Pandas dataframe.corr() wird verwendet, um die paarweise Korrelation aller Spalten im Pandas-Datenrahmen in Python zu ermitteln. Beliebig NaN Werte werden automatisch ausgeschlossen. Um alle nicht numerischen Werte zu ignorieren, verwenden Sie den Parameter numeric_only = True. In diesem Artikel lernen wir die Methode DataFrame.corr() kennen Python .
Syntax der Pandas DataFrame corr()-Methode
Syntax: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Parameter:
- Methode :
- Pearson: Standardkorrelationskoeffizient
- kendall: Kendall Tau-Korrelationskoeffizient
- Spearman: Spearman-Rangkorrelation
- min_periods: Mindestanzahl an Beobachtungen, die pro Spaltenpaar erforderlich sind, um ein gültiges Ergebnis zu erhalten. Derzeit nur für Pearson- und Spearman-Korrelation verfügbar
- numeric_only: Ob nur die numerischen Werte bearbeitet werden sollen oder nicht. Standardmäßig ist es auf „False“ gesetzt.
Kehrt zurück: count :y : DataFrame
Pandas Data Correlations corr()-Methode
Eine gute Korrelation hängt von der Verwendung ab, aber man kann mit Sicherheit sagen, dass man mindestens 0,6 (oder -0,6) hat, um von einer guten Korrelation zu sprechen. Ein einfaches Beispiel, um zu zeigen, wie Korrelation funktioniert Python .
Python3
Java math.random
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Ausgabe
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Beispieldatenrahmen erstellen
Drucken der ersten 10 Zeilen des Datenrahmens.
Notiz: Die Korrelation einer Variablen mit sich selbst beträgt 1. Für einen Link zur im Code verwendeten CSV-Datei klicken Sie auf Hier
Python3
Gray-Code
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Wie groß ist mein Computerbildschirm?
Ausgabe

Beispiele für die Python Pandas DataFrame corr()-Methode
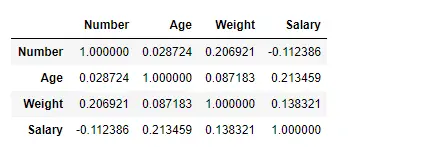
Finden Sie die Korrelation zwischen den Spalten mithilfe der Pearson-Methode
Hier verwenden wir die Funktion corr(), um die Korrelation zwischen den Spalten im Datenrahmen mithilfe der „Pearson“-Methode zu ermitteln. Wir haben nur vier numerische Spalten im Datenrahmen. Der Ausgabedatenrahmen kann so interpretiert werden, dass für jede Zelle die Korrelation der Zeilenvariablen mit der Spaltenvariablen den Wert der Zelle darstellt. Wie bereits erwähnt, beträgt die Korrelation einer Variablen mit sich selbst 1. Aus diesem Grund sind alle Diagonalwerte 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Ausgabe
for-Schleife im Shell-Skript
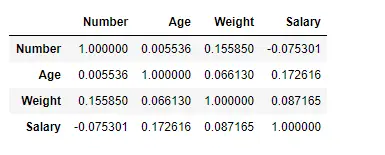
Finden Sie die Korrelation zwischen den Spalten mithilfe der Kendall-Methode
Verwenden Sie die Funktion df.corr() von Panda, um die Korrelation zwischen den Spalten im Datenrahmen mithilfe der Methode „kendall“ zu ermitteln. Der Ausgabedatenrahmen kann so interpretiert werden, dass für jede Zelle die Korrelation der Zeilenvariablen mit der Spaltenvariablen den Wert der Zelle darstellt. Wie bereits erwähnt, beträgt die Korrelation einer Variablen mit sich selbst 1. Aus diesem Grund sind alle Diagonalwerte 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Ausgabe
Versandhandel-Traversal-Binärbaum