Excel-Tabellen sind sehr instinktiv und benutzerfreundlich, was sie ideal für die Bearbeitung großer Datenmengen macht, selbst für weniger technisch versierte Leute. Wenn Sie nach Orten suchen, an denen Sie lernen können, Dinge in Excel-Dateien zu manipulieren und zu automatisieren Python , suchen Sie nicht weiter. Sie sind am richtigen Ort.
In diesem Artikel erfahren Sie, wie Sie es verwenden Pandas um mit Excel-Tabellen zu arbeiten. In diesem Artikel erfahren wir mehr über:
- Lesen Excel-Datei Verwendung von Pandas in Python
- Pandas installieren und importieren
- Lesen mehrerer Excel-Tabellen mit Pandas
- Anwendung verschiedener Pandas-Funktionen
Lesen einer Excel-Datei mit Pandas in Python
Pandas installieren
Um Pandas in Python zu installieren, können wir den folgenden Befehl in der Eingabeaufforderung verwenden:
pip install pandas>
Um Pandas in Anaconda zu installieren, können wir den folgenden Befehl im Anaconda Terminal verwenden:
conda install pandas>
Pandas importieren
Zunächst müssen wir das Pandas-Modul importieren, was durch Ausführen des folgenden Befehls erfolgen kann:
Python3
import> pandas as pd> |
>
>
Eingabedatei: Nehmen wir an, die Excel-Datei sieht so aus
Blatt1:
np.mean

Blatt1
Blatt 2:
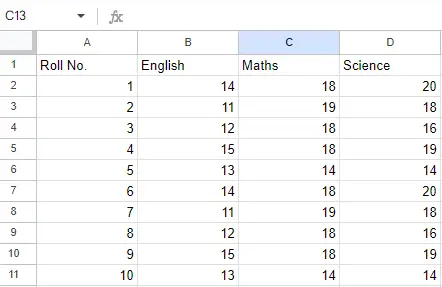
Blatt 2
Jetzt können wir die Excel-Datei mit der Funktion read_excel in Pandas importieren, um die Excel-Datei mit Pandas in Python zu lesen. Die zweite Anweisung liest die Daten aus Excel und speichert sie in einem Pandas-Datenrahmen, der durch die Variable newData dargestellt wird.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Ausgabe:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Laden mehrerer Blätter mit der Concat()-Methode
Wenn die Excel-Arbeitsmappe mehrere Blätter enthält, importiert der Befehl Daten aus dem ersten Blatt. Um einen Datenrahmen mit allen Blättern in der Arbeitsmappe zu erstellen, besteht die einfachste Methode darin, verschiedene Datenrahmen separat zu erstellen und diese dann zu verketten. Die Methode read_excel verwendet die Argumente sheet_name und index_col, wobei wir das Blatt angeben können, aus dem der Rahmen bestehen soll, und index_col die Titelspalte angibt, wie unten gezeigt:
Beispiel:
Die dritte Anweisung verkettet beide Blätter. Um nun den gesamten Datenrahmen zu überprüfen, können wir einfach den folgenden Befehl ausführen:
Python3
Heilwerkzeug Gimp
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Ausgabe:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head()- und Tail()-Methoden in Pandas
Um 5 Spalten vom oberen und unteren Rand des Datenrahmens anzuzeigen, können wir den Befehl ausführen. Das Kopf() Und Schwanz() Die Methode akzeptiert Argumente auch als Zahlen für die Anzahl der anzuzeigenden Spalten.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Ausgabe:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape()-Methode
Der shape()-Methode kann verwendet werden, um die Anzahl der Zeilen und Spalten im Datenrahmen wie folgt anzuzeigen:
Python3
newData.shape> |
>
>
Ausgabe:
(20, 3)>
Sort_values()-Methode in Pandas
Wenn eine Spalte numerische Daten enthält, können wir diese Spalte mithilfe von sortieren sort_values() Methode in Pandas wie folgt:
Python3
Wo finde ich meine Browsereinstellungen?
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Nehmen wir nun an, wir möchten die obersten 5 Werte der sortierten Spalte. Hier können wir die Methode head() verwenden:
Python3
sorted_column.head(>5>)> |
>
>
Ausgabe:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Wir können dies mit jeder numerischen Spalte des Datenrahmens tun, wie unten gezeigt:
Python3
newData[>'Maths'>].head()> |
>
Java-Trimmzeichenfolge
>
Ausgabe:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Describe()-Methode
Angenommen, unsere Daten sind größtenteils numerisch. Mit dem können wir statistische Informationen wie Mittelwert, Maximum, Minimum usw. über den Datenrahmen abrufen beschreiben() Methode wie unten gezeigt:
Python3
newData.describe()> |
>
>
Ausgabe:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Dies kann auch separat für alle numerischen Spalten mit dem folgenden Befehl erfolgen:
Python3
newData[>'English'>].mean()> |
>
>
NP-Polsterung
Ausgabe:
14.3>
Auch andere statistische Informationen können mit den entsprechenden Methoden berechnet werden. Wie in Excel können auch Formeln angewendet und berechnete Spalten wie folgt erstellt werden:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Ausgabe:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Nachdem wir die Daten im Datenrahmen bearbeitet haben, können wir die Daten mit der Methode to_excel zurück in eine Excel-Datei exportieren. Dazu müssen wir eine Excel-Ausgabedatei angeben, in die die transformierten Daten geschrieben werden sollen, wie unten gezeigt:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Ausgabe:
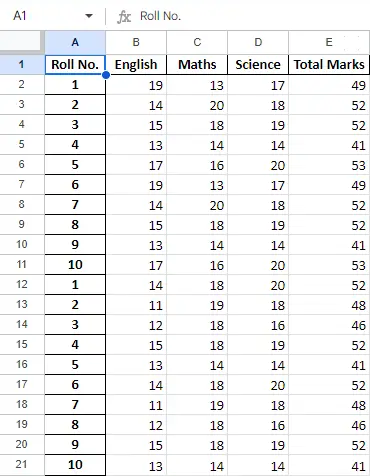
Schlussblatt