähnliche Sprache zu verstehen und zu erzeugen. BERT verwendet eine Nur-Encoder-Architektur. Im Original Transformatorarchitektur gibt es sowohl Encoder- als auch Decodermodule. Die Entscheidung, in BERT eine reine Encoder-Architektur zu verwenden, legt nahe, dass der Schwerpunkt eher auf dem Verständnis von Eingabesequenzen als auf der Generierung von Ausgabesequenzen liegt.
Bidirektionaler Ansatz von BERT
Traditionelle Sprachmodelle verarbeiten Text sequentiell, entweder von links nach rechts oder von rechts nach links. Diese Methode beschränkt die Wahrnehmung des Modells auf den unmittelbaren Kontext vor dem Zielwort. BERT verwendet einen bidirektionalen Ansatz, der sowohl den linken als auch den rechten Kontext von Wörtern in einem Satz berücksichtigt. Anstatt den Text nacheinander zu analysieren, betrachtet BERT alle Wörter in einem Satz gleichzeitig.
Beispiel: Das Ufer liegt am _______ des Flusses.
In einem unidirektionalen Modell würde das Verständnis des Leerzeichens stark von den vorangehenden Wörtern abhängen, und das Modell könnte Schwierigkeiten haben zu erkennen, ob sich „bank“ auf ein Finanzinstitut oder auf die Seite des Flusses bezieht.
Da BERT bidirektional ist, berücksichtigt es gleichzeitig sowohl den linken (das Ufer liegt am) als auch den rechten Kontext (des Flusses) und ermöglicht so ein differenzierteres Verständnis. Es geht davon aus, dass das fehlende Wort wahrscheinlich mit dem geografischen Standort der Bank zusammenhängt, was den kontextuellen Reichtum verdeutlicht, den der bidirektionale Ansatz mit sich bringt.
Vorschulung und Feinabstimmung
Das BERT-Modell durchläuft einen zweistufigen Prozess:
- Vorbereitendes Training für große Mengen unbeschrifteten Textes zum Erlernen kontextbezogener Einbettungen.
- Feinabstimmung der gekennzeichneten Daten für bestimmte Zwecke NLP Aufgaben.
Vorschulung zu Big Data
- BERT ist für große Mengen unbeschrifteter Textdaten vorab trainiert. Das Modell lernt kontextuelle Einbettungen, das sind die Darstellungen von Wörtern, die ihren umgebenden Kontext in einem Satz berücksichtigen.
- BERT übernimmt verschiedene unbeaufsichtigte Vorbereitungsaufgaben. Beispielsweise könnte es lernen, fehlende Wörter in einem Satz vorherzusagen (Masked Language Model oder MLM-Aufgabe), die Beziehung zwischen zwei Sätzen zu verstehen oder den nächsten Satz in einem Paar vorherzusagen.
Feinabstimmung beschrifteter Daten
- Nach der Vortrainingsphase wird das BERT-Modell mit seinen kontextuellen Einbettungen dann für bestimmte Aufgaben der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) verfeinert. Dieser Schritt passt das Modell an gezieltere Anwendungen an, indem sein allgemeines Sprachverständnis an die Nuancen der jeweiligen Aufgabe angepasst wird.
- Die Feinabstimmung von BERT erfolgt anhand gekennzeichneter Daten, die spezifisch für die nachgelagerten Aufgaben von Interesse sind. Zu diesen Aufgaben könnten Stimmungsanalyse, Beantwortung von Fragen, Erkennung benannter Entitäten oder jede andere NLP-Anwendung. Die Parameter des Modells werden angepasst, um seine Leistung an die jeweiligen Anforderungen der jeweiligen Aufgabe zu optimieren.
Die einheitliche Architektur von BERT ermöglicht die Anpassung an verschiedene nachgelagerte Aufgaben mit minimalen Änderungen, was es zu einem vielseitigen und hochwirksamen Werkzeug macht Verständnis natürlicher Sprache und Verarbeitung.
Wie funktioniert BERT?
BERT ist für die Generierung eines Sprachmodells konzipiert, sodass nur der Encodermechanismus verwendet wird. Eine Folge von Token wird dem Transformer-Encoder zugeführt. Diese Token werden zunächst in Vektoren eingebettet und dann im neuronalen Netzwerk verarbeitet. Die Ausgabe ist eine Folge von Vektoren, die jeweils einem Eingabe-Token entsprechen und kontextualisierte Darstellungen bereitstellen.
Beim Training von Sprachmodellen ist die Definition eines Vorhersageziels eine Herausforderung. Viele Modelle sagen das nächste Wort in einer Sequenz voraus. Dies ist ein direktionaler Ansatz und kann das Kontextlernen einschränken. BERT begegnet dieser Herausforderung mit zwei innovativen Trainingsstrategien:
- Maskiertes Sprachmodell (MLM)
- Vorhersage des nächsten Satzes (NSP)
1. Maskiertes Sprachmodell (MLM)
Im Vortrainingsprozess von BERT wird ein Teil der Wörter in jeder Eingabesequenz maskiert und das Modell wird darauf trainiert, die ursprünglichen Werte dieser maskierten Wörter basierend auf dem durch die umgebenden Wörter bereitgestellten Kontext vorherzusagen.
In einfachen Worten,
- Maskierungswörter: Bevor BERT aus Sätzen lernt, verbirgt es einige Wörter (ca. 15 %) und ersetzt sie durch ein spezielles Symbol wie [MASK].
- Versteckte Wörter erraten: Die Aufgabe von BERT besteht darin, herauszufinden, was diese verborgenen Wörter sind, indem es die Wörter um sie herum betrachtet. Es ist wie ein Ratespiel, bei dem einige Wörter fehlen und BERT versucht, die Lücken zu füllen.
- So lernt BERT:
- BERT fügt seinem Lernsystem eine spezielle Ebene hinzu, um diese Vermutungen anzustellen. Anschließend prüft es, wie nah seine Vermutungen an den tatsächlich versteckten Wörtern liegen.
- Dies geschieht, indem es seine Vermutungen in Wahrscheinlichkeiten umwandelt und sagt: „Ich denke, dieses Wort ist X, und ich bin mir da so sicher.“
- Besondere Aufmerksamkeit für versteckte Wörter
- Das Hauptaugenmerk von BERT während des Trainings liegt darauf, diese versteckten Wörter richtig zu machen. Es geht ihm weniger darum, die Wörter vorherzusagen, die nicht verborgen sind.
- Denn die eigentliche Herausforderung besteht darin, die fehlenden Teile herauszufinden, und diese Strategie hilft BERT dabei, die Bedeutung und den Kontext von Wörtern wirklich gut zu verstehen.
In technischer Hinsicht,
- BERT fügt der Ausgabe des Encoders eine Klassifizierungsebene hinzu. Diese Ebene ist entscheidend für die Vorhersage der maskierten Wörter.
- Die Ausgabevektoren der Klassifizierungsschicht werden mit der Einbettungsmatrix multipliziert und so in die Vokabulardimension umgewandelt. Dieser Schritt hilft dabei, die vorhergesagten Darstellungen an den Vokabularraum anzupassen.
- Die Wahrscheinlichkeit jedes Wortes im Vokabular wird anhand des berechnet SoftMax-Aktivierungsfunktion . Dieser Schritt generiert für jede maskierte Position eine Wahrscheinlichkeitsverteilung über das gesamte Vokabular.
- Die während des Trainings verwendete Verlustfunktion berücksichtigt nur die Vorhersage der maskierten Werte. Das Modell wird für die Abweichung zwischen seinen Vorhersagen und den tatsächlichen Werten der maskierten Wörter bestraft.
- Das Modell konvergiert langsamer als Richtungsmodelle. Dies liegt daran, dass sich BERT während des Trainings nur mit der Vorhersage der maskierten Werte befasst und die Vorhersage der nicht maskierten Wörter ignoriert. Das durch diese Strategie erreichte erhöhte Kontextbewusstsein gleicht die langsamere Konvergenz aus.
2. Vorhersage des nächsten Satzes (NSP)
BERT sagt voraus, ob der zweite Satz mit dem ersten verbunden ist. Dazu wird die Ausgabe des [CLS]-Tokens mithilfe einer Klassifizierungsschicht in einen 2×1-förmigen Vektor umgewandelt und anschließend mithilfe von SoftMax die Wahrscheinlichkeit berechnet, ob der zweite Satz auf den ersten folgt.
- Im Trainingsprozess lernt BERT, die Beziehung zwischen Satzpaaren zu verstehen und vorherzusagen, ob der zweite Satz im Originaldokument auf den ersten folgt.
- 50 % der Eingabepaare haben den zweiten Satz als Folgesatz im Originaldokument und die anderen 50 % haben einen zufällig ausgewählten Satz.
- Um dem Modell zu helfen, zwischen verbundenen und getrennten Satzpaaren zu unterscheiden. Die Eingabe wird vor der Eingabe in das Modell verarbeitet:
- Am Anfang des ersten Satzes wird ein [CLS]-Token eingefügt, und am Ende jedes Satzes wird ein [SEP]-Token hinzugefügt.
- Jedem Token wird eine Satzeinbettung hinzugefügt, die Satz A oder Satz B angibt.
- Eine Positionseinbettung gibt die Position jedes Tokens in der Sequenz an.
- BERT sagt voraus, ob der zweite Satz mit dem ersten verbunden ist. Dazu wird die Ausgabe des [CLS]-Tokens mithilfe einer Klassifizierungsschicht in einen 2×1-förmigen Vektor umgewandelt und anschließend mithilfe von SoftMax die Wahrscheinlichkeit berechnet, ob der zweite Satz auf den ersten folgt.
Während des Trainings des BERT-Modells werden Masked LM und Next Sentence Prediction gemeinsam trainiert. Das Modell zielt darauf ab, die kombinierte Verlustfunktion von Masked LM und Next Sentence Prediction zu minimieren, was zu einem robusten Sprachmodell mit verbesserten Fähigkeiten zum Verständnis des Kontexts innerhalb von Sätzen und der Beziehungen zwischen Sätzen führt.
Warum sollten Masked LM und Next Sentence Prediction gemeinsam trainiert werden?
Masked LM hilft BERT, den Kontext innerhalb eines Satzes zu verstehen und Vorhersage des nächsten Satzes hilft BERT, den Zusammenhang oder die Beziehung zwischen Satzpaaren zu verstehen. Das gemeinsame Training beider Strategien stellt daher sicher, dass BERT ein breites und umfassendes Verständnis der Sprache erlernt und sowohl Details innerhalb von Sätzen als auch den Fluss zwischen Sätzen erfasst.
BERT-Architekturen
Die Architektur von BERT ist ein mehrschichtiger bidirektionaler Transformator-Encoder, der dem Transformatormodell ziemlich ähnlich ist. Eine Transformatorarchitektur ist ein Encoder-Decoder-Netzwerk, das verwendet Selbstaufmerksamkeit auf der Encoderseite und Aufmerksamkeit auf der Decoderseite.
- BERTBASEhat 1 2 Schichten im Encoder-Stack während BERTGROSShat 24 Schichten im Encoder-Stack . Dies sind mehr als die im Originalpapier beschriebene Transformer-Architektur ( 6 Encoderschichten ).
- BERT-Architekturen (BASE und LARGE) verfügen auch über größere Feedforward-Netzwerke (768 bzw. 1024 versteckte Einheiten) und mehr Aufmerksamkeitsköpfe (12 bzw. 16) als die im Originalpapier vorgeschlagene Transformer-Architektur. Es beinhaltet 512 versteckte Einheiten und 8 Aufmerksamkeitsköpfe .
- BERTBASEenthält 110 Millionen Parameter, während BERTGROSShat 340 Millionen Parameter.

BERT BASE- und BERT LARGE-Architektur.
Dieses Modell übernimmt die CLS Zuerst wird das Token als Eingabe eingegeben, dann folgt eine Folge von Wörtern als Eingabe. Hier ist CLS ein Klassifizierungstoken. Anschließend wird die Eingabe an die oben genannten Ebenen weitergeleitet. Jede Schicht gilt Selbstaufmerksamkeit und leitet das Ergebnis durch ein Feedforward-Netzwerk und übergibt es anschließend an den nächsten Encoder. Das Modell gibt einen Vektor mit versteckter Größe aus ( 768 für BERT BASE). Wenn wir einen Klassifikator aus diesem Modell ausgeben möchten, können wir die Ausgabe entsprechend dem CLS-Token verwenden.
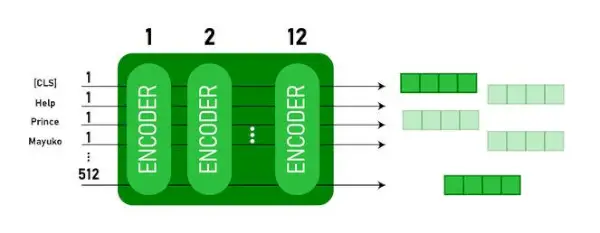
BERT-Ausgabe als Einbettungen
Dieser trainierte Vektor kann nun für eine Reihe von Aufgaben wie Klassifizierung, Übersetzung usw. verwendet werden. Beispielsweise erzielt das Papier allein durch die Verwendung einer einzigen Ebene hervorragende Ergebnisse Neurales Netzwerk auf dem BERT-Modell in der Klassifizierungsaufgabe.
Wie verwende ich das BERT-Modell im NLP?
BERT kann für verschiedene Aufgaben der Verarbeitung natürlicher Sprache (NLP) verwendet werden, wie zum Beispiel:
1. Klassifizierungsaufgabe
- BERT kann beispielsweise für Klassifizierungsaufgaben verwendet werden Stimmungsanalyse Das Ziel besteht darin, den Text in verschiedene Kategorien (positiv/negativ/neutral) zu klassifizieren. BERT kann verwendet werden, indem eine Klassifizierungsebene oben auf der Transformer-Ausgabe für das [CLS]-Token hinzugefügt wird.
- Das [CLS]-Token stellt die aggregierten Informationen aus der gesamten Eingabesequenz dar. Diese gepoolte Darstellung kann dann als Eingabe für eine Klassifizierungsebene verwendet werden, um Vorhersagen für die spezifische Aufgabe zu treffen.
2. Beantwortung von Fragen
- Bei Fragebeantwortungsaufgaben, bei denen das Modell die Antwort innerhalb einer bestimmten Textsequenz lokalisieren und markieren muss, kann BERT für diesen Zweck trainiert werden.
- BERT wird für die Beantwortung von Fragen trainiert, indem es zwei zusätzliche Vektoren lernt, die den Anfang und das Ende der Antwort markieren. Während des Trainings werden dem Modell Fragen und entsprechende Passagen bereitgestellt und es lernt, die Anfangs- und Endpositionen der Antwort innerhalb der Passage vorherzusagen.
3. Named Entity Recognition (NER)
- BERT kann für NER verwendet werden, wo das Ziel darin besteht, Entitäten (z. B. Person, Organisation, Datum) in einer Textsequenz zu identifizieren und zu klassifizieren.
- Ein BERT-basiertes NER-Modell wird trainiert, indem der Ausgabevektor jedes Tokens vom Transformer genommen und in eine Klassifizierungsschicht eingespeist wird. Die Ebene sagt die benannte Entitätsbezeichnung für jedes Token voraus und gibt den Typ der Entität an, die es darstellt.
Wie tokenisiert und kodiert man Text mit BERT?
Um Text mit BERT zu tokenisieren und zu kodieren, verwenden wir die „Transformer“-Bibliothek in Python.
Befehl zum Installieren von Transformatoren:
!pip install transformers>
- Wir werden die vorab trainierte BERT-Tokenisierung mit einem umschlossenen Vokabular laden BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(text) tokenisiert den Eingabetext und wandelt ihn in eine Folge von Token-IDs um.
- print(Token-IDs:, Kodierung) druckt die nach der Kodierung erhaltenen Token-IDs.
- tokenizer.convert_ids_to_tokens(Kodierung) wandelt die Token-IDs zurück in die entsprechenden Token.
- print(Tokens:, tokens) druckt die nach der Konvertierung der Token-IDs erhaltenen Token
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Ausgabe:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> Der tokenizer.encode Methode fügt das Besondere hinzu [CLS] – Klassifizierung Und [SEP] – Trennzeichen Token am Anfang und Ende der codierten Sequenz.
Anwendung von BERT
BERT wird verwendet für:
- Textdarstellung: BERT wird verwendet, um Worteinbettungen oder Darstellungen für Wörter in einem Satz zu generieren.
- Anerkennung benannter Entitäten (NER) : BERT kann für Aufgaben zur Erkennung benannter Entitäten optimiert werden, bei denen das Ziel darin besteht, Entitäten wie Namen von Personen, Organisationen, Standorten usw. in einem bestimmten Text zu identifizieren.
- Textklassifizierung: BERT wird häufig für Textklassifizierungsaufgaben verwendet, einschließlich Stimmungsanalyse, Spam-Erkennung und Themenkategorisierung. Es hat eine hervorragende Leistung beim Verstehen und Klassifizieren des Kontexts von Textdaten gezeigt.
- Frage-Antwort-Systeme: BERT wurde auf Frage-Antwort-Systeme angewendet, bei denen das Modell darauf trainiert wird, den Kontext einer Frage zu verstehen und relevante Antworten bereitzustellen. Dies ist besonders nützlich für Aufgaben wie das Leseverständnis.
- Maschinenübersetzung: Die kontextuellen Einbettungen von BERT können zur Verbesserung maschineller Übersetzungssysteme genutzt werden. Das Modell erfasst die Nuancen der Sprache, die für eine genaue Übersetzung entscheidend sind.
- Textzusammenfassung: BERT kann zur abstrakten Textzusammenfassung verwendet werden, wobei das Modell durch das Verständnis des Kontexts und der Semantik prägnante und aussagekräftige Zusammenfassungen längerer Texte generiert.
- Konversations-KI: BERT wird beim Aufbau von Konversations-KI-Systemen wie Chatbots, virtuellen Assistenten und Dialogsystemen eingesetzt. Seine Fähigkeit, den Kontext zu erfassen, macht es effektiv für das Verstehen und Generieren natürlichsprachlicher Antworten.
- Semantische Ähnlichkeit: BERT-Einbettungen können verwendet werden, um die semantische Ähnlichkeit zwischen Sätzen oder Dokumenten zu messen. Dies ist bei Aufgaben wie der Erkennung von Duplikaten, der Identifizierung von Paraphrasen und dem Abrufen von Informationen von Nutzen.
BERT vs. GPT
Der Unterschied zwischen BERT und GPT ist wie folgt:
| BERT | GPT | |
|---|---|---|
| Die Architektur | BERT ist für bidirektionales Repräsentationslernen konzipiert. Es verwendet ein maskiertes Sprachmodell, bei dem fehlende Wörter in einem Satz basierend auf dem linken und rechten Kontext vorhergesagt werden. | GPT hingegen ist für die generative Sprachmodellierung konzipiert. Es sagt das nächste Wort in einem Satz anhand des vorherigen Kontexts voraus und nutzt dabei einen unidirektionalen autoregressiven Ansatz. |
| Ziele vor dem Training | BERT wird unter Verwendung eines maskierten Sprachmodellziels und der Vorhersage des nächsten Satzes vorab trainiert. Der Schwerpunkt liegt auf der Erfassung des bidirektionalen Kontexts und dem Verständnis der Beziehungen zwischen Wörtern in einem Satz. | GPT ist vorab darauf trainiert, das nächste Wort in einem Satz vorherzusagen, was das Modell dazu ermutigt, eine kohärente Darstellung der Sprache zu lernen und kontextrelevante Sequenzen zu generieren. |
| Kontextverständnis | BERT ist effektiv für Aufgaben, die ein tiefes Verständnis des Kontexts und der Beziehungen innerhalb eines Satzes erfordern, wie z. B. Textklassifizierung, Erkennung benannter Entitäten und Beantwortung von Fragen. | GPT ist stark darin, kohärenten und kontextrelevanten Text zu generieren. Es wird häufig bei kreativen Aufgaben, Dialogsystemen und Aufgaben verwendet, die die Generierung natürlicher Sprachsequenzen erfordern. |
| Aufgabentypen und Anwendungsfälle
| Wird häufig bei Aufgaben wie der Textklassifizierung, der Erkennung benannter Entitäten, der Stimmungsanalyse und der Beantwortung von Fragen verwendet. | Wird auf Aufgaben wie Textgenerierung, Dialogsysteme, Zusammenfassung und kreatives Schreiben angewendet. |
| Feinabstimmung vs. Few-Shot-Lernen | BERT wird oft mit gekennzeichneten Daten auf bestimmte nachgelagerte Aufgaben abgestimmt, um seine vorab trainierten Darstellungen an die jeweilige Aufgabe anzupassen. | GPT ist für das Lernen mit wenigen Schüssen konzipiert, bei dem es mit minimalen aufgabenspezifischen Trainingsdaten auf neue Aufgaben verallgemeinert werden kann. |
Überprüfen Sie auch:
- Stimmungsklassifizierung mit BERT
- Wie generiert man Worteinbettungen mit BERT?
- BART-Modell für die automatische Textvervollständigung in NLP
- Klassifizierung toxischer Kommentare mithilfe von BERT
- Vorhersage des nächsten Satzes mit BERT
Häufig gestellte Fragen (FAQs)
F. Wofür wird BERT verwendet?
BERT wird zur Durchführung von NLP-Aufgaben wie Textdarstellung, Erkennung benannter Entitäten, Textklassifizierung, Frage-und-Antwort-Systeme, maschinelle Übersetzung, Textzusammenfassung und mehr verwendet.
F. Welche Vorteile bietet das BERT-Modell?
Das BERT-Sprachmodell zeichnet sich durch eine umfassende Vorschulung in mehreren Sprachen aus und bietet im Vergleich zu anderen Modellen eine breite sprachliche Abdeckung. Dies macht BERT besonders für nicht englischsprachige Projekte von Vorteil, da es robuste kontextuelle Darstellungen und semantisches Verständnis über eine Vielzahl von Sprachen hinweg bietet und so seine Vielseitigkeit in mehrsprachigen Anwendungen erhöht.
F. Wie funktioniert BERT für die Stimmungsanalyse?
BERT zeichnet sich durch die Stimmungsanalyse aus, indem es sein bidirektionales Repräsentationslernen nutzt, um kontextuelle Nuancen, semantische Bedeutungen und syntaktische Strukturen innerhalb eines bestimmten Textes zu erfassen. Dies ermöglicht es BERT, die in einem Satz ausgedrückte Stimmung zu verstehen, indem es die Beziehungen zwischen Wörtern berücksichtigt, was zu äußerst effektiven Ergebnissen der Stimmungsanalyse führt.
bfs und dfs
F. Basiert Google auf BERT?
BERT Und RankBrain sind Komponenten des Suchalgorithmus von Google, um Suchanfragen und Webseiteninhalte zu verarbeiten, um ein besseres Verständnis zu erlangen und die Suchergebnisse zu verbessern.