Ein wichtiger Aspekt von Maschinelles Lernen ist die Modellbewertung. Sie benötigen einen Mechanismus zur Bewertung Ihres Modells. Hier kommen diese Leistungskennzahlen ins Spiel, sie geben uns einen Eindruck davon, wie gut ein Modell ist. Wenn Sie mit einigen Grundlagen von vertraut sind Maschinelles Lernen Dann müssen Sie auf einige dieser Metriken gestoßen sein, wie Genauigkeit, Präzision, Rückruf, Auc-Roc usw., die im Allgemeinen für Klassifizierungsaufgaben verwendet werden. In diesem Artikel werden wir eine solche Metrik eingehend untersuchen, nämlich die AUC-ROC-Kurve.
Inhaltsverzeichnis
- Was ist die AUC-ROC-Kurve?
- Schlüsselbegriffe, die in der AUC- und ROC-Kurve verwendet werden
- Zusammenhang zwischen Sensitivität, Spezifität, FPR und Schwelle.
- Wie funktioniert AUC-ROC?
- Wann sollten wir die AUC-ROC-Bewertungsmetrik verwenden?
- Spekulationen über die Leistung des Modells
- Die AUC-ROC-Kurve verstehen
- Umsetzung mit zwei unterschiedlichen Modellen
- Wie verwende ich ROC-AUC für ein Mehrklassenmodell?
- FAQs zur AUC-ROC-Kurve im maschinellen Lernen
Was ist die AUC-ROC-Kurve?
Die AUC-ROC-Kurve oder „Area Under the Receiver Operating Characteristic Curve“ ist eine grafische Darstellung der Leistung eines binären Klassifizierungsmodells bei verschiedenen Klassifizierungsschwellenwerten. Beim maschinellen Lernen wird es häufig verwendet, um die Fähigkeit eines Modells zu beurteilen, zwischen zwei Klassen zu unterscheiden, typischerweise der positiven Klasse (z. B. Vorliegen einer Krankheit) und der negativen Klasse (z. B. Fehlen einer Krankheit).
Lassen Sie uns zunächst die Bedeutung der beiden Begriffe verstehen ROC Und AUC .
- ROC : Betriebseigenschaften des Empfängers
- AUC : Fläche unter der Kurve
ROC-Kurve (Receiver Operating Characteristics).
ROC steht für Receiver Operating Characteristics und die ROC-Kurve ist die grafische Darstellung der Wirksamkeit des binären Klassifizierungsmodells. Es stellt die Richtig-Positiv-Rate (TPR) im Vergleich zur Falsch-Positiv-Rate (FPR) bei verschiedenen Klassifizierungsschwellenwerten dar.
Fläche unter der Kurve (AUC) Kurve:
AUC steht für „Area Under the Curve“ und die AUC-Kurve stellt die Fläche unter der ROC-Kurve dar. Es misst die Gesamtleistung des binären Klassifizierungsmodells. Da sowohl TPR als auch FPR zwischen 0 und 1 liegen, liegt der Bereich immer zwischen 0 und 1, und ein größerer AUC-Wert bedeutet eine bessere Modellleistung. Unser Hauptziel besteht darin, diesen Bereich zu maximieren, um den höchsten TPR und den niedrigsten FPR bei dem gegebenen Schwellenwert zu erreichen. Die AUC misst die Wahrscheinlichkeit, dass das Modell einer zufällig ausgewählten positiven Instanz eine höhere vorhergesagte Wahrscheinlichkeit zuweist als einer zufällig ausgewählten negativen Instanz.
Es repräsentiert die Wahrscheinlichkeit mit dem unser Modell zwischen den beiden in unserem Ziel vorhandenen Klassen unterscheiden kann.
ROC-AUC-Klassifizierungsbewertungsmetrik
Schlüsselbegriffe, die in der AUC- und ROC-Kurve verwendet werden
1. TPR und FPR
Dies ist die gebräuchlichste Definition, auf die Sie bei der Google-Suche nach AUC-ROC gestoßen wären. Im Grunde ist die ROC-Kurve ein Diagramm, das die Leistung eines Klassifizierungsmodells bei allen möglichen Schwellenwerten zeigt (der Schwellenwert ist ein bestimmter Wert, ab dem Sie sagen, dass ein Punkt zu einer bestimmten Klasse gehört). Die Kurve wird zwischen zwei Parametern aufgetragen
- TPR – True-Positive-Rate
- FPR – Falsch-Positiv-Rate
Bevor wir TPR und FPR verstehen, schauen wir uns kurz an Verwirrung Matrix .
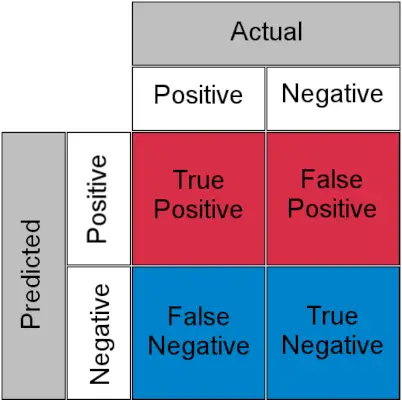
Verwirrungsmatrix für eine Klassifizierungsaufgabe
- Wirklich positiv : Tatsächlich positiv und als positiv vorhergesagt
- Echt negativ : Tatsächlich negativ und als negativ vorhergesagt
- Falsch positiv (Fehler Typ I) : Tatsächlich negativ, aber als positiv vorhergesagt
- Falsch negativ (Typ-II-Fehler) : Tatsächlich positiv, aber als negativ vorhergesagt
In einfachen Worten kann man False Positive als a bezeichnen false alarm und falsch negativ a vermissen . Schauen wir uns nun an, was TPR und FPR sind.
2. Sensitivität / True-Positive-Rate / Rückruf
Im Grunde ist TPR/Recall/Sensitivity das Verhältnis von positiven Beispielen, die korrekt identifiziert wurden. Es stellt die Fähigkeit des Modells dar, positive Instanzen korrekt zu identifizieren und wird wie folgt berechnet:

Sensitivität/Erinnerung/TPR misst den Anteil tatsächlich positiver Instanzen, die vom Modell korrekt als positiv identifiziert werden.
3. Falsch-Positiv-Rate
FPR ist das Verhältnis von Negativbeispielen, die falsch klassifiziert wurden.

4. Spezifität
Die Spezifität misst den Anteil tatsächlich negativer Instanzen, die vom Modell korrekt als negativ identifiziert werden. Es stellt die Fähigkeit des Modells dar, negative Instanzen korrekt zu identifizieren

Und wie bereits erwähnt, ist ROC nichts anderes als das Diagramm zwischen TPR und FPR über alle möglichen Schwellenwerte hinweg, und AUC ist die gesamte Fläche unter dieser ROC-Kurve.
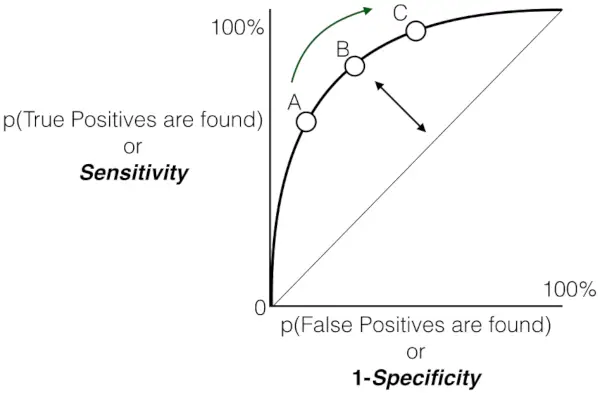
Diagramm der Empfindlichkeit gegenüber der Falsch-Positiv-Rate
Zusammenhang zwischen Sensitivität, Spezifität, FPR und Schwelle .
Sensitivität und Spezifität:
- Inverse Beziehung: Sensitivität und Spezifität stehen in einem umgekehrten Verhältnis. Wenn einer zunimmt, nimmt der andere tendenziell ab. Dies spiegelt den inhärenten Kompromiss zwischen echten positiven und echten negativen Zinssätzen wider.
- Abstimmung über Schwelle: Durch Anpassen des Schwellenwerts können wir das Gleichgewicht zwischen Sensitivität und Spezifität steuern. Niedrigere Schwellenwerte führen zu einer höheren Sensitivität (mehr richtig positive Ergebnisse) auf Kosten der Spezifität (mehr falsch positive Ergebnisse). Umgekehrt erhöht eine Anhebung des Schwellenwerts die Spezifität (weniger falsch-positive Ergebnisse), geht jedoch zu Lasten der Sensitivität (mehr falsch-negative Ergebnisse).
Schwellenwert und Falsch-Positiv-Rate (FPR):
- FPR- und Spezifitätsverbindung: Die Falsch-Positiv-Rate (FPR) ist einfach das Komplement der Spezifität (FPR = 1 – Spezifität). Dies weist auf die direkte Beziehung zwischen ihnen hin: Eine höhere Spezifität führt zu einem niedrigeren FPR und umgekehrt.
- FPR-Änderungen mit TPR: In ähnlicher Weise sind, wie Sie beobachtet haben, auch die True Positive Rate (TPR) und die FPR miteinander verknüpft. Ein Anstieg des TPR (mehr richtig positive Ergebnisse) führt im Allgemeinen zu einem Anstieg des FPR (mehr falsch positive Ergebnisse). Umgekehrt führt ein Rückgang des TPR (weniger echte Positive) zu einem Rückgang des FPR (weniger falsch positive Ergebnisse).
Wie funktioniert AUC-ROC?
Wir haben uns die geometrische Interpretation angeschaut, aber ich denke, sie reicht immer noch nicht aus, um die Intuition zu entwickeln, die dahinter steckt, was 0,75 AUC tatsächlich bedeutet. Schauen wir uns nun AUC-ROC aus probabilistischer Sicht an. Lassen Sie uns zunächst darüber sprechen, was AUC tut, und später werden wir darauf aufbauend unser Verständnis aufbauen
AUC misst, wie gut ein Modell unterscheiden kann Klassen.
Eine AUC von 0,75 würde tatsächlich bedeuten, dass, sagen wir, wir nehmen zwei Datenpunkte, die zu unterschiedlichen Klassen gehören, eine 75-prozentige Chance besteht, dass das Modell sie trennen oder in die richtige Reihenfolge bringen kann, d. h. ein positiver Punkt hat eine höhere Vorhersagewahrscheinlichkeit als ein negativer Klasse. (Unter der Annahme einer höheren Vorhersagewahrscheinlichkeit würde der Punkt idealerweise zur positiven Klasse gehören). Hier ist ein kleines Beispiel, um die Sache klarer zu machen.
Index | Klasse | Wahrscheinlichkeit |
|---|---|---|
P1 | 1 | 0,95 Natasha Dalal |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Hier haben wir 6 Punkte, bei denen P1, P2 und P5 zur Klasse 1 und P3, P4 und P6 zur Klasse 0 gehören, und wir haben die entsprechenden vorhergesagten Wahrscheinlichkeiten in der Spalte „Wahrscheinlichkeit“, wie wir sagten, wenn wir zwei zugehörige Punkte zum Trennen nehmen Wie hoch ist dann die Wahrscheinlichkeit, dass der Modellrang sie richtig ordnet?
Wir nehmen alle möglichen Paare, sodass ein Punkt zur Klasse 1 und der andere zur Klasse 0 gehört. Wir werden insgesamt 9 solcher Paare haben. Unten sind alle diese 9 möglichen Paare aufgeführt.
Paar | ist richtig |
|---|---|
(P1,P3) | Ja |
(P1,P4) | Ja |
(P1,P6) | Ja |
(P2,P3) | Ja |
(P2,P4) | Ja |
(P2,P6) | Ja |
(P3,P5) | NEIN |
(P4,P5) | NEIN |
(P5,P6) | Ja |
Hier gibt die Spalte „Korrekt“ an, ob das erwähnte Paar basierend auf der vorhergesagten Wahrscheinlichkeit korrekt nach Rang geordnet ist, d. h. der Punkt der Klasse 1 hat eine höhere Wahrscheinlichkeit als der Punkt der Klasse 0, in 7 dieser 9 möglichen Paare hat Klasse 1 einen höheren Rang als Klasse 0, oder Wir können sagen, dass eine Wahrscheinlichkeit von 77 % besteht, dass das Modell, wenn Sie ein Punktepaar auswählen, das zu verschiedenen Klassen gehört, diese korrekt unterscheiden kann. Nun, ich denke, Sie haben vielleicht ein wenig Intuition hinter dieser AUC-Zahl. Um weitere Zweifel auszuräumen, validieren wir sie mithilfe von Scikit, das die AUC-ROC-Implementierung erlernt.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Ausgabe:
AUC for our sample data is 0.778>
Wann sollten wir die AUC-ROC-Bewertungsmetrik verwenden?
Es gibt einige Bereiche, in denen der Einsatz von ROC-AUC möglicherweise nicht ideal ist. In Fällen, in denen der Datensatz stark unausgeglichen ist, Die ROC-Kurve kann eine zu optimistische Einschätzung der Modellleistung liefern . Diese Tendenz zum Optimismus entsteht, weil die Falsch-Positiv-Rate (FPR) der ROC-Kurve sehr klein werden kann, wenn die Anzahl der tatsächlich negativen Ergebnisse groß ist.
Betrachtet man die FPR-Formel,

Wir beobachten ,
- Die Negativklasse ist in der Mehrheit, der Nenner von FPR wird von echten Negativen dominiert, wodurch FPR weniger empfindlich auf Änderungen in Vorhersagen im Zusammenhang mit der Minderheitsklasse (Positivklasse) reagiert.
- ROC-Kurven können geeignet sein, wenn die Kosten für falsch-positive und falsch-negative Ergebnisse ausgeglichen sind und der Datensatz nicht stark unausgeglichen ist.
In solchen Fällen Präzisionsrückrufkurven können verwendet werden, die eine alternative Bewertungsmetrik bereitstellen, die besser für unausgeglichene Datensätze geeignet ist und sich auf die Leistung des Klassifikators in Bezug auf die positive Klasse (Minderheitsklasse) konzentriert.
Spekulationen über die Leistung des Modells
- Eine hohe AUC (nahe 1) weist auf eine ausgezeichnete Unterscheidungskraft hin. Dies bedeutet, dass das Modell effektiv zwischen den beiden Klassen unterscheiden kann und seine Vorhersagen zuverlässig sind.
- Eine niedrige AUC (nahe 0) deutet auf eine schlechte Leistung hin. In diesem Fall fällt es dem Modell schwer, zwischen den positiven und negativen Klassen zu unterscheiden, und seine Vorhersagen sind möglicherweise nicht vertrauenswürdig.
- Eine AUC um 0,5 impliziert, dass das Modell im Wesentlichen zufällige Vermutungen anstellt. Es zeigt keine Möglichkeit, die Klassen zu trennen, was darauf hindeutet, dass das Modell keine aussagekräftigen Muster aus den Daten lernt.
Die AUC-ROC-Kurve verstehen
In einer ROC-Kurve stellt die x-Achse typischerweise die Falsch-Positiv-Rate (FPR) und die y-Achse die Richtig-Positiv-Rate (TPR) dar, auch bekannt als Sensitivität oder Recall. Ein höherer X-Achsenwert (nach rechts) auf der ROC-Kurve weist also auf eine höhere Falsch-Positiv-Rate hin, und ein höherer Y-Achsen-Wert (nach oben) weist auf eine höhere Richtig-Positiv-Rate hin. Die ROC-Kurve ist grafisch Darstellung des Kompromisses zwischen der Rate richtig positiver Ergebnisse und der Rate falsch positiver Ergebnisse bei verschiedenen Schwellenwerten. Es zeigt die Leistung eines Klassifizierungsmodells bei verschiedenen Klassifizierungsschwellenwerten. Die AUC (Fläche unter der Kurve) ist ein zusammenfassendes Maß für die Leistung der ROC-Kurve. Die Wahl des Schwellenwerts hängt von den spezifischen Anforderungen des Problems ab, das Sie lösen möchten, und dem Kompromiss zwischen falsch positiven und falsch negativen Ergebnissen in Ihrem Kontext akzeptabel.
- Wenn Sie der Reduzierung von Falsch-Positiv-Ergebnissen Priorität einräumen möchten (also die Wahrscheinlichkeit minimieren, etwas als positiv zu kennzeichnen, obwohl dies nicht der Fall ist), können Sie einen Schwellenwert wählen, der zu einer niedrigeren Falsch-Positiv-Rate führt.
- Wenn Sie der Erhöhung der True-Positives-Rate Priorität einräumen möchten (so viele tatsächliche Positive wie möglich erfassen), können Sie einen Schwellenwert wählen, der zu einer höheren True-Positive-Rate führt.
Betrachten wir ein Beispiel, um zu veranschaulichen, wie ROC-Kurven für verschiedene generiert werden Schwellenwerte und wie ein bestimmter Schwellenwert einer Verwirrungsmatrix entspricht. Angenommen, wir haben eine binäres Klassifizierungsproblem mit einem Modell, das vorhersagt, ob es sich bei einer E-Mail um Spam (positiv) handelt oder nicht (negativ).
Betrachten wir die hypothetischen Daten,
Echte Beschriftungen: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Vorhergesagte Wahrscheinlichkeiten: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Fall 1: Schwelle = 0,5
Wahre Etiketten | Vorhergesagte Wahrscheinlichkeiten | Vorhergesagte Beschriftungen |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 Java-String-Formatierung | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwirrungsmatrix basierend auf den obigen Vorhersagen
| Vorhersage = 0 | Vorhersage = 1 |
|---|---|---|
Tatsächlich = 0 | TP=4 | FN=1 |
Tatsächlich = 1 | FP=0 | TN=5 |
Entsprechend,
- True-Positive-Rate (TPR) :
Der Anteil der tatsächlich positiven Ergebnisse, die vom Klassifikator korrekt identifiziert wurden, ist

- Falsch-Positiv-Rate (FPR) :
Anteil tatsächlicher Negative, die fälschlicherweise als Positive klassifiziert wurden



Also, bei der Schwelle von 0,5:
- True-Positive-Rate (Empfindlichkeit): 0,8
- Falsch-Positiv-Rate: 0
Die Interpretation ist, dass das Modell bei diesem Schwellenwert 80 % der tatsächlich positiven Ergebnisse (TPR) korrekt identifiziert, jedoch 0 % der tatsächlich negativen Ergebnisse fälschlicherweise als positive Ergebnisse (FPR) klassifiziert.
Dementsprechend erhalten wir für verschiedene Schwellenwerte:
Fall 2: Schwelle = 0,7
Wahre Etiketten | Vorhergesagte Wahrscheinlichkeiten | Vorhergesagte Beschriftungen |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Verwirrungsmatrix basierend auf den obigen Vorhersagen
| Vorhersage = 0 | Vorhersage = 1 |
|---|---|---|
Tatsächlich = 0 | TP=5 | FN=0 |
Tatsächlich = 1 | FP=2 | TN=3 |
Entsprechend,
- True-Positive-Rate (TPR) :
Der Anteil der tatsächlich positiven Ergebnisse, die vom Klassifikator korrekt identifiziert wurden, ist

- Falsch-Positiv-Rate (FPR) :
Anteil tatsächlicher Negative, die fälschlicherweise als Positive klassifiziert wurden



Fall 3: Schwelle = 0,4
Wahre Etiketten | Vorhergesagte Wahrscheinlichkeiten | Vorhergesagte Beschriftungen |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 in Java eingestellt | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwirrungsmatrix basierend auf den obigen Vorhersagen
| Vorhersage = 0 | Vorhersage = 1 |
|---|---|---|
Tatsächlich = 0 | TP=4 | FN=1 |
Tatsächlich = 1 | FP=0 | TN=5 |
Entsprechend,
- True-Positive-Rate (TPR) :
Der Anteil der tatsächlich positiven Ergebnisse, die vom Klassifikator korrekt identifiziert wurden, ist
- Falsch-Positiv-Rate (FPR) :
Anteil tatsächlicher Negative, die fälschlicherweise als Positive klassifiziert wurden
Fall 4: Schwelle = 0,2
Wahre Etiketten | Vorhergesagte Wahrscheinlichkeiten | Vorhergesagte Beschriftungen |
|---|---|---|
| 1 | 0,8 | 1 Quicksort-Algorithmus |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Verwirrungsmatrix basierend auf den obigen Vorhersagen
| Vorhersage = 0 | Vorhersage = 1 |
|---|---|---|
Tatsächlich = 0 | TP=2 | FN=3 |
Tatsächlich = 1 | FP=0 | TN=5 |
Entsprechend,
- True-Positive-Rate (TPR) :
Der Anteil der tatsächlich positiven Ergebnisse, die vom Klassifikator korrekt identifiziert wurden, ist

- Falsch-Positiv-Rate (FPR) :
Anteil tatsächlicher Negative, die fälschlicherweise als Positive klassifiziert wurden

Fall 5: Schwelle = 0,85
Wahre Etiketten | Vorhergesagte Wahrscheinlichkeiten | Vorhergesagte Beschriftungen |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Verwirrungsmatrix basierend auf den obigen Vorhersagen
| Vorhersage = 0 | Vorhersage = 1 |
|---|---|---|
Tatsächlich = 0 | TP=5 | FN=0 |
Tatsächlich = 1 | FP=4 | TN=1 |
Entsprechend,
- True-Positive-Rate (TPR) :
Der Anteil der tatsächlich positiven Ergebnisse, die vom Klassifikator korrekt identifiziert wurden, ist
- Falsch-Positiv-Rate (FPR) :
Anteil tatsächlicher Negative, die fälschlicherweise als Positive klassifiziert wurden


Basierend auf dem obigen Ergebnis zeichnen wir die ROC-Kurve
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Ausgabe:
Aus der Grafik geht hervor, dass:
- Die graue gestrichelte Linie stellt das Worst-Case-Szenario dar, bei dem die Vorhersagen des Modells, d. h. TPR und FPR, gleich sind. Diese diagonale Linie gilt als Worst-Case-Szenario und weist darauf hin, dass die Wahrscheinlichkeit von falsch-positiven und falsch-negativen Ergebnissen gleich groß ist.
- Wenn Punkte von der zufälligen Schätzlinie in Richtung der oberen linken Ecke abweichen, verbessert sich die Leistung des Modells.
- Die Fläche unter der Kurve (AUC) ist ein quantitatives Maß für die Unterscheidungsfähigkeit des Modells. Ein höherer AUC-Wert, näher bei 1,0, weist auf eine bessere Leistung hin. Der bestmögliche AUC-Wert beträgt 1,0, was einem Modell entspricht, das 100 % Sensitivität und 100 % Spezifität erreicht.
Insgesamt dient die Receiver Operating Characteristic (ROC)-Kurve als grafische Darstellung des Kompromisses zwischen der True-Positive-Rate (Sensitivität) und der False-Positive-Rate eines binären Klassifizierungsmodells bei verschiedenen Entscheidungsschwellenwerten. Da die Kurve elegant zur oberen linken Ecke ansteigt, ist dies ein Zeichen für die lobenswerte Fähigkeit des Modells, über einen Bereich von Konfidenzschwellen hinweg zwischen positiven und negativen Fällen zu unterscheiden. Dieser Aufwärtstrend weist auf eine verbesserte Leistung hin, wobei eine höhere Empfindlichkeit erreicht und gleichzeitig Fehlalarme minimiert werden. Die mit Anmerkungen versehenen Schwellenwerte, die als A, B, C, D und E bezeichnet werden, bieten wertvolle Einblicke in das dynamische Verhalten des Modells bei verschiedenen Konfidenzniveaus.
Umsetzung mit zwei unterschiedlichen Modellen
Bibliotheken installieren
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Um das zu trainieren Zufälliger Wald Und Logistische Regression Um Modelle zu analysieren und ihre ROC-Kurven mit AUC-Scores darzustellen, erstellt der Algorithmus künstliche binäre Klassifizierungsdaten.
Generieren von Daten und Aufteilen von Daten
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Mithilfe eines Aufteilungsverhältnisses von 80:20 erstellt der Algorithmus künstliche binäre Klassifizierungsdaten mit 20 Merkmalen, unterteilt sie in Trainings- und Testsätze und weist einen zufälligen Startwert zu, um die Reproduzierbarkeit sicherzustellen.
Training der verschiedenen Modelle
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Unter Verwendung eines festen Zufallsstartwerts zur Sicherstellung der Wiederholbarkeit initialisiert und trainiert die Methode ein logistisches Regressionsmodell auf dem Trainingssatz. Auf ähnliche Weise werden die Trainingsdaten und derselbe Zufallsstartwert verwendet, um ein Random Forest-Modell mit 100 Bäumen zu initialisieren und zu trainieren.
Vorhersagen
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Unter Verwendung der Testdaten und eines geschulten Logistische Regression Modell sagt der Code die Wahrscheinlichkeit der positiven Klasse voraus. Auf ähnliche Weise wird unter Verwendung der Testdaten das trainierte Random-Forest-Modell verwendet, um projizierte Wahrscheinlichkeiten für die positive Klasse zu erstellen.
Erstellen eines Datenrahmens
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Mithilfe der Testdaten erstellt der Code einen DataFrame namens test_df mit den Spalten „True“, „Logistic“ und „RandomForest“ und fügt „True“-Beschriftungen und vorhergesagte Wahrscheinlichkeiten aus den Modellen „Random Forest“ und „Logistic Regression“ hinzu.
Zeichnen Sie die ROC-Kurve für die Modelle
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Ausgabe:

Der Code generiert einen Plot mit 8 x 6 Zoll großen Figuren. Es berechnet die AUC- und ROC-Kurve für jedes Modell (Random Forest und Logistic Regression) und zeichnet dann die ROC-Kurve auf. Der ROC-Kurve für zufälliges Raten wird ebenfalls durch eine rote gestrichelte Linie dargestellt, und zur Visualisierung sind Beschriftungen, ein Titel und eine Legende festgelegt.
Wie verwende ich ROC-AUC für ein Mehrklassenmodell?
Für eine Umgebung mit mehreren Klassen können wir einfach die Methode „Eins vs. alle“ verwenden und Sie erhalten eine ROC-Kurve für jede Klasse. Nehmen wir an, Sie haben vier Klassen A, B, C und D, dann gäbe es ROC-Kurven und entsprechende AUC-Werte für alle vier Klassen, d. h. einmal wäre A eine Klasse und B, C und D zusammen wären die anderen Klassen Ebenso ist B eine Klasse und A, C und D zusammen als andere Klassen usw.
Die allgemeinen Schritte zur Verwendung von AUC-ROC im Kontext eines Klassifizierungsmodells mit mehreren Klassen sind:
Eine-gegen-Alle-Methodik:
- Behandeln Sie jede Klasse in Ihrem Mehrklassenproblem als positive Klasse, während Sie alle anderen Klassen zur negativen Klasse zusammenfassen.
- Trainieren Sie den binären Klassifikator für jede Klasse im Vergleich zu den übrigen Klassen.
Berechnen Sie AUC-ROC für jede Klasse:
- Hier zeichnen wir die ROC-Kurve für die gegebene Klasse im Vergleich zum Rest auf.
- Zeichnen Sie die ROC-Kurven für jede Klasse in demselben Diagramm auf. Jede Kurve stellt die Unterscheidungsleistung des Modells für eine bestimmte Klasse dar.
- Untersuchen Sie die AUC-Werte für jede Klasse. Ein höherer AUC-Wert weist auf eine bessere Unterscheidung für diese bestimmte Klasse hin.
Implementierung von AUC-ROC in der Multiklassenklassifizierung
Bibliotheken importieren
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Das Programm erstellt künstliche Multiklassendaten, unterteilt sie in Trainings- und Testsätze und verwendet sie dann Eins-gegen-Rest-Klassifikator Technik zum Trainieren von Klassifikatoren sowohl für Random Forest als auch für logistische Regression. Abschließend werden die Mehrklassen-ROC-Kurven der beiden Modelle dargestellt, um zu zeigen, wie gut sie zwischen verschiedenen Klassen unterscheiden können.
Daten generieren und aufteilen
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Drei Klassen und zwanzig Features bilden die vom Code erzeugten synthetischen Mehrklassendaten. Nach der Etikettenbinarisierung werden die Daten im Verhältnis 80:20 in Trainings- und Testsätze aufgeteilt.
Trainingsmodelle
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Das Programm trainiert zwei Mehrklassenmodelle: ein Random-Forest-Modell mit 100 Schätzern und ein logistisches Regressionsmodell mit One-vs-Rest-Ansatz . Mit dem Trainingsdatensatz werden beide Modelle angepasst.
Zeichnen der AUC-ROC-Kurve
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Ausgabe:

Die ROC-Kurven und AUC-Werte der Random-Forest- und Logistic-Regression-Modelle werden durch den Code für jede Klasse berechnet. Anschließend werden die Mehrklassen-ROC-Kurven aufgezeichnet, die die Unterscheidungsleistung jeder Klasse zeigen und eine Linie enthalten, die zufällige Schätzungen darstellt. Das resultierende Diagramm bietet eine grafische Auswertung der Klassifizierungsleistung der Modelle.
Abschluss
Beim maschinellen Lernen wird die Leistung binärer Klassifizierungsmodelle anhand einer entscheidenden Metrik namens Area Under the Receiver Operating Characteristic (AUC-ROC) bewertet. Über verschiedene Entscheidungsschwellen hinweg wird gezeigt, wie Sensitivität und Spezifität gegeneinander abgewogen werden. Eine größere Unterscheidung zwischen positiven und negativen Fällen weist typischerweise ein Modell mit einem höheren AUC-Wert auf. Während 0,5 Zufall bedeutet, steht 1 für einwandfreie Leistung. Die Modelloptimierung und -auswahl wird durch die nützlichen Informationen unterstützt, die die AUC-ROC-Kurve über die Fähigkeit eines Modells zur Unterscheidung zwischen Klassen bietet. Bei der Arbeit mit unausgeglichenen Datensätzen oder Anwendungen, bei denen falsch-positive und falsch-negative Ergebnisse unterschiedliche Kosten verursachen, ist dies als umfassende Maßnahme besonders nützlich.
FAQs zur AUC-ROC-Kurve im maschinellen Lernen
1. Was ist die AUC-ROC-Kurve?
js-Ersatz
Für verschiedene Klassifizierungsschwellenwerte wird der Kompromiss zwischen der Rate richtig positiver Ergebnisse (Sensitivität) und der Rate falsch positiver Ergebnisse (Spezifität) grafisch durch die AUC-ROC-Kurve dargestellt.
2. Wie sieht eine perfekte AUC-ROC-Kurve aus?
Eine Fläche von 1 auf einer idealen AUC-ROC-Kurve würde bedeuten, dass das Modell bei allen Schwellenwerten optimale Sensitivität und Spezifität erreicht.
3. Was bedeutet ein AUC-Wert von 0,5?
Eine AUC von 0,5 zeigt an, dass die Leistung des Modells mit der des Zufallsgenerators vergleichbar ist. Es deutet auf einen Mangel an Unterscheidungsfähigkeit hin.
4. Kann AUC-ROC für die Klassifizierung mehrerer Klassen verwendet werden?
AUC-ROC wird häufig bei Problemen mit binärer Klassifizierung angewendet. Bei der Multiklassenklassifizierung können Variationen wie die makrodurchschnittliche oder mikrodurchschnittliche AUC berücksichtigt werden.
5. Wie ist die AUC-ROC-Kurve bei der Modellbewertung nützlich?
Die Fähigkeit eines Modells, zwischen Klassen zu unterscheiden, wird durch die AUC-ROC-Kurve umfassend zusammengefasst. Dies ist besonders hilfreich, wenn mit unausgeglichenen Datensätzen gearbeitet wird.